如果把互聯網上的紛繁代碼比作一片海洋,那麼git就是在這片海洋上航行的船隻,正所謂“水可載舟,亦可覆舟”,git使用恰當可以遠征星辰,不然可能會墜入無窮無盡的代碼海洋無法自拔。書回正傳,我們的征途是星辰大海!
揚帆起航
git的下載安裝暫且不表,可參考網站https://git-scm.com/downloads。
git的安裝只是個入門條件,下面如何使用git命令控制代碼才是遠征的基礎。那麼從何開始呢?讓我們一步步說起。
要想揚帆起航,首先得有艘帆船吧。我們要在本地建立一個項目,之後將本地項目初始化為git倉庫,可以使用
git init [–bare]
初始化本地項目,執行後會在當前執行目錄下生成.git文件夾,這也就是我們的帆船了。[–bare]可選參數,可初始化裸倉庫,裸倉庫可以與源碼項目分離,此時在當前目錄下不會生成.git文件夾,而是直接生成.git文件夾下的包括hooks、info、objects、refs共四個文件夾和config、description、HEAD三個文件。
在初始化裸倉庫后若想關聯源碼,只需進入hooks目錄新建post-receive.sample文件,並添加如下內容:
git –work-tree=<project-dir> –git-dir=<local-url> checkout -f
其中<project-dir>為本地項目文件路徑,<local-url>為本地git倉庫路徑。
對於當前目錄下的.git文件夾所代表的本地倉庫,不同的帆船有不同的配置,我們使用
git config –list
显示當前git配置。如果內容過多可以使用上下鍵翻頁,查看結束按q退出即可。同時使用
git config –e [–global]
以vim形式編輯修改git配置文件。
或
git config [–global] user.name “name”
形式修改指定配置,其中[–global]可選,為全局配置,name為用戶名配置。
git儀錶盤
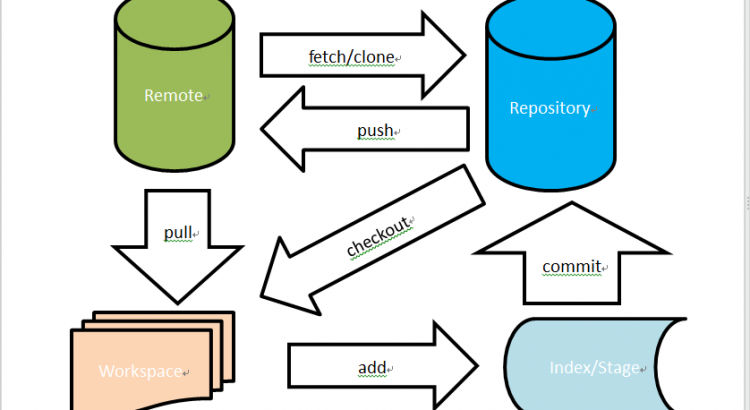
圖 1 Git指令關係圖
建立git倉庫作為帆船后,就可以在當前目錄下任意使用git指令遨遊了。我們需要先認識下git控制的命令儀錶盤。
如圖1所示,git整艘船主要分為四大區域,包括Remote遠程倉庫,Repository本地倉庫,Index/Stage暫存區,Workspace工作區,不同區域之間可以使用相關指令進行代碼操作。在上節使用git init創建的文件夾下,會生成名為.git的隱藏文件夾,四大區域的配置都儲存在該文件夾下。其中在遠程倉庫和本地倉庫中,儲存有不同的branch分支,工作區和暫存區的文件只能針對某一分支進行修改提交操作,當然也可以使用分支操作指令對不同的分支進行增刪合併等操作。
針對一些倉庫的操作指令,使用前請務必保持頭腦清醒,不然你的一個蝴蝶煽動翅膀似的操作,可能會引發倉庫里的一場代碼風暴,造成不可挽回的結果。
根據不同命令操作區域,可以將git命令大致分為全局显示信息、工作區與遠程倉庫交互、工作區與本地倉庫交互、工作區與暫存區交互、暫存區與本地倉庫交互、本地倉庫與遠程倉庫交互、以及倉庫內部分支操作。下面對這些命令進行了粗略的統計介紹,詳細使用方式可參考git官方文檔介紹,如有不足還請補充。
显示信息
git help [command]
獲取命令的幫助信息。
git status
显示所有變更文件
git log [–stat] [–graph]
显示當前分支的版本信息。[–stat]參數指定显示commit發生變更的文件。[–graph]參數以數據圖形式查看合併分支記錄。
git blame <file>
显示文件的每一行最後修改的版本和作者
git show [commit][:filename]
显示某次提交的變更內容。其中[commit]為某次提交版本,也可在:後邊加參數[filename]指定查看某個文件內容。
git diff [HEAD] [first-branch] [second-branch]
显示文件差異。無參時比較緩存區和上一次commit的差異;[HEAD]為工作區與當前分支最新commit的差異;或者兩個分支之間的差異。
git reflog
显示已執行過的所有git動作日誌。
工作區與遠程倉庫
git pull <remote> <branch>
拉取遠程倉庫的變化,並與本地分支合併。<remote>為遠程倉庫名,<branch>為遠程倉庫中的某一分支名。
工作區與本地倉庫
git checkout [–b] <branch> [tag]
將暫存區切換到分支名。其中[-b]參數可選,當分支不存在時則創建,<branch >必須,為本地倉庫分支,[tag]可選,指定切換到倉庫分支中的某條標籤,不標註則默認為切換分支的最近一次提交。
工作區與暫存區
git add <dir>
添加指定目錄到暫存區,<dir>為添加路徑,允許多個,包括子目錄都會添加到暫存區中等待提交。
git rm [–cached] <file>
刪除暫存區中的文件,<file>為暫存區中要刪除的文件全路徑,[–cache]可選參數,只會停止繼續追蹤指定文件,但該文件目前仍然保留在暫存區。
git mv <file-old> <file-new>
修改暫存區中的文件名,<file-old>為原文件全路徑,<file-new>為修改后的文件全路徑。
git tag
查看暫存區中的所有標籤信息。
git tag –a <tag> [commit]
新建一個標籤。[tag]為標籤名;[commit]為指定的一次從暫存區到本地倉庫的提交中,默認為最新一次提交。
git tag –d [tag]
刪除本地標籤。
暫存區與本地倉庫
git commit [–amend] [–m <message>] [file] [-a] [-v]
從暫存區提交到本地倉庫。其中[–amend]重做上次從本地項目到暫存區的commit,當代碼與上次提交相比無變化時使用,只修改上次commit的<message>內容;[-m]參數為提交信息,<message>必寫且詳寫,以區別提交代碼的修改內容;[file]為指定暫存區中的文件;[-a]可直接提交項目中的變化到本地倉庫,在沒有新增文件時不需每次先git add提交到暫存區再提交到本地倉庫;[-v]可以在提交時显示所有變化文件的diff信息。
git cherry-pick [commit]
選擇一個commit版本合併到當前分支,[commit]為暫存區中的commit版本。
本地倉庫與遠程倉庫
git remote [-v]
查看關聯的遠程倉庫信息。[-v]可以查看詳細信息。
git remote add <remote-name> <remote-url>
本地路徑關聯遠程倉庫。
<remote-name>必要參數,為遠程倉庫的名字,默認是origin。
<remote-url>必要參數,為遠程倉庫的地址,git服務器通常都是以.git結尾。
git remote remove <remote-name>
刪除關聯的遠程倉庫。其中<remote-name>為遠程倉庫的名字。
git push [remote] [branch] [–force]
推送本地指定分支到遠程倉庫。[remote]為遠程倉庫名,[branch]為本地分支名,[–force]為強制推送本地到遠程,如有衝突則覆蓋。
git fetch <remote>
將遠程倉庫拉到本地倉庫。<remote>為遠程倉庫名。
git clone <url> [name]
創建一個本地倉庫。<url>必須,可以是遠程git服務器上的倉庫,也可以是本地倉庫。[name]選填是創建的新倉庫名,默認與原倉庫名一致。
分支指令
git branch [-r] [-a]
查看分支信息,無參只會查看本地倉庫所有分支,[-r]是遠程倉庫所有分支,[-a]則是包括本地和遠程倉庫所有的所有分支。
git branch [branch-name] [commit]
在本地倉庫新建分支,但暫存區仍然指向當前分支。其中[branch-name]為新建的本地倉庫分支;[commit]可將分支指向指定commit版本。
git branch –track [local-branch-name] [remote-branch]
新建一個分支,並連接指定的遠程分支。其中[local-branch-name]為本地倉庫新建分支,[remote-branch]為遠程倉庫分支。
git branch –set-upstream [local-branch] [remote-branch]
連接本地倉庫分支與遠程倉庫分支,其中[local-branch]為本地倉庫已有分支,[remote-branch]為遠程倉庫分支。
git branch –d [branch]
刪除本地倉庫分支,[branch]為本地倉庫中的已有分支。
git branch -m [branch-old] [branch-new]
修改本地倉庫分支,其中[branch-old]為原分支,[branch-new]為改名后的分支。
git branch –dr [remote-branch]
刪除遠程倉庫分支,[remote-branch]為遠程倉庫中的分支。不推薦使用,如果遠程倉庫未更新,可能會執行失敗,推薦使用git push origin-delete [remote-branch]。
git merge <local-branch>
合併指定分支到當前分支,<local-branch>為本地倉庫中的已有分支。
git rebase <remote-branch>
將當前分支的提交複製到指定的遠程分支上,<remote-branch>為指定遠程倉庫中的已有分支。
git reset [–mixed|–soft|–hard] [commit]
重置倉庫索引,重置一旦清空后的內容不會在倉庫歷史版本中留下歷史記錄。[–mixed]為默認參數,重置后只在工作區保留原節點修改文件,清空暫存區和本地倉庫並均恢復到指定重置節點;[–soft]為軟重置,重置后在工作區和暫存區均保留原節點修改文件,清空本地倉庫並恢復到指定重置節點;[–hard]為硬重置,重置后均不會保留原節點修改文件。[commit]為要重置的節點號。
git revert [commit]
還原文件到之前修改提交節點時,會在倉庫歷史版本中留下歷史記錄。[commit]為要還原的節點號。
常規操作
git這艘大船雖然功能繁雜,但是用起來是有章可循的。入門之後就駕駛下這艘大船來試試吧。
一般git有三種工作流程,包括Git flow,項目存在兩個長期分支(主分支master和開發分支develop),適用於基於版本發布的普通項目;Github flow,只有一個長期分支(主分支master),適用於持續發布的小型項目;Gitlab flow,項目存在多個長期分支,其中主分支master是其他所有分支的上游,只有上游分支採納的代碼才能應用到其下游分支,適用於長期維護的大型項目。
圖2展示了一次項目git流程演變過程,在master主分支上有Tag1-Tag4四次代碼更新,其中基於Tag2對應的版本1號創建了新的branch1分支,新分支創建后自動生成了版本2號並打上了Tag2-1標籤,之後master主分支和branch1分支都同時進行了代碼演變,在branch1分支提交的版本4號及標籤Tag2-3之後,branch1分支合併到了master主分支,合併前master主分支位於版本5號,合併后可能重新生成版本6號,並打上新的tag4標籤,之後master主分支修改提交為版本7號,而branch1分支則停留在tag2-3標籤的位置處。
圖 2 Git流程示意圖
在這份項目流程中,分支創建之後,可能在不同的階段修改提交文件,根據對文檔的讀取權限範圍,我們可以形象地將這些階段劃分為三種身份類型,船長、水手和遊客。船長身份,作為項目管理者,主要負責遠程倉庫和本地倉庫之間的分支操作,協調分支衝突;水手身份,作為項目貢獻者,主要負責某一分支的迭代更新;遊客身份,作為項目使用者,只是訪問使用倉庫及其分支內容,不能提交任何修改。同一人在項目的不同階段可以是其中任意一種身份,下面以這三種身份為維度簡單介紹下使用到的相關git指令步驟,並輔以示意圖方式直觀解釋git指令執行前後git項目變化。
項目使用者-遊客
作為git項目的遊客,當然只能將項目從遠程倉庫拉取到本地使用,期間除了切換倉庫分支外不會涉及其他遠程操作。
git pull origin master
拉取遠程倉庫origin的master分支到本地。
git checkout branch1 tag1
切換到分支branch1。
項目貢獻者-水手
作為項目的水手,除了可以使用遊客的功能指令外,還會涉及到修改工作區文件,並將工作區文件提交到暫存區和倉庫等任務。通常水手只需要維護倉庫中的某一條分支並只對該分支負責,因此水手更注重工作區的代碼文件修改工作。
git pull origin dev:branch1
拉取遠程倉庫origin的dev分支到本地,並與本地branch1分支合併。工作區中文件即显示branch1分支,可在工作區做文件修改操作。
git add .
在工作區的文件修改之後,可先添加當前目錄所有文件到暫存區,之後可繼續修改工作區其他文件,也可將暫存區文件提交到本地倉庫。
git rm –cached file
針對工作區編譯生成的配置file文件,一般不需提交到倉庫,可使用該命令將file文件從暫存區刪除並停止後續追蹤。另外一種添加忽略文件的方式,在.git文件夾的同級目錄下新建.gitignore文件,在該文件中根據規則增加要忽略的文件路徑,之後將該文件提交到本地倉庫中。
git commit –m “commit message 1”
在確保工作區的所有修改文件均已提交到暫存區后,便將暫存區的修改提交到本地倉庫,同時附帶當次提交信息。每次提交都會在本地倉庫生成一個新的提交commit版本號,由於提交的commit版本號是冗長的sha1碼,所以為了方便後期溯源,通常會在主要的commit號版本上再打一個鮮明的標籤以作標記。
git tag tag1 1
在提交的commit版本號為1的節點上打標籤,打上標籤后的commit號便可使用簡短的標籤名tag1訪問,以便後期對該節點溯源。
git push origin branch1:dev –tags
將本地branch1分支及相關標籤推送到遠程倉庫origin的dev分支。如果本地branch1分支已經與遠程dev分支建立追蹤關係,也可直接使用
git push origin branch1 –tags
指令。
git branch –set-upstream-to=origin/dev branch1
設置本地倉庫的branch1分支與遠程倉庫origin的dev分支的追蹤關係。通常從遠程分支pull到本地的分支都已經建立了追蹤關係,不需要手動修改。
git branch –vv
查看本地分支及追蹤的遠程分支信息。
項目管理者-船長
作為項目的船長,自然擁有整個git這艘大船的項目所有權限,除了使用水手的操作指令外,另需完成分支增刪合併等任務。通常船長是項目倉庫的創建者,負責管理維護倉庫的各分支關係,對項目的整個倉庫負責,因此相較於水手,船長更注重倉庫的分支管理相關工作。
git clone https://github.com/xxx.git -b dev
克隆遠程倉庫的dev分支到本地,默認會將文件更新到本地倉庫建立的同名dev分支。
git checkout –b branch1 origin/dev
在本地倉庫新建branch1分支,與遠程倉庫origin中的dev分支對應,並在本地切換到branch1分支。如果不指定遠程倉庫及分支信息origin/dev,則默認從本地倉庫dev分支創建。至此可以切換為水手身份,從該分支更新代碼,並將修改文件提交到該branch1分支。
git add .
git commit –m “modify file commit”
在完成對工作區文件的修改之後,使用水手身份將工作區的修改提交到本地branch1分支。
git checkout dev
切換到本地倉庫的dev主分支,作為本地倉庫與遠程倉庫代碼合併的操作分支。
git fetch origin dev
拉取遠程倉庫origin中的dev分支到本地倉庫當前dev分支
git pull
將本地倉庫dev分支的文件修改合併到工作區。
git merge branch1
將本地倉庫的branch1分支合併到當前dev分支。如果當前dev分支與branch1分支有衝突,需要根據衝突文件提示分別修改,之後再重新合併該分支。
git checkout branch1 build/files
或者只將branch1分支的build/files目錄下所有文件合併到本地倉庫的當前dev分支。同樣需要做衝突處理。
git push origin dev:dev –tags
向遠程倉庫origin中的dev分支並推送本地倉庫dev分支。推送時如果確認以本地分支覆蓋遠程分支,則可使用
git push —force origin dev:dev –tags
強制推送。最後如果想刪除遠程分支,有以下兩條指令
git push origin –delete dev
git push origin :dev
這兩種方式都可以刪除指定的遠程倉庫origin中的dev分支。
應急預案
上面的圖2Git流程圖簡單涉及了一次版本演變過程中的一些git信息,包括分支切換,打標籤等,看上去簡單易懂,而實際我們工作中駕船航行時卻並不總是風平浪靜。
通常出現的緊急情況需要修改分支版本,包括變基、還原、重置等操作,針對不同場景需要選擇不同的操作方式。
變基
git rebase master
變基會將當前分支的修改文件複製到master分支,同時創建新的commit版本號並修改項目的歷史記錄。當master分支已經更新,且確認當前分支與master分支沒有衝突,那可以使用變基以便當前分支獲取master分支的更新。
重置
git reset 1
將HEAD重置到歷史提交版本1的狀態,還原倉庫和暫存區的文件與提交版本1一致,工作區維持修改文件狀態。
還原
git revert 1
重新創建一次提交版本節點,文件狀態與歷史提交版本1一致,工作區、暫存區與倉庫均保持一致。提交版本2相對於提交版本1新增了file.txt文件,執行該指令后,在提交版本3中將恢復到提交版本1的狀態,因此提交版本3相對於提交版本2則刪除了file.txt文件。
強制遠程覆蓋本地
git fetch –all
拉取遠程所有倉庫到本地倉庫,工作區不會有任何合併更新。
git reset –hard origin/dev
把工作區HEAD指向最新的遠程倉庫origin中的dev版本。
待補充
除此之外在駕馭git這艘大船時肯定還會出現各種意外,屆時將酌情補充。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※新北清潔公司,居家、辦公、裝潢細清專業服務
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※超省錢租車方案
※教你寫出一流的銷售文案?
※網頁設計最專業,超強功能平台可客製化