Python 內存管理分層架構
/* An object allocator for Python.
Here is an introduction to the layers of the Python memory architecture,
showing where the object allocator is actually used (layer +2), It is
called for every object allocation and deallocation (PyObject_New/Del),
unless the object-specific allocators implement a proprietary allocation
scheme (ex.: ints use a simple free list). This is also the place where
the cyclic garbage collector operates selectively on container objects.
Object-specific allocators
_____ ______ ______ ________
[ int ] [ dict ] [ list ] ... [ string ] Python core |
+3 | <----- Object-specific memory -----> | <-- Non-object memory --> |
_______________________________ | |
[ Python's object allocator ] | |
+2 | ####### Object memory ####### | <------ Internal buffers ------> |
______________________________________________________________ |
[ Python's raw memory allocator (PyMem_ API) ] |
+1 | <----- Python memory (under PyMem manager's control) ------> | |
__________________________________________________________________
[ Underlying general-purpose allocator (ex: C library malloc) ]
0 | <------ Virtual memory allocated for the python process -------> |
=========================================================================
_______________________________________________________________________
[ OS-specific Virtual Memory Manager (VMM) ]
-1 | <--- Kernel dynamic storage allocation & management (page-based) ---> |
__________________________________ __________________________________
[ ] [ ]
-2 | <-- Physical memory: ROM/RAM --> | | <-- Secondary storage (swap) --> |
*/
reference:Objects/obmalloc.c
layer 3: Object-specific memory(int/dict/list/string....)
python 實現並維護
用戶對Python對象的直接操作,主要是各類特定對象的緩衝池機制,緩衝池,比如小整數對象池等等
layer 2: Python's object allocator
實現了創建/銷毀python對象的接口(PyObject_New/Del),涉及對象參數/引用計數等
layer 1: Python's raw memory allocator (PyMem_ API)
包裝了第0層的內存管理接口,提供同一個raw memory管理接口
封裝的原因:不同操作系統C行為不一致,保證可移植性,相同語義相同行為
layer 0: Underlying general-purpose allocator (ex: C library malloc)
操作系統提供的內存管理接口,由操作系統實現並管理,Python不能干涉這一層的行為,大內存 分配調用malloc函數分配內存
Python 內存分配策略之-block,pool
Python中有分為大內存和小內存,512K為分界線
-
大內存使用系統malloc進行分配
-
小內存使用python內存池進行分配
1. 如果要分配的內存空間大於 SMALL_REQUEST_THRESHOLD bytes(512 bytes), 將直接使用layer 1的內存分配接口進行分配
2. 否則, 使用不同的block來滿足分配需求
申請一塊大小28字節的內存, 實際從內存中劃到32字節的一個block (從size class index為3的pool裏面劃出)
block
內存塊block 是python內存的最小單位
* For small requests we have the following table:
*
* Request in bytes Size of allocated block Size class idx
* ----------------------------------------------------------------
* 1-8 8 0
* 9-16 16 1
* 17-24 24 2
* 25-32 32 3
* 33-40 40 4
* 41-48 48 5
* 49-56 56 6
* 57-64 64 7
* 65-72 72 8
* ... ... ...
* 497-504 504 62
* 505-512 512 63
*
* 0, SMALL_REQUEST_THRESHOLD + 1 and up: routed to the underlying
* allocator.
*/
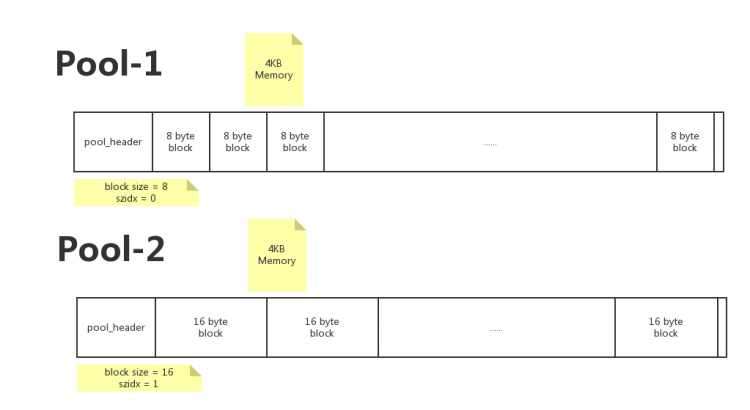
pool
pool內存池,管理block, 一個pool管理着一堆固定大小的內存塊,在Python中, 一個pool的大小通常為一個系統內存頁. 4kB
#define SYSTEM_PAGE_SIZE (4 * 1024)
#define SYSTEM_PAGE_SIZE_MASK (SYSTEM_PAGE_SIZE - 1)
#define POOL_SIZE SYSTEM_PAGE_SIZE /* must be 2^N */
#define POOL_SIZE_MASK SYSTEM_PAGE_SIZE_MASK
pool的4kB內存 = pool_header + block集合(N多大小一樣的block)
typedef uint8_t block;
/* Pool for small blocks. */
struct pool_header {
union { block *_padding;
uint count; } ref; /* number of allocated blocks */
block *freeblock; /* pool's free list head */
struct pool_header *nextpool; /* next pool of this size class */
struct pool_header *prevpool; /* previous pool "" */
uint arenaindex; /* index into arenas of base adr */
uint szidx; /* block size class index */
uint nextoffset; /* bytes to virgin block */
uint maxnextoffset; /* largest valid nextoffset */
};
pool_header 作用
與其他pool鏈接, 組成雙向鏈表
2. 維護pool中可用的block, 單鏈表
3. 保存 szidx , 這個和該pool中block的大小有關係, (block size=8, szidx=0), (block size=16, szidx=1)...用於內存分配時匹配到擁有對應大小block的pool
pool 初始化
void *
PyObject_Malloc(size_t nbytes)
{
...
init_pool:
// 1. 連接到 used_pools 雙向鏈表, 作為表頭
// 注意, 這裏 usedpools[0] 保存着 block size = 8 的所有used_pools的表頭
/* Frontlink to used pools. */
next = usedpools[size + size]; /* == prev */
pool->nextpool = next;
pool->prevpool = next;
next->nextpool = pool;
next->prevpool = pool;
pool->ref.count = 1;
// 如果已經初始化過了...這裏看初始化, 跳過
if (pool->szidx == size) {
/* Luckily, this pool last contained blocks
* of the same size class, so its header
* and free list are already initialized.
*/
bp = pool->freeblock;
pool->freeblock = *(block **)bp;
UNLOCK();
return (void *)bp;
}
/*
* Initialize the pool header, set up the free list to
* contain just the second block, and return the first
* block.
*/
// 開始初始化pool_header
// 這裏 size = (uint)(nbytes - 1) >> ALIGNMENT_SHIFT; 其實是Size class idx, 即szidx
pool->szidx = size;
// 計算獲得每個block的size
size = INDEX2SIZE(size);
// 注意 #define POOL_OVERHEAD ROUNDUP(sizeof(struct pool_header))
// bp => 初始化為pool + pool_header size, 跳過pool_header的內存
bp = (block *)pool + POOL_OVERHEAD;
// 計算偏移量, 這裏的偏移量是絕對值
// #define POOL_SIZE SYSTEM_PAGE_SIZE /* must be 2^N */
// POOL_SIZE = 4kb, POOL_OVERHEAD = pool_header size
// 下一個偏移位置: pool_header size + 2 * size
pool->nextoffset = POOL_OVERHEAD + (size << 1);
// 4kb - size
pool->maxnextoffset = POOL_SIZE - size;
// freeblock指向 bp + size = pool_header size + size
pool->freeblock = bp + size;
// 賦值NULL
*(block **)(pool->freeblock) = NULL;
UNLOCK();
return (void *)bp;
}
pool 進行block分配 – 總體代碼
if (pool != pool->nextpool) { //
/*
* There is a used pool for this size class.
* Pick up the head block of its free list.
*/
++pool->ref.count;
bp = pool->freeblock; // 指針指向空閑block起始位置
assert(bp != NULL);
// 代碼-1
// 調整 pool->freeblock (假設A節點)指向鏈表下一個, 即bp首字節指向的下一個節點(假設B節點) , 如果此時!= NULL
// 表示 A節點可用, 直接返回
if ((pool->freeblock = *(block **)bp) != NULL) {
UNLOCK();
return (void *)bp;
}
// 代碼-2
/*
* Reached the end of the free list, try to extend it.
*/
// 有足夠的空間, 分配一個, pool->freeblock 指向後移
if (pool->nextoffset <= pool->maxnextoffset) {
/* There is room for another block. */
// 變更位置信息
pool->freeblock = (block*)pool +
pool->nextoffset;
pool->nextoffset += INDEX2SIZE(size);
*(block **)(pool->freeblock) = NULL; // 注意, 指向NULL
UNLOCK();
// 返回bp
return (void *)bp;
}
// 代碼-3
/* Pool is full, unlink from used pools. */ // 滿了, 需要從下一個pool獲取
next = pool->nextpool;
pool = pool->prevpool;
next->prevpool = pool;
pool->nextpool = next;
UNLOCK();
return (void *)bp;
}
pool進行block分配 -1
內存塊尚未分配完, 且此時不存在回收的block, 全新進來的時候, 分配第一塊block
(pool->freeblock = *(block **)bp) == NULL
當進入代碼邏輯2時,表示有空閑的block, 代碼2的執行流程圖如下
pool進行block分配 – 2 回收了某幾個block
回收涉及的代碼:
void
PyObject_Free(void *p)
{
poolp pool;
block *lastfree;
poolp next, prev;
uint size;
pool = POOL_ADDR(p);
if (Py_ADDRESS_IN_RANGE(p, pool)) {
/* We allocated this address. */
LOCK();
/* Link p to the start of the pool's freeblock list. Since
* the pool had at least the p block outstanding, the pool
* wasn't empty (so it's already in a usedpools[] list, or
* was full and is in no list -- it's not in the freeblocks
* list in any case).
*/
assert(pool->ref.count > 0); /* else it was empty */
// p被釋放, p的第一個字節值被設置為當前freeblock的值
*(block **)p = lastfree = pool->freeblock;
// freeblock被更新為指向p的首地址
pool->freeblock = (block *)p;
// 相當於往list中頭插入了一個節點
...
}
}
每釋放一個block,該blcok就會變成pool->freeblock的頭結點, 假設已經連續分配了5塊, 第1塊和第4塊被釋放,此時的內存圖示如下:
此時再一個block分配調用進來, 執行分配, 進入的邏輯是代碼-1
bp = pool->freeblock; // 指針指向空閑block起始位置
// 代碼-1
// 調整 pool->freeblock (假設A節點)指向鏈表下一個, 即bp首字節指向的下一個節點(假設B節點) , 如果此時!= NULL
// 表示 A節點可用, 直接返回
if ((pool->freeblock = *(block **)bp) != NULL) {
UNLOCK();
return (void *)bp;
}
pool進行block分配 – 3 pool用完了
pool中內存空間都用完了, 進入代碼-3
/* Pool is full, unlink from used pools. */ // 滿了, 需要從下一個pool獲取
next = pool->nextpool;
pool = pool->prevpool;
next->prevpool = pool;
pool->nextpool = next;
UNLOCK();
return (void *)bp;
Python 內存分配策略之-arena
arena: 多個pool聚合的結果, 可放置64個pool
#define ARENA_SIZE (256 << 10) /* 256KB */
arena結構
一個完整的arena = arena_object + pool集合
/* Record keeping for arenas. */
struct arena_object {
/* The address of the arena, as returned by malloc. Note that 0
* will never be returned by a successful malloc, and is used
* here to mark an arena_object that doesn't correspond to an
* allocated arena.
*/
uintptr_t address;
/* Pool-aligned pointer to the next pool to be carved off. */
block* pool_address;
/* The number of available pools in the arena: free pools + never-
* allocated pools.
*/
uint nfreepools;
/* The total number of pools in the arena, whether or not available. */
uint ntotalpools;
/* Singly-linked list of available pools. */
struct pool_header* freepools;
/* Whenever this arena_object is not associated with an allocated
* arena, the nextarena member is used to link all unassociated
* arena_objects in the singly-linked `unused_arena_objects` list.
* The prevarena member is unused in this case.
*
* When this arena_object is associated with an allocated arena
* with at least one available pool, both members are used in the
* doubly-linked `usable_arenas` list, which is maintained in
* increasing order of `nfreepools` values.
*
* Else this arena_object is associated with an allocated arena
* all of whose pools are in use. `nextarena` and `prevarena`
* are both meaningless in this case.
*/
struct arena_object* nextarena;
struct arena_object* prevarena;
};
arena_object的作用
1. 與其他arena連接, 組成雙向鏈表
2. 維護arena中可用的pool, 單鏈表
- pool_header和管理的blocks內存是一塊連續的內存 => pool_header被申請時,其管理的的block集合的內存一併被申請
uint maxnextoffset; /* largest valid nextoffset */
- arena_object 和其管理的內存是分離的 => arena_object被申請時,其管理的pool集合的內存沒有被申請,而是在某一時刻建立關係的
arena的兩種狀態
/* The head of the singly-linked, NULL-terminated list of available
* arena_objects.
*/
// 單鏈表
static struct arena_object* unused_arena_objects = NULL;
/* The head of the doubly-linked, NULL-terminated at each end, list of
* arena_objects associated with arenas that have pools available.
*/
// 雙向鏈表
static struct arena_object* usable_arenas = NULL;
arena 初始化
* Allocate a new arena. If we run out of memory, return NULL. Else
* allocate a new arena, and return the address of an arena_object
* describing the new arena. It's expected that the caller will set
* `usable_arenas` to the return value.
*/
static struct arena_object*
new_arena(void)
{
struct arena_object* arenaobj;
uint excess; /* number of bytes above pool alignment */
void *address;
static int debug_stats = -1;
if (debug_stats == -1) {
const char *opt = Py_GETENV("PYTHONMALLOCSTATS");
debug_stats = (opt != NULL && *opt != '\0');
}
if (debug_stats)
_PyObject_DebugMallocStats(stderr);
// 判斷是否需要擴充"未使用"的arena_object列表
if (unused_arena_objects == NULL) {
uint i;
uint numarenas;
size_t nbytes;
/* Double the number of arena objects on each allocation.
* Note that it's possible for `numarenas` to overflow.
*/
// 確定需要申請的個數, 首次初始化, 16, 之後每次翻倍
numarenas = maxarenas ? maxarenas << 1 : INITIAL_ARENA_OBJECTS;
if (numarenas <= maxarenas)
return NULL; /* overflow */
#if SIZEOF_SIZE_T <= SIZEOF_INT
if (numarenas > SIZE_MAX / sizeof(*arenas))
return NULL; /* overflow */
#endif
nbytes = numarenas * sizeof(*arenas);
// 申請內存
arenaobj = (struct arena_object *)PyMem_RawRealloc(arenas, nbytes);
if (arenaobj == NULL)
return NULL;
arenas = arenaobj;
/* We might need to fix pointers that were copied. However,
* new_arena only gets called when all the pages in the
* previous arenas are full. Thus, there are *no* pointers
* into the old array. Thus, we don't have to worry about
* invalid pointers. Just to be sure, some asserts:
*/
assert(usable_arenas == NULL);
assert(unused_arena_objects == NULL);
/* Put the new arenas on the unused_arena_objects list. */
for (i = maxarenas; i < numarenas; ++i) {
arenas[i].address = 0; /* mark as unassociated */
// 新申請的一律為0, 標識着這個arena處於"未使用"
arenas[i].nextarena = i < numarenas - 1 ?
&arenas[i+1] : NULL;
}
// 將其放入unused_arena_objects鏈表中
// unused_arena_objects 為新分配內存空間的開頭
/* Update globals. */
unused_arena_objects = &arenas[maxarenas];
maxarenas = numarenas;
}
/* Take the next available arena object off the head of the list. */
assert(unused_arena_objects != NULL);
// 從unused_arena_objects中, 獲取一個未使用的object
arenaobj = unused_arena_objects;
unused_arena_objects = arenaobj->nextarena; // 更新鏈表
assert(arenaobj->address == 0);
// 申請內存, 256KB, 內存地址賦值給arena的address. 這塊內存可用
address = _PyObject_Arena.alloc(_PyObject_Arena.ctx, ARENA_SIZE);
if (address == NULL) {
/* The allocation failed: return NULL after putting the
* arenaobj back.
*/
arenaobj->nextarena = unused_arena_objects;
unused_arena_objects = arenaobj;
return NULL;
}
arenaobj->address = (uintptr_t)address;
++narenas_currently_allocated;
++ntimes_arena_allocated;
if (narenas_currently_allocated > narenas_highwater)
narenas_highwater = narenas_currently_allocated;
arenaobj->freepools = NULL;
/* pool_address <- first pool-aligned address in the arena
nfreepools <- number of whole pools that fit after alignment */
arenaobj->pool_address = (block*)arenaobj->address;
arenaobj->nfreepools = MAX_POOLS_IN_ARENA;
// 將pool的起始地址調整為系統頁的邊界
// 申請到 256KB, 放棄了一些內存, 而將可使用的內存邊界pool_address調整到了與系統頁對齊
excess = (uint)(arenaobj->address & POOL_SIZE_MASK);
if (excess != 0) {
--arenaobj->nfreepools;
arenaobj->pool_address += POOL_SIZE - excess;
}
arenaobj->ntotalpools = arenaobj->nfreepools;
return arenaobj;
}
從arenas取一個arena進行初始化
arena分配
new一個全新的arena
static void*
pymalloc_alloc(void *ctx, size_t nbytes)
{
// 剛開始沒有可用的arena
if (usable_arenas == NULL) {
// new一個, 作為雙向鏈表的表頭
usable_arenas = new_arena();
if (usable_arenas == NULL) {
UNLOCK();
goto redirect;
}
usable_arenas->nextarena =
usable_arenas->prevarena = NULL;
}
.......
// 從arena中獲取一個pool
pool = (poolp)usable_arenas->pool_address;
assert((block*)pool <= (block*)usable_arenas->address +
ARENA_SIZE - POOL_SIZE);
pool->arenaindex = usable_arenas - arenas;
assert(&arenas[pool->arenaindex] == usable_arenas);
pool->szidx = DUMMY_SIZE_IDX;
// 更新 pool_address 向下一個節點
usable_arenas->pool_address += POOL_SIZE;
// 可用節點數量-1
--usable_arenas->nfreepools;
}
從全新的arena中獲取一個pool
假設arena是舊的, 怎麼分配的pool, 跟pool分配block原理一樣,使用單鏈表記錄freepools
pool = usable_arenas->freepools;
if (pool != NULL) {
當arena中一整塊pool被釋放的時候
/* Free a memory block allocated by pymalloc_alloc().
Return 1 if it was freed.
Return 0 if the block was not allocated by pymalloc_alloc(). */
static int
pymalloc_free(void *ctx, void *p) {
struct arena_object* ao;
uint nf; /* ao->nfreepools */
/* Link the pool to freepools. This is a singly-linked
* list, and pool->prevpool isn't used there.
*/
ao = &arenas[pool->arenaindex];
pool->nextpool = ao->freepools;
ao->freepools = pool;
nf = ++ao->nfreepools;
}
在pool整塊被釋放的時候, 會將pool加入到arena->freepools作為單鏈表的表頭, 然後, 在從非全新arena中分配pool時, 優先從arena->freepools裏面取, 如果取不到, 再從arena內存塊裏面獲取
注: 上圖中nfreepools = n – 2
當arena1用完了,獲取arena1指向的下一個節點arena2
static void*
pymalloc_alloc(void *ctx, size_t nbytes)
{
// 當發現用完了最後一個pool!!!!!!!!!!!
// nfreepools = 0
if (usable_arenas->nfreepools == 0) {
assert(usable_arenas->nextarena == NULL ||
usable_arenas->nextarena->prevarena ==
usable_arenas);
/* Unlink the arena: it is completely allocated. */
// 找到下一個節點!
usable_arenas = usable_arenas->nextarena;
// 右下一個
if (usable_arenas != NULL) {
usable_arenas->prevarena = NULL; // 更新下一個節點的prevarens
assert(usable_arenas->address != 0);
}
// 沒有下一個, 此時 usable_arenas = NULL, 下次進行內存分配的時候, 就會從arenas數組中取一個
}
}
注意: 這裡有個邏輯, 就是每分配一個pool, 就檢查是不是用到了最後一個, 如果是, 需要變更usable_arenas到下一個可用的節點, 如果沒有可用的, 那麼下次進行內存分配的時候, 會判定從arenas數組中取一個
arena回收
內存分配和回收最小單位是block, 當一個block被回收的時候, 可能觸發pool被回收, pool被回收, 將會觸發arena的回收機制
-
- arena中所有pool都是閑置的(empty), 將arena內存釋放, 返回給操作系統
-
- 如果arena中之前所有的pool都是佔用的(used), 現在釋放了一個pool(empty), 需要將 arena加入到usable_arenas, 會加入鏈表表頭
-
- 如果arena中empty的pool個數n, 則從useable_arenas開始尋找可以插入的位置. 將arena插入. (useable_arenas是一個有序鏈表, 按empty pool的個數, 保證empty pool數量越多, 被使用的幾率越小, 最終被整體釋放的機會越大)
內存分配的步驟
關注點:如何尋找到一塊可用的nbytes的blcok內存?
pool = usedpools[size + size]
if pool:
pool 沒滿,取一個blcok返回
pool 滿了,從下一個pool取一個blcok返回
else:
獲取arena, 从里面初始化一個pool, 拿到第一個blcok返回
進行內存分配和銷毀, 所有操作都是在pool上進行的
問題: pool中所有block的size一樣, 但是在arena中, 每個pool的size都可能不一樣, 那麼最終這些pool是怎麼維護的? 怎麼根據大小找到需要的block所在的pool? => usedpools
pool在內存池中的三種狀態
- used狀態:pool中至少有一個block已經被使用,並且至少有一個block未被使用,這種狀態的pool受控於Python內部維護的usedpool數組
- full狀態:pool中所有的block都已經被使用,這種狀態的pool在arena中, 但不在arena的freepools鏈表中,處於full的pool各自獨立, 不會被鏈表維護起來
- empty狀態:pool中所有的blcok都未被使用,處於這個狀態的pool的集合通過其pool_header中的nextpool構成一個鏈表,鏈表的表頭示arena_object中的freepools
Python內部維護的usedpools數組是一個非常巧妙的實現,維護着所有的處於used狀態的pool,當申請內存時,python就會通過usedpools尋找到一個可用的pool(處於used狀態),從中分配一個block。因此我們想,一定有一個usedpools相關聯的機制,完成從申請的內存的大小到size class index之間的轉換,否則python就無法找到最合適的pool了。這種機制和usedpools的結構有着密切的關係,我們看一下它的結構
usedpools
usedpools數組: 維護着所有處於used狀態的pool, 當申請內存的時候, 會通過usedpools尋找到一塊可用的(處於used狀態的)pool, 從中分配一個block。
//obmalloc.c
typedef uint8_t block;
#define PTA(x) ((poolp )((uint8_t *)&(usedpools[2*(x)]) - 2*sizeof(block *)))
#define PT(x) PTA(x), PTA(x)
//在我當前的機器就是512/8=64個,對應的size class index就是從0到63
#define NB_SMALL_SIZE_CLASSES (SMALL_REQUEST_THRESHOLD / ALIGNMENT)
static poolp usedpools[2 * ((NB_SMALL_SIZE_CLASSES + 7) / 8) * 8] = {
PT(0), PT(1), PT(2), PT(3), PT(4), PT(5), PT(6), PT(7)
#if NB_SMALL_SIZE_CLASSES > 8
, PT(8), PT(9), PT(10), PT(11), PT(12), PT(13), PT(14), PT(15)
#if NB_SMALL_SIZE_CLASSES > 16
, PT(16), PT(17), PT(18), PT(19), PT(20), PT(21), PT(22), PT(23)
#if NB_SMALL_SIZE_CLASSES > 24
, PT(24), PT(25), PT(26), PT(27), PT(28), PT(29), PT(30), PT(31)
#if NB_SMALL_SIZE_CLASSES > 32
, PT(32), PT(33), PT(34), PT(35), PT(36), PT(37), PT(38), PT(39)
#if NB_SMALL_SIZE_CLASSES > 40
, PT(40), PT(41), PT(42), PT(43), PT(44), PT(45), PT(46), PT(47)
#if NB_SMALL_SIZE_CLASSES > 48
, PT(48), PT(49), PT(50), PT(51), PT(52), PT(53), PT(54), PT(55)
#if NB_SMALL_SIZE_CLASSES > 56
, PT(56), PT(57), PT(58), PT(59), PT(60), PT(61), PT(62), PT(63)
#if NB_SMALL_SIZE_CLASSES > 64
#error "NB_SMALL_SIZE_CLASSES should be less than 64"
#endif /* NB_SMALL_SIZE_CLASSES > 64 */
#endif /* NB_SMALL_SIZE_CLASSES > 56 */
#endif /* NB_SMALL_SIZE_CLASSES > 48 */
#endif /* NB_SMALL_SIZE_CLASSES > 40 */
#endif /* NB_SMALL_SIZE_CLASSES > 32 */
#endif /* NB_SMALL_SIZE_CLASSES > 24 */
#endif /* NB_SMALL_SIZE_CLASSES > 16 */
#endif /* NB_SMALL_SIZE_CLASSES > 8 */
};
如果正在申請28字節, python首先會獲取(size class index) size = (uint )(nbytes - 1) >> ALIGNMENT_SHIFT 顯然這裏size=3, 那麼在usedpools中,尋找第3+3=6個元素,發現usedpools[6]的值是指向usedpools[4]的地址
//obmalloc.c
/* Pool for small blocks. */
struct pool_header {
union { block *_padding;
uint count; } ref; /* 當然pool裏面的block數量 */
block *freeblock; /* 一個鏈表,指向下一個可用的block */
struct pool_header *nextpool; /* 指向下一個pool */
struct pool_header *prevpool; /* 指向上一個pool "" */
uint arenaindex; /* 在area裏面的索引 */
uint szidx; /* block的大小(固定值?後面說) */
uint nextoffset; /* 下一個可用block的內存偏移量 */
uint maxnextoffset; /* 最後一個block距離開始位置的距離 */
};
顯然是從usedpools[6](即usedpools+4)開始向後偏移8個字節(一個ref的大小加上一個freeblock的大小)后的內存,正好是usedpools[6]的地址(即usedpools+6),這是python內部的trick
當我們要申請一個size class為32字節的pool,想要將其放入這個usedpools中時,要怎麼做呢?從上面的描述我們知道,只需要進行usedpools[i+i] -> nextpool = pool即可,其中i為size class index,對應於32字節,這個i為3.當下次需要訪問size class 為32字節(size class index為3)的pool時,只需要簡單地訪問usedpools[3+3]就可以得到了。python正是使用這個usedpools快速地從眾多的pool中快速地尋找到一個最適合當前內存需求的pool,從中分配一塊block。
//obmalloc.c
static int
pymalloc_alloc(void *ctx, void **ptr_p, size_t nbytes)
{
block *bp;
poolp pool;
poolp next;
uint size;
...
LOCK();
//獲得size class index
size = (uint)(nbytes - 1) >> ALIGNMENT_SHIFT;
//直接通過usedpools[size+size],這裏的size不就是我們上面說的i嗎?
pool = usedpools[size + size];
//如果usedpools中有可用的pool
if (pool != pool->nextpool) {
... //有可用pool
}
... //無可用pool,嘗試獲取empty狀態的pool
}
內存池全局結構
參考:
pyhton源碼閱讀-內存管理機制
python源碼解析第17章-python內存管理與垃圾回收
後期查缺補漏需要看的文章
Memory management by Zpoint
Memory management in Python
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※想知道最厲害的網頁設計公司"嚨底家"!
※別再煩惱如何寫文案,掌握八大原則!
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※回頭車貨運收費標準
※台中搬家公司費用怎麼算?