在上月末的時候收到一條關於fastjson安全漏洞的消息,突然想到先前好像已經有好多次這樣的事件了(在fastjson上面)。關於安全方面,雖然中槍的機率微小,但是在這個信息越來越複雜的時代,安全性也變得越來越重要,就像DevSecOps的誕生,在軟件交付的整個價值流中我們也需要注重安全這方面。當然我們現在不談關於FastJson的優劣,因為我們本文的目標是讓大家了解和掌握Jackson。
概覽
Jackson是一個非常流行和高效的基於Java的庫,它可以序列化java對象或將java對象映射到JSON,反之亦然。當然除了Jackson,在Java中同類型的優秀的庫也有很多,比如:
關於哪一個最好或者哪一個最流行,沒有明確的答案。技術的種類繁多,每個人對與不同技術的態度也不一樣。言歸正傳,文章主要還是討論Jackson的。本文主要講解我們處理Json中最常見的兩個操作:
- 將Java對象序列化為JSON
- JSON字符串反序列化為Java對象
引入依賴
由於在Spring/SpringBoot中很多組件已經自帶了Jackson庫,所以很多情況下不需要手動引入Jackson的依賴。
手動引入依賴:
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.9.8</version>
</dependency>
這個依賴關係還將傳遞地向類路徑添加以下庫:
- jackson-annotations-2.9.8.jar
- jackson-core-2.9.8.jar
- jackson-databind-2.9.8.jar
JavaObject to Json
ObjectMapper
ObjectMapper是一個映射器(或數據綁定器或編解碼器),提供了在Java對象(bean的實例)和JSON之間進行轉換的功能。
首先定義一個簡單的Java類
public class Car {
private String color;
private String type;
// standard getters setters
}
將Java對象轉換成Json
我們使用ObjectMapper的writeValue相關Api來對Java對象進行序列化操作
ObjectMapper objectMapper = new ObjectMapper();
Car car = new Car("blue","c1");
System.out.println(objectMapper.writeValueAsString(car));
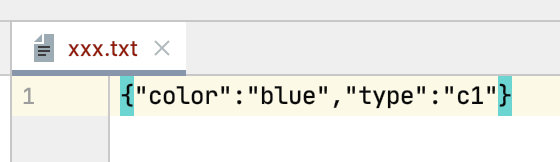
此時輸出
{"color":"blue","type":"c1"}
更多
ObjectMapper的writeValue相關Api還提供了很多便利的Json序列化操作方法,比如:將對象序列化成Json字節數組的writeValueAsBytes()方法、自定義輸出源的writeValue()方法…
ObjectMapper objectMapper = new ObjectMapper();
Car car = new Car("blue","c1");
objectMapper.writeValue(new File("./xxx.txt"),car);
運行上述代碼,Java對象的序列化Json將被輸出到xxx.txt文件。
Json to JavaObject
將Json String轉換成Java Object
ObjectMapper objectMapper = new ObjectMapper();
String json = "{\"color\":\"blue\",\"type\":\"c1\"}";
Car car = objectMapper.readValue(json, Car.class);
readValue()方法也接受其他形式的輸入,比如包含JSON字符串的文件:
ObjectMapper objectMapper = new ObjectMapper();
Car car = objectMapper.readValue(new File("./xxx.txt"), Car.class);
System.out.println(car);
JSON to Jackson JsonNode
JsonNode
一個JSON可以被解析成一個JsonNode對象,用來從一個特定的節點檢索數據.
使用readTree()方法,我們可以將Json字符串轉換成JsonNode
ObjectMapper objectMapper = new ObjectMapper();
String json = "{ \"color\" : \"Black\", \"type\" : \"FIAT\" }";
JsonNode jsonNode = objectMapper.readTree(json);
System.out.println(jsonNode.findValue("type").asText());
// 打印出“FAIT”
JSONArrayString to JavaList
ObjectMapper objectMapper = new ObjectMapper();
String jsonCarArray =
"[{ \"color\" : \"Black\", \"type\" : \"BMW\" }, { \"color\" : 3. \"Red\", \"type\" : \"FIAT\" }]";
List<Car> listCar = objectMapper.readValue(jsonCarArray, new TypeReference<List<Car>>() {});
JSONString to JavaMap
ObjectMapper objectMapper = new ObjectMapper();
String json = "{ \"color\" : \"Black\", \"type\" : \"BMW\" }";
Map<String, Object> map = objectMapper.readValue(json, new TypeReference<Map<String, Object>>() {
});
:Jackson庫最大的優點之一是高度可定製的序列化和反序列化過程。接下來將介紹一些高級特性,其中輸入或輸出JSON響應可以與生成或使用響應的對象不同。
配置序列化和反序列化特性
String jsonString = "{ \"color\" : \"Black\", \"type\" : \"Fiat\", \"year\" :\"1970\" }";
假設使用如上json字符串來反序列化成Java對象,按照默認解析過程將導致UnrecognizedPropertyException異常,因為其中存在Car類中未包含的新字段year。
通過配置序列化和反序列化特性來解決此問題:
ObjectMapper objectMapper = new ObjectMapper();
String jsonString = "{ \"color\" : \"Black\", \"type\" : \"Fiat\", \"year\" :\"1970\" }";
objectMapper.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false);
Car car = objectMapper.readValue(jsonString, Car.class);
如上,我們在ObjectMapper中配置了DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES=false,從而實現忽略新的字段。
類似:另一個選項FAIL_ON_NULL_FOR_PRIMITIVES,它定義了是否允許原始值的空值;FAIL_ON_NUMBERS_FOR_ENUM控制是否允許enum值被序列化/反序列化為数字……
自定義序列化器或反序列化器
自定義序列化器
public static class CustomCarSerializer extends StdSerializer<Car> {
public CustomCarSerializer() {
this(null);
}
public CustomCarSerializer(Class<Car> t) {
super(t);
}
@Override
public void serialize(Car car, JsonGenerator jsonGenerator, SerializerProvider serializer) throws IOException {
jsonGenerator.writeStartObject();
jsonGenerator.writeStringField("car_brand", car.getType());
jsonGenerator.writeEndObject();
}
}
如上,通過繼承StdSerializer類,我們實現了一個自定義的序列化器。
使用自定義的序列化器:
ObjectMapper mapper = new ObjectMapper();
SimpleModule module = new SimpleModule("CustomCarSerializer", new Version(1, 0, 0, null, null, null));
module.addSerializer(Car.class, new CustomCarSerializer());
mapper.registerModule(module);
Car car = new Car("yellow", "enault");
System.out.println(mapper.writeValueAsString(car));
//輸出{"car_brand":"enault"}
自定義反序列化器
public static class CustomCarDeserializer extends StdDeserializer<Car> {
public CustomCarDeserializer() {
this(null);
}
protected CustomCarDeserializer(Class<?> vc) {
super(vc);
}
@Override
public Car deserialize(JsonParser p, DeserializationContext ctxt) throws IOException, JsonProcessingException {
Car car = new Car();
ObjectCodec codec = p.getCodec();
JsonNode node = codec.readTree(p);
// try catch block
JsonNode colorNode = node.get("color");
String color = colorNode.asText();
car.setColor(color);
return car;
}
}
如上,通過繼承StdDeserializer類,我們實現了一個自定義的序列化器。
使用自定義的反序列化器:
String json = "{ \"color\" : \"Black\", \"type\" : \"BMW\"}";
ObjectMapper mapper = new ObjectMapper();
SimpleModule module = new SimpleModule("CustomCarDeserializer", new Version(1, 0, 0, null, null, null));
module.addDeserializer(Car.class, new CustomCarDeserializer());
mapper.registerModule(module);
Car car = mapper.readValue(json, Car.class);
//此時的car {color='Black', type='null'}
處理時間格式
️:此處僅展示對於Java8的LocalDate&LocalDateTime的處理
首先創建一個帶日期時間字段的Car類
public class Car {
private String color;
private String type;
@JsonFormat(pattern = "yyyy-MM-dd")
private LocalDateTime produceTime;
// standard getters setters
}
自定義時間格式處理
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.findAndRegisterModules();
Car car = new Car().setColor("blue").setType("c1").setProduceTime(LocalDateTime.now());
String carAsString = objectMapper.writeValueAsString(car);
System.out.println(carAsString);
//此時輸出:{"color":"blue","type":"c1","produceTime":"2020-06-06"}
處理集合
DeserializationFeature類提供的另一個小但有用的特性是能夠從JSON數組響應生成我們想要的集合類型。
String jsonCarArray = "[{ \"color\" : \"Black\", \"type\" : \"BMW\"}, { \"color\" : \"Red\", \"type\" : \"FIAT\"}]";
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.configure(DeserializationFeature.USE_JAVA_ARRAY_FOR_JSON_ARRAY, true);
Car[] cars = objectMapper.readValue(jsonCarArray, Car[].class);
如上,我們將一個JsonArray字符串轉換成了對象數組。
我們也可以將其轉換成集合:
String jsonCarArray = "[{ \"color\" : \"Black\", \"type\" : \"BMW\"}, { \"color\" : \"Red\", \"type\" : \"FIAT\"}]";
ObjectMapper objectMapper = new ObjectMapper();
List<Car> listCar = objectMapper.readValue(jsonCarArray, new TypeReference<List<Car>>(){});
總結
Jackson是一個可靠而成熟的用於Java的JSON序列化/反序列化庫。ObjectMapper API提供了一種簡單的方法來解析和生成JSON響應對象,具有很大的靈活性。
歡迎訪問筆者博客:blog.dongxishaonian.tech
關注筆者公眾號,推送各類原創/優質技術文章 ⬇️
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※超省錢租車方案
※教你寫出一流的銷售文案?
※網頁設計最專業,超強功能平台可客製化
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※台中搬家遵守搬運三大原則,讓您的家具不再被破壞!