摘要
HashMap的原理也是大廠面試中經常會涉及的問題,同時也是工作中常用到的Java容器,本文主要通過對以下問題進行分析講解,來幫助大家理解HashMap的原理。
1.HashMap添加一個鍵值對的過程是怎麼樣的?
2.為什麼說HashMap不是線程安全的?
3.為什麼要一起重寫hashCode()和equal()方法?
HashMap添加一個鍵值對的過程是怎麼樣的?
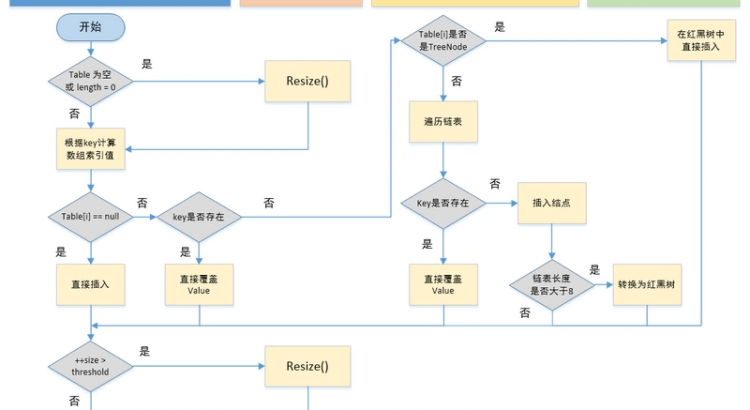
這是網上找的一張流程圖,可以結合著步驟來看這個流程圖,了解添加鍵值對的過程。
1.初始化table
判斷table是否為空或為null,否則執行resize()方法(resize方法一般是擴容時調用,也可以調用來初始化table)。
2.計算hash值
根據鍵值key計算hash值。(因為hashCode是一個int類型的變量,是4字節,32位,所以這裡會將hashCode的低16位與高16位進行一個異或運算,來保留高位的特徵,以便於得到的hash值更加均勻分佈)
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
3.插入或更新節點
根據(n – 1) & hash計算得到插入的數組下標i,然後進行判斷
table[i]==null
那麼說明當前數組下標下,沒有hash衝突的元素,直接新建節點添加。
table[i].hash == hash &&(table[i]== key || (key != null && key.equals(table[i].key)))
判斷table[i]的首個元素是否和key一樣,如果相同直接更新value。
table[i] instanceof TreeNode
判斷table[i] 是否為treeNode,即table[i] 是否是紅黑樹,如果是紅黑樹,則直接在樹中插入鍵值對。
其他情況
上面的判斷條件都不滿足,說明table[i]存儲的是一個鏈表,那麼遍歷鏈表,判斷是否存在已有元素的key與插入鍵值對的key相等,如果是,那麼更新value,如果沒有,那麼在鏈表末尾插入一個新節點。插入之後判斷鏈表長度是否大於8,大於8的話把鏈錶轉換為紅黑樹。
4.擴容
插入成功后,判斷實際存在的鍵值對數量size是否超多了最大容量threshold(一般是數組長度*負載因子0.75),如果超過,進行擴容。
源代碼如下:
2.為什麼說HashMap不是線程安全的?
其實通過學習HashMap添加鍵值對的方法,我們可以看到整個方法內都沒有使用到鎖,所以一旦多線併發訪問,就有可能造成數據不一致的問題,
例如:
如果有兩個添加鍵值對的線程都執行到if ((tab = table) == null || (n = tab.length) == 0)這行語句,都對table變量進行數組初始化,就會造成已經初始化好的數組table被覆蓋,然後前面初始化的線程會將鍵值對添加到之前初始化的數組中去,造成鍵值對丟失。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// tab為空則創建
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
...後面的代碼省略
}
3.為什麼要一起重寫hashCode()和equal()方法?
當我們的對象一旦作為HashMap中的key,或者是HashSet中的元素使用時,就必須同時重寫hashCode()和equal()方法
首先看看hashCode()和equal()方法的默認實現
可以看到Obejct類中的源碼如下,可以看到equals()方法的默認實現是判斷兩個對象的內存地址是否相同來決定返回結果。
public native int hashCode();
public boolean equals(Object obj) {
return (this == obj);
}
網上很多博客說hashCode的默認實現是返回內存地址,其實不對,以OpenJDK為例,hashCode的默認計算方法有5種,有返回隨機數的,有返回內存地址,具體採用哪一種計算方法取決於運行時庫和JVM的具體實現。
感興趣的朋友可以看看這篇博客
https://blog.csdn.net/xusiwei1236/article/details/45152201
然後看看hashCode()方法,equal()方法在HashMap中的應用
static final int hash(Object key) {
int h;
//因為hashCode是一個int類型的變量,是4字節,32位,所以這裡會將hashCode的低16位與高16位進行一個異或運算,來保留高位的特徵,以便於得到的hash值更加均勻分佈
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
為了將一組鍵值對均勻得存儲在一個數組中,HashMap對key的hashCode進行計算得到一個hash值,用hash對數組長度取模,得到數組下標,將鍵值對存儲在數組下標對應的鏈表下(假設鏈表長度小於8,沒有達到轉換為紅黑樹的閥值)。
下面是添加鍵值對的putVal()方法,當數組下標對應的是一個鏈表時執行的代碼
//遍歷鏈表
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {//已經遍歷到鏈表末尾,說明鏈表不存在這個key
p.next = newNode(hash, key, value, null);//在末尾添加這個鍵值對
if (binCount >= TREEIFY_THRESHOLD - 1) //超過鏈錶轉化為紅黑樹的閥值(也急速鏈表長度》=8)
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
可以清楚地看到判斷添加的key與鏈表中已存在的key是否相等的方法主要是e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))),
也就是:
1.先判斷hash值是否相等,不相等直接結束判斷,因為hash值不相等,key肯定不相等。
2.判斷兩個key對象的內存地址是否相等(相等指向內存中同一個對象)。
3.key不為null,調用key的equal()方法判斷是否相等,因為有可能兩個key在內存中存儲的地址不一樣,但是是相等的。
就像是
String a = new String("test");
String b = new String("test");
System.out.println("a==b is "+a==b);//打印為false
System.out.println("a.equals(b) is "+a.equals(b));//打印為true
背景
假設我們有一個KeyObject類,假設我們認為兩個KeyObject的屬性a相等,那麼KeyObject就是相等的相等的,我們將KeyObject作為HashMap的key,以KeyObject是否相等作為去重標準,不能重複添加KeyObject相等,value不等的值到HashMap中去
public static class KeyObject {
Integer a;
public KeyObject(Integer a) {
this.a = a;
}
}
假設都hashCode()方法和equals()方法都不重寫(結果:HashMap無法保證去重)
執行以下代碼:
public static void main(String[] args) {
KeyObject key1 = new KeyObject(1);
KeyObject key2 = new KeyObject(1);
System.out.println("key1的hashCode為"+ key1.hashCode());
System.out.println("key2的hashCode為" + key2.hashCode());
System.out.println("key1.equals(key2)的結果為"+(key1.equals(key2)));
HashMap<KeyObject,String> hashMap = new HashMap<KeyObject,String>();
hashMap.put(key1,"value1");
hashMap.put(key2,"value2");
//打印hashMap
for(KeyObject key :hashMap.keySet()){
System.out.println("KeyObject.a="+key.a+" : "+hashMap.get(key));
}
}
如果KeyObject的hashCode()方法和equals()方法都不重寫,那麼即便KeyObject的屬性a都是1,key1和key2的hashCode都是不相同的,key1和key2調用equals()方法也不相等,這樣hashMap中就可以同時存在key1和key2了。
打印結果:
key1的hashCode為728890494
key2的hashCode為1558600329
key1.equals(key2)的結果為false
KeyObject.a=1 : value1
KeyObject.a=1 : value2
假如只重寫hashCode()方法(結果:無法正確地與鏈表元素進行相等判斷,從而無法保證去重)
執行以下代碼:
public static class KeyObject {
Integer a;
public KeyObject(Integer a) {
this.a = a;
}
@Override
public int hashCode() {
return a;
}
public static void main(String[] args) {
KeyObject key1 = new KeyObject(1);
KeyObject key2 = new KeyObject(1);
System.out.println("key1的hashCode為"+ key1.hashCode());
System.out.println("key2的hashCode為" + key2.hashCode());
System.out.println("key1.equals(key2)的結果為"+(key1.equals(key2)));
HashMap<KeyObject,String> hashMap = new HashMap<KeyObject,String>();
hashMap.put(key1,"value1");
hashMap.put(key2,"value2");
for(KeyObject key :hashMap.keySet()){
System.out.println("TestObject.a="+key.a+" : "+hashMap.get(key));
}
}
}
此時equal()方法的實現是默認實現,也就是當兩個對象的內存地址相等時,equal()方法才返回true,雖然key1和key2的a屬性是相同的,但是他們在內存中是不同的對象,所以key1==key2結果會是false,KeyObject的equals()方法默認實現是判斷兩個對象的內存地址,所以 key1.equals(key2)也會是false,所以這兩個鍵值對可以重複地添加到hashMap中去。
輸出結果:
key1的hashCode為1
key2的hashCode為1
key1.equals(key2)的結果為false
TestObject.a=1 : value1
TestObject.a=1 : value2
假如只重寫equals()方法(結果:映射到HashMap中不同數組下標,無法保證去重)
public static class KeyObject {
Integer a;
public KeyObject(Integer a) {
this.a = a;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
KeyObject keyObject = (KeyObject) o;
return Objects.equals(a, keyObject.a);
}
public static void main(String[] args) {
KeyObject key1 = new KeyObject(1);
KeyObject key2 = new KeyObject(1);
System.out.println("key1的hashCode為"+ key1.hashCode());
System.out.println("key2的hashCode為" + key2.hashCode());
System.out.println("key1.equals(key2)的結果為"+(key1.equals(key2)));
HashMap<KeyObject,String> hashMap = new HashMap<KeyObject,String>();
hashMap.put(key1,"value1");
hashMap.put(key2,"value2");
for(KeyObject key :hashMap.keySet()){
System.out.println("TestObject.a="+key.a+" : "+hashMap.get(key));
}
}
}
假設只equals()方法,hashCode方法會是默認實現,具體的計算方法取決於JVM,(測試時發現是內存地址不同但是相等的對象,它們的hashCode不相同),所以計算得到的數組下標不相同,會存儲到hashMap中不同數組下標下的鏈表中,也會導致HashMap中存在重複元素。
輸出結果如下:
key1的hashCode為1289479439
key2的hashCode為6738746
key1.equals(key2)的結果為true
TestObject.a=1 : value1
TestObject.a=1 : value2
總結
所以當我們的對象一旦作為HashMap中的key,或者是HashSet中的元素使用時,就必須同時重寫hashCode()和equal()方法,因為hashCode會影響key存儲的數組下標及與鏈表元素的初步判斷,equal()是作為判斷key與鏈表中的key是否相等的最後標準。
- 所以只重寫hashCode()方法,會導致無法正確地與鏈表元素進行相等判斷,從而無法保證去重)
- 只重寫equals()方法導致鍵值對映射到HashMap中不同數組下標,無法保證去重
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準