環境資訊中心綜合外電;姜唯 編譯;林大利 審校
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※超省錢租車方案
※別再煩惱如何寫文案,掌握八大原則!
※回頭車貨運收費標準
※教你寫出一流的銷售文案?
※FB行銷專家,教你從零開始的技巧
| |
經濟參考報報導,中國產自佛山(雲浮)產業轉移工業園的氫能燃料電池汽車,在今年《北京國際風能與中國太陽能大會暨展覽會》上,吸引眾多人的圍觀。在展期間舉行的「氫產業•氫生活•氫未來」主題新聞發布會上,業內人士認為,氫能早已過了概念性的階段,預計三到五年時間內,氫能產業即會進入爆發期。 中國科技部部長萬鋼日前在第十九屆中國科協年會上也表示,氫具來源廣泛、大規模穩定儲存、持續供應、遠距離運輸以及快速補充等特點,在未來車用能源中,氫燃料與電力將並存互補,共同支撐新能源汽車產業發展;且必須加強協同創新,加快推動氫能燃料電池產業全面發展。 目前,中國各地也都在積極推動燃料電池發展。今年9月上海發布《上海市燃料電池汽車發展規畫》,規劃到2020年,上海將會聚集超過100家燃料電池汽車相關企業,於2025年建成50座加氫站,到2030年實現燃料電池汽車技術和製造整體達到海外同等水準,上海燃料電池汽車全產業鏈年產值突破3,000億元人民幣。 而上述來自佛山產業轉移工業園的氫能燃料電池汽車,則包含氫能乘用車、氫燃料電池城市客車以及燃料電池物流車等多款車型。同時,2016年5月,廣東國鴻氫能科技與加拿大巴拉德簽署引進9SSL電堆生產線技術協定,在中國建設年生產兩萬台電堆和5,000套系統的首條商業化燃料電池電堆及系統整合生產線,該項目已於今年7月1日正式投產,首批試製電堆樣品主要性能指標達到國際先進水準,計畫今年生產3000台9SSL電堆,系統整合1,000套。 佛山市委常委許國也認為,現在氫能產業發展最大的障礙不是技術而是基礎設施建設。不過,預計後續加氫站的建設在中國會取得突飛猛進的效果,中國央企尤其是中石化正在對中國的加油站合建加氫站的問題進行全面布局。 中國全國氫能標準技術委員會高級顧問陳霖新認為,氫能早已過了概念性的階段,現在要進入踏踏實實發展的階段。許國則判斷,中國國家政策還是以示範為主,未來產業技術好的區域自然能搶佔先機,取得更多的市場份額,預計在未來三到五年時間內,即2020年左右,氫能產業會取得突飛猛進的發展,而這個爆發點只會提前不會推遲。 (本文內容由授權使用。首圖來源:by pixelfreestyle via Flickr CC2.0)
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準

 |
石油輸出國組織(OPEC)11月7日發布「世界石油展望(WOO)」報告指出,假設全球電動車(EV)年度銷售量在2040年達到8千萬輛(相當於每5台車就有3台是電動車),在電動車滲透率高於預期的情況下、全球石油日需求量可能會在2040年較基準預估值減少250萬桶至1.08億桶。據此推斷,全球石油需求將在2030年代下半階段持平於這個水位。 WOO指出,2016年全球上路的電動車據估計已升至200萬輛。目前已有6個國家的電動車市佔率(占整體轎車銷售量比重)突破1%、挪威電動車銷售量佔比更是高達29%。不過,電動車目前僅佔全球整體轎車車隊不到0.2%的比例。 WOO預估(見圖),2040年電動車在經濟合作暨發展組織(OECD)美洲新車市場的銷售佔比將高達35%左右、屆時中國電動車銷售佔比預估也將逼近29%,印度預估將達18%。 根據DNV GL首度發布的「能源轉型展望」報告,受電動車滲透率持續上揚的影響,石油供應將在2020~2028年期間轉趨持平、隨後大幅下降,2034年將遭天然氣超越。這份報告預估電動車、內燃引擎車將在2022年達到「成本平價」,預估到2033年全球半數輕型新車銷售量都將是電動車。 Thomson Reuters報導,嘉能可(Glencore)董事長Tony Hayward 5月受訪時表示,電動車的快速進步意味著石油需求可能會在2040年以前觸頂,深海鑽油、加拿大油砂等高成本原油生產商恐將先被淘汰出局,擁有生產成本優勢的OPEC相對較不受衝擊。Hayward曾任英國石油公司(BP Plc)執行長。 英國金融時報8月報導,瑞銀(UBS)預估2021年歐洲未經補貼的純電動車整體持有成本將與傳統內燃機汽車相當、中國也可望在2025年達到這項里程碑。 (本文內容由授權使用。首圖來源:public domain CC0)
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※教你寫出一流的銷售文案?
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※回頭車貨運收費標準
※別再煩惱如何寫文案,掌握八大原則!
※超省錢租車方案
※產品缺大量曝光嗎?你需要的是一流包裝設計!

 |
電動車製造商 Tesla 向媒體發出邀請函,定於 2017 年 11 月 16 日召開產品發表會,推出電動半掛卡車,儘管 Tesla 的無人駕駛部門還深陷與 Waymo 的訴訟中,也無礙 Elon Musk 進軍電動卡車市場的決心。 Tesla 的電動半掛卡車曾在測試中亮相,此次發表會將是這款產品首次對外公開展示,Tesla 的卡車業務是該公司在乘用車之外全新的產品線,之前並沒有太多信息曝光。Tesla 原定於 2017 年 10 月發表半掛卡車,由於 Tesla 投入了大量的資源和人力參與波多黎各的救災活動,導致新品發表一再延期。 德國汽車廠商 Daimler 已經推出了大載重的電動運輸卡車,單次充電的行駛里程約為 220 英里,據傳 Tesla 的半掛卡車單次充電的行駛里程大約為 200 英里到 300 英里,考慮到卡車載重所需的牽引力,電動卡車需要配置大容量的電池系統。 近日 Tesla 電池部門的主管 Jon Wagner 被爆已經從該公司離職,他在 2013 年 1 月加入 Tesla,參與了所有電動車的研發,還負責了 Tesla 的家用儲能裝置 Powerwall,核心高層的離職也讓外界對於 Tesla 的量產能力產生了更多質疑,Tesla 已經將 Model 3 量產目標延後 3 個月,制約產能的主要因素是內華達州的超級工廠電池模組生產線產能不足,導致不得不調整 Model 3 的部分生產環節。目前 Tesla 已經接收了超過 50 萬台 Model 3 訂單,但 2017 年第三季 Model 3 只生產了 260 台。 Tesla 執行長 Elon Musk 透露,在卡車的設計過程中與物流運輸公司展開合作,他們的參與有助於產品能夠更好地為物流產業服務,電動卡車新品主要是面向中短途路線設計,比如將貨物從城市中心區運輸到港口等,比使用燃油卡車運輸成本更低。此外 Tesla 半掛卡車還可能加入無人駕駛功能,該公司已經與美國車輛管理局就無人駕駛道路測試進行溝通。 Tesla 的無人駕駛領域還面臨的另一個挑戰就是與 Waymo 的官司,這起官司正是由於 Tesla 收購了無人駕駛卡車新創公司 Otto,該公司的創辦人是 Google 無人駕駛部門的前員工,離職時違規下載了許多機密商業文件,Alphabet 旗下無人駕駛公司 Waymo 認為 Tesla 竊取了商業機密並應用到無人駕駛的開發中,目前這起訴訟仍在庭審中。 (合作媒體:。首圖來源:public domain CC0)
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※超省錢租車方案
※別再煩惱如何寫文案,掌握八大原則!
※回頭車貨運收費標準
※教你寫出一流的銷售文案?
※FB行銷專家,教你從零開始的技巧

 |
川普本周亞洲行來到中國,中方頻頻讓利討川普歡心。11月9日在習近平與川普的一場會談上,中國宣布訪寬外資對新能源車的持股限制,美國電動車龍頭特斯拉有望受惠。 中國目前限制外資持有合資公司的股份不得超過50%。但從明年六月起,設點在指定自貿區的電動車或其它類型的新能源車合資公司,外資持股比例將可超過五成門檻。 有意深耕中國市場的特斯拉,可能成為政策鬆綁下的潛在受惠者。華爾街日報日前報導指出,特斯拉擬赴上海設廠,且已與中國政府達成協議,雙方只差細節與宣布時間還未敲定,可能正在等待新政策發布。 另外,福特、安徽眾泰汽車(Anhui Zotye Automobile Co.)11月8日在川普的見證下,宣布兩公司將合資7.56億美元,在中國打造動車廠,雙方持股比為50:50。 (本文內容由授權使用。首圖來源:public domain CC0)
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準
※聚甘新

目錄
上一篇文章我們講到了JVM為了提升解釋的性能,引入了JIT編譯器,今天我們再來從整體的角度,帶小師妹看看JDK14中的JVM有哪些優化的方面,並且能夠從中間得到那些啟發。
更多精彩內容且看:
小師妹:F師兄,上次你給我講的JIT真的是受益匪淺,原來JVM中還有這麼多不為人知的小故事。不知道除了JIT之外,JVM還有沒有其他的性能提升的姿勢呢?
姿勢當然有很多種,先講一下之前提到過的,在JDK9中引入的字符串壓縮。
在JDK9之前,String的底層存儲結構是char[],一個char需要佔用兩個字節的存儲單位。
因為大部分的String都是以Latin-1字符編碼來表示的,只需要一個字節存儲就夠了,兩個字節完全是浪費。
於是在JDK9之後,字符串的底層存儲變成了byte[]。
目前String支持兩種編碼格式LATIN1和UTF16。
LATIN1需要用一個字節來存儲。而UTF16需要使用2個字節或者4個字節來存儲。
在JDK9中,字符串壓縮是默認開啟的。你可以使用
-XX:-CompactStrings
來控制它。
為了提升JIT的編譯效率,並且滿足不同層次的編譯需求,引入了分層編譯的概念。
大概來說分層編譯可以分為三層:
在JDK7中,你可以使用下面的命令來開啟分層編譯:
-XX:+TieredCompilation
而在JDK8之後,恭喜你,分層編譯已經是默認的選項了,不用再手動開啟。
Code Cache就是用來存儲編譯過的機器碼的內存空間。也就說JIT編譯產生的機器碼,都是存放在Code Cache中的。
Code Cache是以單個heap形式組織起來的連續的內存空間。
如果只是用一個code heap,或多或少的就會引起性能問題。為了提升code cache的利用效率,JVM引入了Code Cache分層技術。
分層技術是什麼意思呢?
就是把不同類型的機器碼分門別類的放好,優點嘛就是方便JVM掃描查找,減少了緩存的碎片,從而提升了效率。
下面是Code Cache的三種分層:
之前的文章我們介紹JIT編譯器,講的是JIT編譯器是用C/C++來編寫的。
而新版的Graal JIT編譯器則是用java來編寫的。對的,你沒看錯,使用java編寫的JIT編譯器。
有沒有一種雞生蛋,蛋生雞的感覺?不過,這都不重要,重要的是Graal真的可以提升JIT的編譯性能。
Graal是和JDK一起發行的,作為一個內部的模塊:jdk.internal.vm.compiler。
Graal和JVM是通過JVMCI(JVM Compiler Interface)來進行通信的。其中JVMCI也是一個內部的模塊:jdk.internal.vm.ci。
注意,Graal只在Linux-64版的JVM中支持,你需要使用 -XX:+UnlockExperimentalVMOptions -XX:+UseJVMCICompiler 來開啟Graal特性。
我們知道在JIT中,通常為了找到熱點代碼,JVM是需要等待代碼執行一定的時間之後,才開始進行本地代碼的編譯。這樣做的缺點就是需要比較長的時間。
同樣的,如果是重複的代碼,沒有被編譯成為機器碼,那麼對性能就會有影響。
而AOT(Ahead-of-time)就厲害了,看名字就知道是提前編譯的意思,根本就不需要等待,而是在JVM啟動之前就開始編譯了。
AOT提供了一個java tool,名字叫做jaotc。显示jaotc的命令格式:
jaotc <options> <list of classes or jar files>
jaotc <options> <--module name>
比如,我們可以這樣提前編譯AOT庫,以供在後面的JVM中使用:
jaotc --output libHelloWorld.so HelloWorld.class
jaotc --output libjava.base.so --module java.base
上面代碼提前編譯了HelloWorld和它的依賴module java.base。
然後我們可以在啟動HelloWorld的時候,指定對應的lib:
java -XX:AOTLibrary=./libHelloWorld.so,./libjava.base.so HelloWorld
這樣在JVM啟動的時候,就回去找相應的AOTLibrary。
注意,AOT是一個 Linux-x64上面的體驗功能。
對象指針用來指向一個對象,表示對該對象的引用。通常來說在64位機子上面,一個指針佔用64位,也就是8個字節。而在32位機子上面,一個指針佔用32位,也就是4個字節。
實時上,在應用程序中,這種對象的指針是非常非常多的,從而導致如果同樣一個程序,在32位機子上面運行和在64位機子上面運行佔用的內存是完全不同的。64位機子內存使用可能是32位機子的1.5倍。
而壓縮對象指針,就是指把64位的指針壓縮到32位。
怎麼壓縮呢?64位機子的對象地址仍然是64位的。壓縮過的32位存的只是相對於heap base address的位移。
我們使用64位的heap base地址+ 32位的地址位移量,就得到了實際的64位heap地址。
對象指針壓縮在Java SE 6u23 默認開啟。在此之前,可以使用-XX:+UseCompressedOops來開啟。
剛剛講到了壓縮過的32位地址是基於64位的heap base地址的。而在Zero-Based 壓縮指針中,64位的heap base地址是重新分配的虛擬地址0。這樣就可以不用存儲64位的heap base地址了。
最後,要講的是逃逸分析。什麼叫逃逸分析呢?簡單點講就是分析這個線程中的對象,有沒有可能會被其他對象或者線程所訪問,如果有的話,那麼這個對象應該在Heap中分配,這樣才能讓對其他的對象可見。
如果沒有其他的對象訪問,那麼完全可以在stack中分配這個對象,棧上分配肯定比堆上分配要快,因為不用考慮同步的問題。
我們舉個例子:
public static void main(String[] args) {
example();
}
public static void example() {
Foo foo = new Foo(); //alloc
Bar bar = new Bar(); //alloc
bar.setFoo(foo);
}
}
class Foo {}
class Bar {
private Foo foo;
public void setFoo(Foo foo) {
this.foo = foo;
}
}
上面的例子中,setFoo引用了foo對象,如果bar對象是在heap中分配的話,那麼引用的foo對象就逃逸了,也需要被分配在heap空間中。
但是因為bar和foo對象都只是在example方法中調用的,所以,JVM可以分析出來沒有其他的對象需要引用他們,那麼直接在example的方法棧中分配這兩個對象即可。
逃逸分析還有一個作用就是lock coarsening。
為了在多線程環境中保證資源的有序訪問,JVM引入了鎖的概念,雖然鎖可以保證多線程的有序執行,但是如果實在單線程環境中呢?是不是還需要一直使用鎖呢?
比如下面的例子:
public String getNames() {
Vector<String> v = new Vector<>();
v.add("Me");
v.add("You");
v.add("Her");
return v.toString();
}
Vector是一個同步對象,如果是在單線程環境中,這個同步鎖是沒有意義的,因此在JDK6之後,鎖只在被需要的時候才會使用。
這樣就能提升程序的執行效率。
本文作者:flydean程序那些事
本文鏈接:http://www.flydean.com/jvm-performance-enhancements/
本文來源:flydean的博客
歡迎關注我的公眾號:程序那些事,更多精彩等着您!
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準
※聚甘新
線程(Thread)是併發編程的基礎,也是程序執行的最小單元,它依託進程而存在。
一個進程中可以包含多個線程,多線程可以共享一塊內存空間和一組系統資源,因此線程之間的切換更加節省資源、更加輕量化,也因此被稱為輕量級的進程。
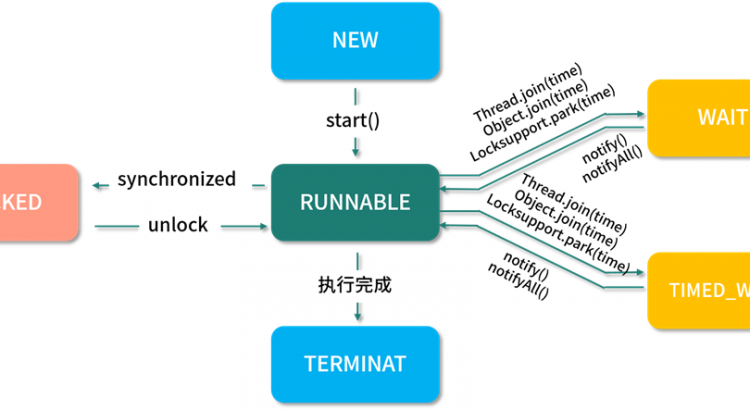
線程的狀態在 JDK 1.5 之後以枚舉的方式被定義在 Thread 的源碼中,它總共包含以下 6 個狀態:
NEW,新建狀態,線程被創建出來,但尚未啟動時的線程狀態;
RUNNABLE,就緒狀態,表示可以運行的線程狀態,它可能正在運行,或者是在排隊等待操作系統給它分配 CPU 資源;
BLOCKED,阻塞等待鎖的線程狀態,表示處於阻塞狀態的線程正在等待監視器鎖,比如等待執行 synchronized 代碼塊或者使用 synchronized 標記的方法;
WAITING,等待狀態,一個處於等待狀態的線程正在等待另一個線程執行某個特定的動作,比如,一個線程調用了 Object.wait() 方法,那它就在等待另一個線程調用 Object.notify() 或 Object.notifyAll() 方法;
TIMED_WAITING,計時等待狀態,和等待狀態(WAITING)類似,它只是多了超時時間,比如調用了有超時時間設置的方法 Object.wait(long timeout) 和 Thread.join(long timeout) 等這些方法時,它才會進入此狀態;
TERMINATED,終止狀態,表示線程已經執行完成。
線程狀態的源代碼如下:
|
public enum State { /** * 新建狀態,線程被創建出來,但尚未啟動時的線程狀態 */ NEW,
/** * 就緒狀態,表示可以運行的線程狀態,但它在排隊等待來自操作系統的 CPU 資源 */ RUNNABLE,
/** * 阻塞等待鎖的線程狀態,表示正在處於阻塞狀態的線程 * 正在等待監視器鎖,比如等待執行 synchronized 代碼塊或者 * 使用 synchronized 標記的方法 */ BLOCKED,
/** * 等待狀態,一個處於等待狀態的線程正在等待另一個線程執行某個特定的動作。 * 例如,一個線程調用了 Object.wait() 它在等待另一個線程調用 * Object.notify() 或 Object.notifyAll() */ WAITING,
/** * 計時等待狀態,和等待狀態 (WAITING) 類似,只是多了超時時間,比如 * 調用了有超時時間設置的方法 Object.wait(long timeout) 和 * Thread.join(long timeout) 就會進入此狀態 */ TIMED_WAITING,
/** * 終止狀態,表示線程已經執行完成 */ } |
線程的工作模式是,首先先要創建線程並指定線程需要執行的業務方法,然後再調用線程的 start() 方法,此時線程就從 NEW(新建)狀態變成了 RUNNABLE(就緒)狀態;
然後線程會判斷要執行的方法中有沒有 synchronized 同步代碼塊,如果有並且其他線程也在使用此鎖,那麼線程就會變為 BLOCKED(阻塞等待)狀態,當其他線程使用完此鎖之後,線程會繼續執行剩餘的方法。
當遇到 Object.wait() 或 Thread.join() 方法時,線程會變為 WAITING(等待狀態)狀態;
如果是帶了超時時間的等待方法,那麼線程會進入 TIMED_WAITING(計時等待)狀態;
當有其他線程執行了 notify() 或 notifyAll() 方法之後,線程被喚醒繼續執行剩餘的業務方法,直到方法執行完成為止,此時整個線程的流程就執行完了,執行流程如下圖所示:
【BLOCKED 和 WAITING 的區別】
雖然 BLOCKED 和 WAITING 都有等待的含義,但二者有着本質的區別。
首先它們狀態形成的調用方法不同。
其次 BLOCKED 可以理解為當前線程還處於活躍狀態,只是在阻塞等待其他線程使用完某個鎖資源;
而 WAITING 則是因為自身調用了 Object.wait() 或着是 Thread.join() 又或者是 LockSupport.park() 而進入等待狀態,只能等待其他線程執行某個特定的動作才能被繼續喚醒。
比如當線程因為調用了 Object.wait() 而進入 WAITING 狀態之後,則需要等待另一個線程執行 Object.notify() 或 Object.notifyAll() 才能被喚醒。
【start() 和 run() 的區別】
首先從 Thread 源碼來看,start() 方法屬於 Thread 自身的方法,並且使用了 synchronized 來保證線程安全,源碼如下:
|
public synchronized void start() { // 狀態驗證,不等於 NEW 的狀態會拋出異常 if (threadStatus != 0) throw new IllegalThreadStateException(); // 通知線程組,此線程即將啟動
group.add(this); boolean started = false; try { start0(); started = true; } finally { try { if (!started) { group.threadStartFailed(this); } } catch (Throwable ignore) { // 不處理任何異常,如果 start0 拋出異常,則它將被傳遞到調用堆棧上 } } } |
run() 方法為 Runnable 的抽象方法,必須由調用類重寫此方法,重寫的 run() 方法其實就是此線程要執行的業務方法,源碼如下:
|
public class Thread implements Runnable { // 忽略其他方法…… private Runnable target; @Override public void run() { if (target != null) { target.run(); } } } @FunctionalInterface public interface Runnable { public abstract void run(); } |
從執行的效果來說,start() 方法可以開啟多線程,讓線程從 NEW 狀態轉換成 RUNNABLE 狀態,而 run() 方法只是一個普通的方法。
其次,它們可調用的次數不同,start() 方法不能被多次調用,否則會拋出 java.lang.IllegalStateException;而 run() 方法可以進行多次調用,因為它只是一個普通的方法而已。
【線程優先級】
在 Thread 源碼中和線程優先級相關的屬性有 3 個:
|
// 線程可以擁有的最小優先級 public final static int MIN_PRIORITY = 1;
// 線程默認優先級 public final static int NORM_PRIORITY = 5;
// 線程可以擁有的最大優先級 public final static int MAX_PRIORITY = 10 |
線程的優先級可以理解為線程搶佔 CPU 時間片的概率,優先級越高的線程優先執行的概率就越大,但並不能保證優先級高的線程一定先執行。
在程序中我們可以通過 Thread.setPriority() 來設置優先級,setPriority() 源碼如下:
|
public final void setPriority(int newPriority) { ThreadGroup g; checkAccess(); // 先驗證優先級的合理性 if (newPriority > MAX_PRIORITY || newPriority < MIN_PRIORITY) { throw new IllegalArgumentException(); } if((g = getThreadGroup()) != null) { // 優先級如果超過線程組的最高優先級,則把優先級設置為線程組的最高優先級 if (newPriority > g.getMaxPriority()) { newPriority = g.getMaxPriority(); } setPriority0(priority = newPriority); } } |
【線程的常用方法】
線程的常用方法有以下幾個。
join()
在一個線程中調用 other.join() ,這時候當前線程會讓出執行權給 other 線程,直到 other 線程執行完或者過了超時時間之後再繼續執行當前線程,join() 源碼如下:
|
public final synchronized void join(long millis) throws InterruptedException { long base = System.currentTimeMillis(); long now = 0; // 超時時間不能小於 0 if (millis < 0) { throw new IllegalArgumentException(“timeout value is negative”); } // 等於 0 表示無限等待,直到線程執行完為之 if (millis == 0) { // 判斷子線程 (其他線程) 為活躍線程,則一直等待 while (isAlive()) { wait(0); } } else { // 循環判斷 while (isAlive()) { long delay = millis – now; if (delay <= 0) { break; } wait(delay); now = System.currentTimeMillis() – base; } } } |
從源碼中可以看出 join() 方法底層還是通過 wait() 方法來實現的。
例如,在未使用 join() 時,代碼如下:
|
public class ThreadExample { public static void main(String[] args) throws InterruptedException { Thread thread = new Thread(() -> { for (int i = 1; i < 6; i++) { try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(“子線程睡眠:“ + i + “秒。“); } }); thread.start(); // 開啟線程 // 主線程執行 for (int i = 1; i < 4; i++) { try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(“主線程睡眠:“ + i + “秒。“); } } } |
程序執行結果為:
複製主線程睡眠:1秒。
子線程睡眠:1秒。
主線程睡眠:2秒。
子線程睡眠:2秒。
主線程睡眠:3秒。
子線程睡眠:3秒。
子線程睡眠:4秒。
子線程睡眠:5秒。
從結果可以看出,在未使用 join() 時主子線程會交替執行。
然後我們再把 join() 方法加入到代碼中,代碼如下:
|
public class ThreadExample { public static void main(String[] args) throws InterruptedException { Thread thread = new Thread(() -> { for (int i = 1; i < 6; i++) { try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(“子線程睡眠:“ + i + “秒。“); } }); thread.start(); // 開啟線程 thread.join(2000); // 等待子線程先執行 2 秒鐘 // 主線程執行 for (int i = 1; i < 4; i++) { try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(“主線程睡眠:“ + i + “秒。“); } } } |
程序執行結果為:
複製子線程睡眠:1秒。
子線程睡眠:2秒。
主線程睡眠:1秒。
// thread.join(2000); 等待 2 秒之後,主線程和子線程再交替執行
子線程睡眠:3秒。
主線程睡眠:2秒。
子線程睡眠:4秒。
子線程睡眠:5秒。
主線程睡眠:3秒。
從執行結果可以看出,添加 join() 方法之後,主線程會先等子線程執行 2 秒之後才繼續執行。
yield()
看 Thread 的源碼可以知道 yield() 為本地方法,也就是說 yield() 是由 C 或 C++ 實現的,源碼如下:
|
public static native void yield(); |
yield() 方法表示給線程調度器一個當前線程願意出讓 CPU 使用權的暗示,但是線程調度器可能會忽略這個暗示。
比如我們執行這段包含了 yield() 方法的代碼,如下所示:
|
public static void main(String[] args) throws InterruptedException { Runnable runnable = new Runnable() { @Override public void run() { for (int i = 0; i < 10; i++) { System.out.println(“線程:“ + Thread.currentThread().getName() + “ I:“ + i); if (i == 5) { Thread.yield(); } } } }; Thread t1 = new Thread(runnable, “T1”); Thread t2 = new Thread(runnable, “T2”); t1.start(); t2.start(); } |
當我們把這段代碼執行多次之後會發現,每次執行的結果都不相同,這是因為 yield() 執行非常不穩定,線程調度器不一定會採納 yield() 出讓 CPU 使用權的建議,從而導致了這樣的結果。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※教你寫出一流的銷售文案?
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※回頭車貨運收費標準
※別再煩惱如何寫文案,掌握八大原則!
※超省錢租車方案
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※聚甘新
事件循環(Event Loop),是每個JS開發者都會接觸到的概念,但是剛接觸時可能會存在各種疑惑。
眾所周知,JS是單線程的,即同一時間只能運行一個任務。一般情況下這不會引發問題,但是如果我們有一個耗時較多的任務,我們必須等該任務執行完畢才能進入下一個任務,然而等待的這段時間常常讓我們無法忍受,因為我們這段時間什麼都不能做,包括頁面也是鎖死狀態。
好在,時代在進步,瀏覽器向我們提供了JS引擎不具備的特性:Web API。Web API包括DOM API、定時器、HTTP請求等特性,可以幫助我們實現異步、非阻塞的行為。我們可以通過異步執行任務的方法來解決單線程的弊端,事件循環為此而生。
提問QAQ:為什麼JavaScript是單線程的?
多個線程表示您可以同時獨立執行程序的多個部分。確定一種語言是單線程還是多線程的最簡單方法是看它擁有有多少個調用堆棧。JS 只有一個,所以它是單線程語言。
將JS設計為單線程是由其用途運行環境等因素決定的,作為瀏覽器腳本語言,JS的主要用途是與用戶互動,以及操作DOM。這決定了它只能是單線程,否則會帶來很複雜的同步問題。同時,單線程執行效率高。
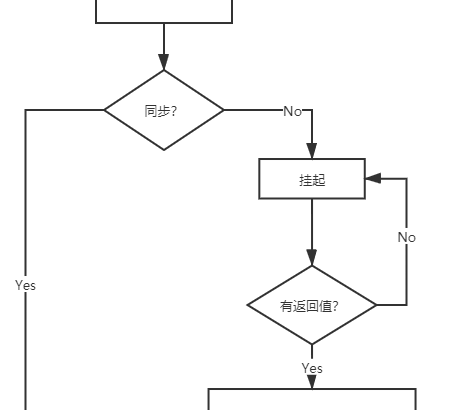
大家熟悉的關於事件循環的機制說法大概是:主進程執行完了之後,每次從任務隊列里取一個任務執行。如圖所示,所有的任務分為同步任務和異步任務,同步任務直接進入任務隊列–>主程序執行;異步任務則會掛起,等待其有返回值時進入任務隊列從而被主程序執行。異步任務會通過任務隊列的機制(先進先出的機制)來進行協調。具體如圖所示:
同步和異步任務分別進入不同的執行環境,同步的進入主線程,即主執行棧,異步的進入任務隊列。主線程內的任務執行完畢為空,會去任務隊列讀取對應的任務,推入主線程執行。 上述過程的不斷重複就是我們所熟悉的Event Loop (事件循環)。但是promise出現之後,這個說法就不太準確了。
這裏首先用一張圖展示JavaScript的事件循環:
直接看這張圖,可能黑人問號已經出現在同學的腦海。。。
這裏將task分為兩大類,分別是macroTask(宏任務)和microTask(微任務).一次事件循環:先運行macroTask隊列中的一個,然後運行microTask隊列中的所有任務。接着開始下一次循環(只是針對macroTask和microTask,一次完整的事件循環會比這個複雜的多)。
那什麼是macroTask?什麼是microTask呢?
JavaScript引擎把我們的所有任務分門別類,一部分歸為macroTask,另外一部分歸為microTack,下面是類別劃分:
macroTask:
microTask:
我們所熟悉的定時器就屬於macroTask,僅僅了解macroTask的機制還是不夠的。為直觀感受兩種隊列的區別,下面上代碼進行實踐感知。
以setTimeout、process.nextTick、promise為例直觀感受下兩種任務隊列的運行方式。
console.log('main1');
process.nextTick(function() {
console.log('process.nextTick1');
});
setTimeout(function() {
console.log('setTimeout');
process.nextTick(function() {
console.log('process.nextTick2');
});
}, 0);
new Promise(function(resolve, reject) {
console.log('promise');
resolve();
}).then(function() {
console.log('promise then');
});
console.log('main2');
別著急看答案,先以上面的理論自己想想,運行結果會是啥?
最終結果是這樣的:
main1
promise
main2
process.nextTick1
promise then
// 第二次事件循環
setTimeout
process.nextTick2
process.nextTick 和 promise then在 setTimeout 前面輸出,已經證明了macroTask和microTask的執行順序。但是有一點必須要指出的是。上面的圖容易給人一個錯覺,就是主進程的代碼執行之後,會先調用macroTask,再調用microTask,這樣在第一個循環里一定是macroTask在前,microTask在後。
但是最終的實踐證明:在第一個循環里,process.nextTick1和promise then這兩個microTask是在setTimeout這個macroTask里之前輸出的,這是因為Promises/A+規範規定主進程的代碼也屬於macroTask。
主進程這個macroTask(也就是main1、promise和main2)執行完了,自然會去執行process.nextTick1和promise then這兩個microTask。這是第一個循環。之後的setTimeout和process.nextTick2屬於第二個循環
別看上面那段代碼好像特別繞,把原理弄清楚了,都一樣 ~
requestAnimationFrame、Object.observe(已廢棄) 和 MutationObserver這三個任務的運行機制大家可以從上面看到,不同的只是具體用法不同。重點說下UI rendering。在HTML規範:event-loop-processing-model里敘述了一次事件循環的處理過程,在處理了macroTask和microTask之後,會進行一次Update the rendering,其中細節比較多,總的來說會進行一次UI的重新渲染。
總而言之,記住一次事件循環:先運行macroTask隊列中的一個,然後運行microTask隊列中的所有任務。接着開始下一次循環。
參考文獻:
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※超省錢租車方案
※別再煩惱如何寫文案,掌握八大原則!
※回頭車貨運收費標準
※教你寫出一流的銷售文案?
※FB行銷專家,教你從零開始的技巧
※聚甘新

只有光頭才能變強。
文本已收錄至我的GitHub精選文章,歡迎Star:https://github.com/ZhongFuCheng3y/3y
之前遇到過很多同學私信問我:「三歪,我馬上要實習了,我要在實習前學些什麼做準備啊?」
三歪在實習之前也同樣問過自己當時的部門老大。
如果再給我一次機會,我會先去花點時間去學學Git。
Git我相信大家對它應該不陌生吧?但凡用過GitHub的同學應該多多少少都會了解一下Git
不知道當時大家學Git的時候是看哪個教程的,我看的是廖雪峰老師的Git系列的。
(別看到廖雪峰就以為是廣告了啊,哈哈哈哈,這篇純原創分享)
剛實習的時候,一直都忙着看各種東西。有一天,我學長說:我看你也學了一些基礎了,我們來看看公司的代碼吧,看看我們生產環境是怎麼做的。
於是我學長丟了一個Git鏈接給三歪
https://github.com/ZhongFuCheng3y/3y.git
那三歪做了什麼?三歪去IDEA下把這個Git給Clone下來:
我用Clone完了以後,我學長又補了一句:這個項目不是用master分支的哦,你切換一下分支。
三歪:啥?切換分支?咋整?我忘了。
我學長看了下我,貌似不咋會切換分支,就說:“我來吧”。
於是在命令行終端一頓操作后,對三歪說:“好了”
三歪:“我對Git不是很熟悉,之前一直都是在IDEA上操作的。你們一般用命令行多還是圖形界面的多呀?”
我學長:“這沒什麼,反正工具這東西,學學就行,不是什麼大問題。也沒必要說很仔細去學它,就工具嘛”
三歪:“嗯”
時間飛逝,又過了一段時間…
三歪被分配了一個需求,於是就需要新建分支去做這個需求了。所有的標準應用線上走的是master分支,公司通過一個發布系統來控制發布版本、以及整套上下線的流程。
於是我要先在發布系統裡邊新建Git分支:
完了以後,我就在IDEA界面上選擇那個被我新建完的分支
但發現我死活找不到…於是我就問我學長:我在發布系統裡邊新建了分支,為什麼在IDEA上找不到啊?
學長:“怎麼會呢,我看看”。
找了一會,他問我:“你fetch 過了嗎?”
三歪:“啥?”
於是他拿着我的電腦,打開了終端,又以是命令行的方式敲了一頓,問我:“這是不是你新建的分支?“
三歪點了點頭,於是我學長說:”好了,你再看看“。
後來發現,新建完遠程分支,如果在IDEA上要能感知到,可以在pull界面上刷新一下,那就能找到了。
也不是說命令行一定會就比界面牛逼,其實IDEA的Git功能也做得挺好的。現在我都是混合使用,一些操作用命令行,一些操作用IDEA快捷鍵。
我commit和push的時候就喜歡用快捷鍵。command+k和command +shift+k我就感覺比敲命令要快不少。
這些都是個人習慣的問題,也無對錯之分,怎麼方便怎麼來。
其實也不是所有的系統都會走發布系統的(有標準應用,非標準應用)。如果要自己寫一個啟動的腳本,一般我們會做些什麼?無非就是用Git拉最新的代碼,然後用maven打個包,然後啟動。
如果你看過上一篇《三歪給女朋友講解什麼是Git》應該能大概了解什麼是Git了。
其實我覺得學Git主要理解工作區 -> 暫存區->倉庫 這幾個概念。
我們使用Git其實絕大部分的操作都是在本地上完成的,比如說add 和commit。
只有我們push的時候,才會把本地完成好的內容推到遠程倉庫上
通過上一篇文章我們知道在每個人的本地都有完整的歷史版本,所以我們可以在本地就能穿梭到不同的版本,然後將修改之後的代碼再重新提交到遠程倉庫上。
所謂的工作區實際上就是我們真正的的本地目錄。
我們在本地添加文件后,需要add到暫存區,文件一旦被add到了暫存區,意味着Git能追蹤到這個文件。
當我們修改到一定程度之後,我們會執行一次提交commit,在提交的時候我們會”備註“自己這次的提交修改了什麼內容。
一次commit在Git就是一個版本,Git是版本控制的軟件,我們可以隨意穿梭到任何的版本中,修改代碼。
暫存區是這麼一個概念呢?
暫存區就像購物車,沒到付款的時候你都不確定購物車裡的東西全部都是要的。每拿一件商品就付一次款,那麻煩可大了。
從宏觀上看,Git其實有本地和遠程的概念,只是本地又分了工作區、暫存區、本地倉庫。再次強調:我們操作幾乎都是在本地完成,每個人的本地都會有所有歷史版本信息。
我們一般會新建分支去支持每一次的修改。
其實分支這個概念也挺好理解的:我們需要并行開發,同時我們又不關心對方改的是什麼內容,改的是什麼文件。因此我們需要在自己的專屬環境下去修改內容,只要把最終修改完后的內容合併到一個主分支就OK了。
假設三歪做完了,經過校驗通過後,把自己的代碼merge(合併)到origin/master分支后,然後就發布上線啦。
隨後,雞蛋也做完了,自己的分支校驗完了以後,他此時也想把自己的代碼合併到origin/master。不料,他改的代碼跟三歪改的代碼有衝突了(Git不知道選擇誰的的代碼),那雞蛋只能手動merge了。
綜合來看,我們使用Git大多數的場景就是各自分支開發,然後各自在本地commit(提交),最後匯總到master分支。
所以,我們學Git大多數就學怎麼實現分支的增刪改、切換以及版本的穿梭。
學習Git的小tips:
Unix/Linux 命令中,
-后一般跟短命令選項(通常是單字母,也有一些命令是例外的),--后一般跟長命令選項。如果只有一個單獨的--,後面不緊跟任何選項,則表示命令選項結束,後續的都作為命令的參數而不是選項。
例如:
git checkout -- filenamefilename作為git checkout的參數,而不是選項。
一、如果這個項目的代碼我們在本地還沒有,我們先去GitLab裡邊找對應的Git地址,然後Clone到本地:
git clone https://github.com/ZhongFuCheng3y/3y.git
二、接到了新的需求,我們要新建一個分支,然後基於這個分支去開發:
git checkout -b feature/sanwaiAddLog
在開發的時候,我們肯定會有兩個操作:
三、不管怎麼樣,等我們做到一定程度了,我們都會提交代碼。如果我們添加了新的文件,我們需要先add,然後再commit
git add .
git commit -m "try to commit files to GitHub, i am java3y"
四、假設我們一切順利,在沒人打擾的情況下已經寫好了代碼了,然後我們會把自己的分支push到遠程倉庫
git push
五、假設我們寫到一半,其他小夥伴已經把他的代碼merge到主分支了,我們也需要把他最新的 代碼給pull拉取下來(可以 git fetch + git merge 替代)。
git pull
如果沒有衝突,那git就會把他的代碼給merge到我當前的分支上。如果有衝突,Git會提醒我去手動解決一下衝突。
六、假設我們寫到一半了,現在工作區的代碼都已經commit了。此時同事說要不幫忙一起排查一個問題,同事一般用的是自己分支,於是就得問他:你用的哪個分支啊?於是得把他的分支給拉下來,看看他的代碼哪兒有問題
git fecth -- 手動拉取遠程倉庫更新的信息
git checkout 分支名 -- 切換到他的分支
現在切換到他的分支,相當於你的環境跟他的環境是一模一樣的,於是就可以愉快地一起看Bug了。
七、假設我們寫到一半了,現在工作區的代碼還沒commit。現在有同事說要排查問題或者一個新的Bug被發現了,要緊急切換到其他的分支。現在我又不想commit(我就寫了一半,編譯還報着錯誤,沒理由讓我commit吧)。
這時,我會把工作區的代碼先stash到暫存區給保存起來,然後就可以愉快地切換其他的分支了。
git stash
等我解決完另一個bug或者幫別人看完問題了,我再把剛剛保存在暫存區的代碼給撈出來,繼續幹活
git stash pop
八、我一直在修Bug,現在的分支已經被我搞得人摸鬼樣了,我非常難受,甚至不知道自己在這個過程中改了多少東西了。
思路已經完全被打亂了,我想回到一個穩定的commit重新出發,重來吧(通過下面的命令,把工作區的代碼都改成對應commit的代碼了)。
git reset --hard 版本號
那我怎麼找到版本號呢?Git也是有日誌的:
git log --pretty=oneline
查看Git工作區、暫存區的變更情況(可以知道哪些沒有commit、哪些沒有被Git追蹤):git status
拉取遠程最新的變更到本地:git fetch
切換分支:git checkout 分支名
將代碼還原到某個版本(包括工作目錄):git reset --hard 版本號
查看Git的提交(commit)記錄:git log
將代碼還原到某個版本后,後悔了,想重新回去,但在提交記錄已經找不到了。git reset --hard 把reset 之後的 commit都給抹殺掉了。找到最近的執行Git命令:git reflog
還原到某個版本了,現在我為了穩健,不想再原來的分支上修改了,再新建一個分支吧(-b 參數把當前分支切換到了要創建的分支上):git checkout -b 分支名
我們把上一次還是”相對穩健“的分支合併到我新建的分支上:git merge 分支
突然想看看現在有多少個分支:git branch -a
新增幾個文件了,隨手git add一下吧
改得差不多了,隨手git commit -m 一下吧,最好還是寫好備註,不然以後等改多了,你都不知道你改了什麼啦。
改完了,提交到遠程吧:git push
想把遠程分支最新的代碼給拉下來,然後合併到本地上。我們可以用git fetch和git merge 來實現,也可以通過git pull來實現。一般我用的都是git fetch+git merge ,這樣會更加可控一些
有的時候,本地分支在master分支,然後忘了切其他的分支去修改,直接在master改了,然後也push到遠程了。等你發現的時候,你會真的想罵自己。
咋辦?最簡單的辦法其實我們還是可以git reset --hard到對應的版本,然後將其修改或者復原,再強制提交到master分支:git push -u origin/master -f
在這篇文章中,我列出的Git常用的命令其實並不多吧。
像很多博客講的diff、tag、config之類的命令我都沒有講,我這邊現實開發時這些命令也沒怎麼用過…
如果覺得我說漏的,可以在評論區補充,一起學習。
其實現在IDEA也很強大,很多時候都可以配合IDEA給我們提供的Git去做很多事。有的場景敲命令會比較方便,有的時候就直接圖形化界面就比較方便。
就diff 這個功能而言, 肯定還是圖形界面好用一些吧(至少我是這樣認為的
IDEA配合一些快捷鍵,使用Git也能爽得飛起。Git始終也只是一個工具,如果你有興趣可以了解它的實現(我覺得大部分人可能不知道它是怎麼實現的);
如果沒興趣看它的實現,了解它是怎麼使用的,也足夠應付日常的開發場景了。
總的來說,現在的互聯網公司大多數還是用Git的,Git本身使用上其實不難,只要理解了Git是幹嘛的,它有個本地倉庫的概念,它可以來回穿梭各種版本,然後將本地的信息提交到遠程,跟着教程把常用的命令敲敲也差不多了。
如果實在是不懂,也別慌(我都給你們打了個樣了);主動認慫,虛心求教,同事們都不會嫌棄你的。
如果實習之前不知道要準備什麼去公司,要是對Git不了解,我覺得Git可以有佔一席之位。
更多Git命令和參考資料:
下面的文章都有對應的原創精美PDF,在持續更新中,可以來找我催更~
我是三歪,一個想要變強的男人,感謝大家的點贊收藏和轉發,下期見。給三歪點個贊,對三歪真的非常重要!
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準
※聚甘新

.Net Core為我們提供了一套強大的Configuration配置系統,使用簡單擴展性強。通過這套配置系統我們可以將Json、Xml、Ini等數據源加載到程序中,也可以自己擴展其他形式的存儲源。今天我們要做的就是通過自定義的方式為其擴展Etcd數據源操作。
在使用etcd之前我們先介紹一下Etcd,我相信很多同學都早有耳聞。Etcd是一款高可用、強一致的分佈式KV存儲系統,它內部採用raft協議作為一致性算法,本身也是基於GO語言開發的,最新版本為v3.4.9,具體版本下載地址可參閱官方GitHub地址。相信了解過K8S的同學對這個肯定不陌生,它是K8S的數據管理系統。官方地址為https://etcd.io/。
在此之前,我相信大家已經了解過很多存儲系統了,Etcd到底能實現了什麼功能呢?其一用於配置中心和服務發現,再者也可以實現分佈式鎖和消息系統。它本身就是基於目錄型存儲,並且內部有一套強大的Watch機制可以監聽針對節點和數據的操作變化,每次對節點的事務操作都會有對於的版本信息。
通過上面的介紹是不是感覺和Zookeeper有點類似呢,網上有很多很多關於Etcd和Zookeeper的對比文章,大致如下可以得到以下結論
| 功能 | Etcd | Zookeeper |
|---|---|---|
| 分佈式鎖 | 有(採用節點版本號信息) | 有(採用臨時節點和順序臨時節點) |
| watcher | 有 | 有 |
| 一致性算法 | raft | zab |
| 選舉 | 有 | 有 |
| 元數據(metadata)存儲 | 有 | 有 |
| 應用場景 | Etcd | Zookeeper |
|---|---|---|
| 發布與訂閱(配置中心) | 有(不限次Watch) | 有(一次性觸發的,需要重新註冊Watch) |
| 軟負載均衡 | 有 | 有 |
| 命名服務(Naming Service) | 有 | 有 |
| 服務發現 | 有(基於租約節點) | 有(基於臨時節點) |
| 分佈式通知/協調 | 有 | 有 |
| 集群管理與Master選舉 | 有 | 有 |
| 分佈式鎖 | 有 | 有 |
| 分佈式隊列 | 有 | 有 |
說白了就是Zookeeper能幹的活,Etcd也能幹。那既然有了Zookeeper為啥還要選擇Etcd,主要基於以下原因
一言以蔽之,就是不僅實現了Zookeeper的功能,還在很多方面吊打Zookeeper,這麼強大的東西忍不住都要試一試。
在Nuget上可以搜索到很多.Net Core的Etcd客戶端驅動程序,我使用了下載量最多的一個名字叫dotnet-etcd的驅動包,順便找到了它在GayHub上,不好意思手滑打錯了GitHub上的項目地址,大概學習了一下基本的使用方式。其實我們結合Configuration配置這一塊,只需要兩個功能。一個是Get獲取數據,另一個是Watch節點變化(更新數據會用到)。個人認為,前期有目有邊界的學習還是非常重要的。
前面我們講到過自定義擴展Configuration是非常方便的,相信了解過Configuration相關源碼的小夥伴們已經非常熟悉了,大致總結一下分為三步:
因為微軟已經給我們提供了一部分便利,所以編寫起來還是非常的簡單的。好了,接下來我們開始編寫具體的實現代碼,重點的地方我會在代碼中註釋說明。
首先是定義擴展類EtcdConfigurationExtensions,這個類是針對IConfigurationBuilder的擴展方法,實現如下
public static class EtcdConfigurationExtensions
{
/// <summary>
/// AddEtcd擴展方法
/// </summary>
/// <param name="serverAddress">Etcd地址</param>
/// <param name="path">讀取路徑</param>
/// <returns></returns>
public static IConfigurationBuilder AddEtcd(this IConfigurationBuilder builder, string serverAddress,string path)
{
return AddEtcd(builder, serverAddress:serverAddress, path: path,reloadOnChange: false);
}
/// <summary>
/// AddEtcd擴展方法
/// </summary>
/// <param name="serverAddress">Etcd地址</param>
/// <param name="path">讀取路徑</param>
/// <param name="reloadOnChange">如果數據發送改變是否刷新</param>
/// <returns></returns>
public static IConfigurationBuilder AddEtcd(this IConfigurationBuilder builder, string serverAddress, string path, bool reloadOnChange)
{
return AddEtcd(builder,options => {
options.Address = serverAddress;
options.Path = path;
options.ReloadOnChange = reloadOnChange;
});
}
public static IConfigurationBuilder AddEtcd(this IConfigurationBuilder builder, Action<EtcdOptions> options)
{
EtcdOptions etcdOptions = new EtcdOptions();
options.Invoke(etcdOptions);
return builder.Add(new EtcdConfigurationSource { EtcdOptions = etcdOptions });
}
}
這裏我還定義了一個EtcdOptions的POCO,用於承載讀取Etcd的配置屬性
public class EtcdOptions
{
/// <summary>
/// Etcd地址
/// </summary>
public string Address { get; set; }
/// <summary>
/// Etcd訪問用戶名
/// </summary>
public string UserName { get; set; }
/// <summary>
/// Etcd訪問密碼
/// </summary>
public string PassWord { get; set; }
/// <summary>
/// Etcd讀取路徑
/// </summary>
public string Path { get; set; }
/// <summary>
/// 數據變更是否刷新讀取
/// </summary>
public bool ReloadOnChange { get; set; }
}
接下來我們定義EtcdConfigurationSource,這個類非常簡單就是返回一個配置提供對象
public class EtcdConfigurationSource : IConfigurationSource
{
public EtcdOptions EtcdOptions { get; set; }
public IConfigurationProvider Build(IConfigurationBuilder builder)
{
return new EtcdConfigurationProvider(EtcdOptions);
}
}
真正的讀取操作都在EtcdConfigurationProvider里
public class EtcdConfigurationProvider : ConfigurationProvider
{
private readonly string _path;
private readonly bool _reloadOnChange;
private readonly EtcdClient _etcdClient;
public EtcdConfigurationProvider(EtcdOptions options)
{
//實例化EtcdClient
_etcdClient = new EtcdClient(options.Address,username: options.UserName,password: options.PassWord);
_path = options.Path;
_reloadOnChange = options.ReloadOnChange;
}
/// <summary>
/// 重寫加載方法
/// </summary>
public override void Load()
{
//讀取數據
LoadData();
//數據發生變化是否重新加載
if (_reloadOnChange)
{
ReloadData();
}
}
private void LoadData()
{
//讀取Etcd里的數據
string result = _etcdClient.GetValAsync(_path).GetAwaiter().GetResult();
if (string.IsNullOrEmpty(result))
{
return;
}
//轉換一下數據結構,這裏我使用的是json格式
//讀取的數據只要賦值到Data屬性上即可,IConfiguration真正讀取的數據就是存儲到Data的字典數據
Data = ConvertData(result);
}
private IDictionary<string,string> ConvertData(string result)
{
byte[] array = Encoding.UTF8.GetBytes(result);
MemoryStream stream = new MemoryStream(array);
//JsonConfigurationFileParser是將json數據轉換為Configuration可讀取的結構(複製JsonConfiguration類庫里的)
return JsonConfigurationFileParser.Parse(stream);
}
private void ReloadData()
{
WatchRequest request = new WatchRequest()
{
CreateRequest = new WatchCreateRequest()
{
//需要轉換一個格式,因為etcd v3版本的接口都包含在grpc的定義中
Key = ByteString.CopyFromUtf8(_path)
}
};
//監聽Etcd節點變化,獲取變更數據,更新配置
_etcdClient.Watch(request, rsp =>
{
if (rsp.Events.Any())
{
var @event = rsp.Events[0];
//需要轉換一個格式,因為etcd v3版本的接口都包含在grpc的定義中
Data = ConvertData(@event.Kv.Value.ToStringUtf8());
//需要調用ConfigurationProvider的OnReload方法觸發ConfigurationReloadToken通知
//這樣才能對使用Configuration的類發送數據變更通知
//比如IOptionsMonitor就是通過ConfigurationReloadToken通知變更數據的
OnReload();
}
});
}
}
使用方式如下
builder.AddEtcd("http://127.0.0.1:2379", "service/mydemo", true);
順便給大家推薦一個Etcd可視化管理工具ETCD Manager,以便更好的學習Etcd。
到這裏,基本上就結束了,是不是非常簡單。主要還是Configuration本身的設計思路比較清晰,所以實現起來也不費勁。
以上代碼都已經上傳了我的GitHub,該倉庫還擴展了其他數據源的讀取比如Consul、Properties文件、Yaml文件的讀取,實現思路也都大致相似,有興趣的同學可以自行查閱。由於主要是講解實現思路,可能許多細節並未做處理還望見諒。如果有疑問或者更好的建議,歡迎評論區交流指導。
歡迎掃碼關注 本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※教你寫出一流的銷售文案?
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※回頭車貨運收費標準
※別再煩惱如何寫文案,掌握八大原則!
※超省錢租車方案
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※聚甘新