之前寫過一篇:本來是用來閑來分享一下自己的思維方式,時至今日發現居然有些人正在使用了,本着對代碼負責人的態度,對代碼部分已知bug進行了修改,並增加了若干功能,如立即啟動,實時停止等功能,新增加的功能會在這一篇做詳細的說明。
提到分佈式任務調度,市面上本身已經有一些框架工具可以使用,但是個人覺得功能做的都太豐富,架構都過於複雜,所以才有了我重複造輪子。個人喜歡把複雜的問題簡單化,利用有限的資源實現竟可能多的功能。因為有幾個朋友問部署方式,這裏再次強調下:我的這個服務可以直接打成jar放在自己本地倉庫,然後依賴進去,或者直接copy代碼過去,當成自己項目的一部分就可以了。也就是說跟隨你們自己的項目啟動,所以我這裏也沒有寫界面。下面先談談怎麼基於上次的代碼實現任務立即啟動吧!
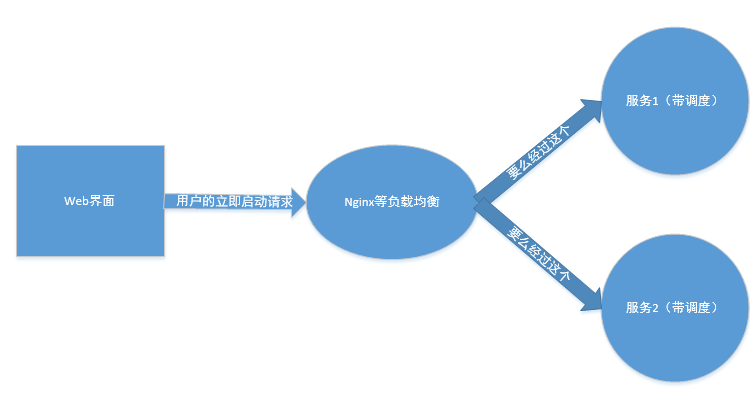
調度和自己服務整合後部署圖抽象成如下:
用戶在前端點擊立即請求按鈕,通過各種負載均衡軟件或者設備,到達某台機器的某個帶有本調度框架的服務,然後進行具體的執行,也就是說這個立即啟動就是一個最常見最簡單的請求,沒有過多複雜的問題(比如多節點會不會重複執行這些)。最簡單的辦法,當用戶請求過來直接用一個線程或者線程池執行用戶點的那個任務的邏輯代碼就行了,當然我這裏沒有那麼粗暴,現有的調度代碼資源如下:
package com.rdpaas.task.scheduler; import com.rdpaas.task.common.Invocation; import com.rdpaas.task.common.Node; import com.rdpaas.task.common.NotifyCmd; import com.rdpaas.task.common.Task; import com.rdpaas.task.common.TaskDetail; import com.rdpaas.task.common.TaskStatus; import com.rdpaas.task.config.EasyJobConfig; import com.rdpaas.task.repository.NodeRepository; import com.rdpaas.task.repository.TaskRepository; import com.rdpaas.task.strategy.Strategy; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Component; import javax.annotation.PostConstruct; import java.util.Date; import java.util.HashMap; import java.util.List; import java.util.Map; import java.util.concurrent.ArrayBlockingQueue; import java.util.concurrent.Callable; import java.util.concurrent.DelayQueue; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; import java.util.concurrent.Future; import java.util.concurrent.ThreadPoolExecutor; import java.util.concurrent.TimeUnit; /** * 任務調度器 * @author rongdi * @date 2019-03-13 21:15 */ @Component public class TaskExecutor { private static final Logger logger = LoggerFactory.getLogger(TaskExecutor.class); @Autowired private TaskRepository taskRepository; @Autowired private NodeRepository nodeRepository; @Autowired private EasyJobConfig config; /** * 創建任務到期延時隊列 */ private DelayQueue<DelayItem<Task>> taskQueue = new DelayQueue<>(); /** * 可以明確知道最多只會運行2個線程,直接使用系統自帶工具就可以了 */ private ExecutorService bossPool = Executors.newFixedThreadPool(2); /** * 正在執行的任務的Future */ private Map<Long,Future> doingFutures = new HashMap<>(); /** * 聲明工作線程池 */ private ThreadPoolExecutor workerPool; /** * 獲取任務的策略 */ private Strategy strategy; @PostConstruct public void init() { /** * 根據配置選擇一個節點獲取任務的策略 */ strategy = Strategy.choose(config.getNodeStrategy()); /** * 自定義線程池,初始線程數量corePoolSize,線程池等待隊列大小queueSize,當初始線程都有任務,並且等待隊列滿后 * 線程數量會自動擴充最大線程數maxSize,當新擴充的線程空閑60s后自動回收.自定義線程池是因為Executors那幾個線程工具 * 各有各的弊端,不適合生產使用 */ workerPool = new ThreadPoolExecutor(config.getCorePoolSize(), config.getMaxPoolSize(), 60, TimeUnit.SECONDS, new ArrayBlockingQueue<>(config.getQueueSize())); /** * 執行待處理任務加載線程 */ bossPool.execute(new Loader()); /** * 執行任務調度線程 */ bossPool.execute(new Boss()); } class Loader implements Runnable { @Override public void run() { for(;;) { try { /** * 先獲取可用的節點列表 */ List<Node> nodes = nodeRepository.getEnableNodes(config.getHeartBeatSeconds() * 2); if(nodes == null || nodes.isEmpty()) { continue; } /** * 查找還有指定時間(單位秒)才開始的主任務列表 */ List<Task> tasks = taskRepository.listNotStartedTasks(config.getFetchDuration()); if(tasks == null || tasks.isEmpty()) { continue; } for(Task task:tasks) { boolean accept = strategy.accept(nodes, task, config.getNodeId()); /** * 不該自己拿就不要搶 */ if(!accept) { continue; } /** * 先設置成待執行 */ task.setStatus(TaskStatus.PENDING); task.setNodeId(config.getNodeId()); /** * 使用樂觀鎖嘗試更新狀態,如果更新成功,其他節點就不會更新成功。如果其它節點也正在查詢未完成的 * 任務列表和當前這段時間有節點已經更新了這個任務,version必然和查出來時候的version不一樣了,這裏更新 * 必然會返回0了 */ int n = taskRepository.updateWithVersion(task); Date nextStartTime = task.getNextStartTime(); if(n == 0 || nextStartTime == null) { continue; } /** * 封裝成延時對象放入延時隊列,這裏再查一次是因為上面樂觀鎖已經更新了版本,會導致後面結束任務更新不成功 */ task = taskRepository.get(task.getId()); DelayItem<Task> delayItem = new DelayItem<Task>(nextStartTime.getTime() - new Date().getTime(), task); taskQueue.offer(delayItem); } Thread.sleep(config.getFetchPeriod()); } catch(Exception e) { logger.error("fetch task list failed,cause by:{}", e); } } } } class Boss implements Runnable { @Override public void run() { for (;;) { try { /** * 時間到了就可以從延時隊列拿出任務對象,然後交給worker線程池去執行 */ DelayItem<Task> item = taskQueue.take(); if(item != null && item.getItem() != null) { Task task = item.getItem(); /** * 真正開始執行了設置成執行中 */ task.setStatus(TaskStatus.DOING); /** * loader線程中已經使用樂觀鎖控制了,這裏沒必要了 */ taskRepository.update(task); /** * 提交到線程池 */ Future future = workerPool.submit(new Worker(task)); /** * 暫存在doingFutures */ doingFutures.put(task.getId(),future); } } catch (Exception e) { logger.error("fetch task failed,cause by:{}", e); } } } } class Worker implements Callable<String> { private Task task; public Worker(Task task) { this.task = task; } @Override public String call() { logger.info("Begin to execute task:{}",task.getId()); TaskDetail detail = null; try { //開始任務 detail = taskRepository.start(task); if(detail == null) return null; //執行任務 task.getInvokor().invoke(); //完成任務 finish(task,detail); logger.info("finished execute task:{}",task.getId()); /** * 執行完后刪了 */ doingFutures.remove(task.getId()); } catch (Exception e) { logger.error("execute task:{} error,cause by:{}",task.getId(), e); try { taskRepository.fail(task,detail,e.getCause().getMessage()); } catch(Exception e1) { logger.error("fail task:{} error,cause by:{}",task.getId(), e); } } return null; } } /** * 完成子任務,如果父任務失敗了,子任務不會執行 * @param task * @param detail * @throws Exception */ private void finish(Task task,TaskDetail detail) throws Exception { //查看是否有子類任務 List<Task> childTasks = taskRepository.getChilds(task.getId()); if(childTasks == null || childTasks.isEmpty()) { //當沒有子任務時完成父任務 taskRepository.finish(task,detail); return; } else { for (Task childTask : childTasks) { //開始任務 TaskDetail childDetail = null; try { //將子任務狀態改成執行中 childTask.setStatus(TaskStatus.DOING); childTask.setNodeId(config.getNodeId()); //開始子任務 childDetail = taskRepository.startChild(childTask,detail); //使用樂觀鎖更新下狀態,不然這裏可能和恢複線程產生併發問題 int n = taskRepository.updateWithVersion(childTask); if (n > 0) { //再從數據庫取一下,避免上面update修改后version不同步 childTask = taskRepository.get(childTask.getId()); //執行子任務 childTask.getInvokor().invoke(); //完成子任務 finish(childTask, childDetail); } } catch (Exception e) { logger.error("execute child task error,cause by:{}", e); try { taskRepository.fail(childTask, childDetail, e.getCause().getMessage()); } catch (Exception e1) { logger.error("fail child task error,cause by:{}", e); } } } /** * 當有子任務時完成子任務后再完成父任務 */ taskRepository.finish(task,detail); } } /** * 添加任務 * @param name * @param cronExp * @param invockor * @return * @throws Exception */ public long addTask(String name, String cronExp, Invocation invockor) throws Exception { Task task = new Task(name,cronExp,invockor); return taskRepository.insert(task); } /** * 添加子任務 * @param pid * @param name * @param cronExp * @param invockor * @return * @throws Exception */ public long addChildTask(Long pid,String name, String cronExp, Invocation invockor) throws Exception { Task task = new Task(name,cronExp,invockor); task.setPid(pid); return taskRepository.insert(task); } }
上面主要就是三組線程,Loader負責加載將要執行的任務放入本地的任務隊列,Boss線程負責取出任務隊列的任務,然後分配Worker線程池的一個線程去執行。由上面的代碼可以看到如果要立即執行,其實只需要把一個延時為0的任務放入任務隊列,等着Boss線程去取然後分配給worker執行就可以實現了,代碼如下:
/** * 立即執行任務,就是設置一下延時為0加入任務隊列就好了,這個可以外部直接調用 * @param taskId * @return */ public boolean startNow(Long taskId) { Task task = taskRepository.get(taskId); task.setStatus(TaskStatus.DOING); taskRepository.update(task); DelayItem<Task> delayItem = new DelayItem<Task>(0L, task); return taskQueue.offer(delayItem); }
啟動不用再多說,下面介紹一下停止任務,根據面向對象的思維,用戶要想停止一個任務,最終執行停止任務的就是正在執行任務的那個節點。停止任務有兩種情況,第一種任務沒有正在運行如何停止,第二種是任務正在運行如何停止。第一種其實直接改變一下任務對象的狀態為停止就行了,不必多說。下面主要考慮如何停止正在運行的任務,細心的朋友可能已經發現上面代碼和之前那一篇代碼有點區別,之前用的Runnble作為線程實現接口,這個用了Callable,其實在java中停止線程池中正在運行的線程最常用的就是直接調用future的cancel方法了,要想獲取到這個future對象就需要將以前實現Runnbale改成實現Callable,然後提交到線程池由execute改成submit就可以了,然後每次提交到線程池得到的future對象使用taskId一起保存在一個map中,方便根據taskId隨時找到。當然任務執行完后要及時刪除這個map里的任務,以免常駐其中導致內存溢出。停止任務的請求流程如下
圖還是原來的圖,但是這時候情況不一樣了,因為停止任務的時候假如當前正在執行這個任務的節點處於服務1,負載均衡是不知道要去把你引到服務1的,他可能會引入到服務2,那就悲劇了,所以通用的做法就是停止請求過來不管落到哪個節點上,那個節點就往一個公用的mq上發一個帶有停止任務業務含義的消息,各個節點訂閱這個消息,然後判斷都判斷任務在不在自己這裏執行,如果在就執行停止操作。但是這樣勢必讓我們的調度服務又要依賴一個外部的消息隊列服務,就算很方便的就可以引入一個外部的消息隊列,但是你真的可以駕馭的了嗎,消息丟了咋辦,重複發送了咋辦,消息服務掛了咋辦,網絡斷了咋辦,又引入了一大堆問題,那我是不是又要寫n篇文章來分別解決這些問題。往往現實卻是就是這麼殘酷,你解決了一個問題,引入了更多的問題,這就是為什麼bug永遠改不完的道理了。當然這不是我的風格,我的風格是利用有限的資源做盡可能多的事情(可能是由於我工作的企業都是那種資源貧瘠的,養成了我這種習慣,土豪公司的程序員請繞道,哈哈)。
簡化一下問題:目前的問題就是如何讓正在執行任務的節點知道,然後停止正在執行的這個任務,其實就是這個停止通知如何實現。這不免讓我想起了12306網站上買票,其實我們作為老百姓多麼希望12306可以在有票的時候發個短信通知一下我們,然後我們上去搶,但是現實卻是,你要麼使用軟件一直刷,要麼是自己隔一段時間上去瞄一下有沒有票。如果把有票了給我們發短信通知定義為異步通知,那麼這種我們要隔一段時間自己去瞄一下的方式就是同步輪訓。這兩種方式都能達到告知的目的,關鍵的區別在於你到底有沒有時間去一直去瞄,不過相比於可以回家,這些時間都是值得的。個人認為軟件的設計其實就是一個權衡是否值得的過程。如果約定了不使用外部消息隊列這種異步通知的方式,那麼我們只能使用同步輪訓的方式了。不過正好我們的任務調度本身已經有一個心跳機制,沒隔一段時間就去更新一下節點狀態,如果我們把用戶的停止請求作為命令信息更新到每個節點的上,然後隨着心跳獲取到這個節點的信息,然後判斷這個命令,做相應的處理是不是就可以完美解決這個問題。值得嗎?很明顯是值得的,我們只是在心跳邏輯上加一個小小的副作用就實現了通知功能了。代碼如下
package com.rdpaas.task.common; /** * @author rongdi * @date 2019/11/26 */ public enum NotifyCmd { //沒有通知,默認狀態 NO_NOTIFY(0), //開啟任務(Task) START_TASK(1), //修改任務(Task) EDIT_TASK(2), //停止任務(Task) STOP_TASK(3); int id; NotifyCmd(int id) { this.id = id; } public int getId() { return id; } public static NotifyCmd valueOf(int id) { switch (id) { case 1: return START_TASK; case 2: return EDIT_TASK; case 3: return STOP_TASK; default: return NO_NOTIFY; } } }
package com.rdpaas.task.handles; import com.rdpaas.task.common.NotifyCmd; import com.rdpaas.task.utils.SpringContextUtil; /** * @author: rongdi * @date: */ public interface NotifyHandler<T> { static NotifyHandler chooseHandler(NotifyCmd notifyCmd) { return SpringContextUtil.getByTypeAndName(NotifyHandler.class,notifyCmd.toString()); } public void update(T t); }
package com.rdpaas.task.handles; import com.rdpaas.task.scheduler.TaskExecutor; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Component; /** * @author: rongdi * @date: */ @Component("STOP_TASK") public class StopTaskHandler implements NotifyHandler<Long> { @Autowired private TaskExecutor taskExecutor; @Override public void update(Long taskId) { taskExecutor.stop(taskId); } }
class HeartBeat implements Runnable { @Override public void run() { for(;;) { try { /** * 時間到了就可以從延時隊列拿出節點對象,然後更新時間和序號, * 最後再新建一個超時時間為心跳時間的節點對象放入延時隊列,形成循環的心跳 */ DelayItem<Node> item = heartBeatQueue.take(); if(item != null && item.getItem() != null) { Node node = item.getItem(); handHeartBeat(node); } heartBeatQueue.offer(new DelayItem<>(config.getHeartBeatSeconds() * 1000,new Node(config.getNodeId()))); } catch (Exception e) { logger.error("task heart beat error,cause by:{} ",e); } } } } /** * 處理節點心跳 * @param node */ private void handHeartBeat(Node node) { if(node == null) { return; } /** * 先看看數據庫是否存在這個節點 * 如果不存在:先查找下一個序號,然後設置到node對象中,最後插入 * 如果存在:直接根據nodeId更新當前節點的序號和時間 */ Node currNode= nodeRepository.getByNodeId(node.getNodeId()); if(currNode == null) { node.setRownum(nodeRepository.getNextRownum()); nodeRepository.insert(node); } else { nodeRepository.updateHeartBeat(node.getNodeId()); NotifyCmd cmd = currNode.getNotifyCmd(); String notifyValue = currNode.getNotifyValue(); if(cmd != null && cmd != NotifyCmd.NO_NOTIFY) { /** * 藉助心跳做一下通知的事情,比如及時停止正在執行的任務 * 根據指令名稱查找Handler */ NotifyHandler handler = NotifyHandler.chooseHandler(currNode.getNotifyCmd()); if(handler == null || StringUtils.isEmpty(notifyValue)) { return; } /** * 執行操作 */ handler.update(Long.valueOf(notifyValue)); } } }
最終的任務調度代碼如下:
package com.rdpaas.task.scheduler; import com.rdpaas.task.common.Invocation; import com.rdpaas.task.common.Node; import com.rdpaas.task.common.NotifyCmd; import com.rdpaas.task.common.Task; import com.rdpaas.task.common.TaskDetail; import com.rdpaas.task.common.TaskStatus; import com.rdpaas.task.config.EasyJobConfig; import com.rdpaas.task.repository.NodeRepository; import com.rdpaas.task.repository.TaskRepository; import com.rdpaas.task.strategy.Strategy; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Component; import javax.annotation.PostConstruct; import java.util.Date; import java.util.HashMap; import java.util.List; import java.util.Map; import java.util.concurrent.ArrayBlockingQueue; import java.util.concurrent.Callable; import java.util.concurrent.DelayQueue; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; import java.util.concurrent.Future; import java.util.concurrent.ThreadPoolExecutor; import java.util.concurrent.TimeUnit; /** * 任務調度器 * @author rongdi * @date 2019-03-13 21:15 */ @Component public class TaskExecutor { private static final Logger logger = LoggerFactory.getLogger(TaskExecutor.class); @Autowired private TaskRepository taskRepository; @Autowired private NodeRepository nodeRepository; @Autowired private EasyJobConfig config; /** * 創建任務到期延時隊列 */ private DelayQueue<DelayItem<Task>> taskQueue = new DelayQueue<>(); /** * 可以明確知道最多只會運行2個線程,直接使用系統自帶工具就可以了 */ private ExecutorService bossPool = Executors.newFixedThreadPool(2); /** * 正在執行的任務的Future */ private Map<Long,Future> doingFutures = new HashMap<>(); /** * 聲明工作線程池 */ private ThreadPoolExecutor workerPool; /** * 獲取任務的策略 */ private Strategy strategy; @PostConstruct public void init() { /** * 根據配置選擇一個節點獲取任務的策略 */ strategy = Strategy.choose(config.getNodeStrategy()); /** * 自定義線程池,初始線程數量corePoolSize,線程池等待隊列大小queueSize,當初始線程都有任務,並且等待隊列滿后 * 線程數量會自動擴充最大線程數maxSize,當新擴充的線程空閑60s后自動回收.自定義線程池是因為Executors那幾個線程工具 * 各有各的弊端,不適合生產使用 */ workerPool = new ThreadPoolExecutor(config.getCorePoolSize(), config.getMaxPoolSize(), 60, TimeUnit.SECONDS, new ArrayBlockingQueue<>(config.getQueueSize())); /** * 執行待處理任務加載線程 */ bossPool.execute(new Loader()); /** * 執行任務調度線程 */ bossPool.execute(new Boss()); } class Loader implements Runnable { @Override public void run() { for(;;) { try { /** * 先獲取可用的節點列表 */ List<Node> nodes = nodeRepository.getEnableNodes(config.getHeartBeatSeconds() * 2); if(nodes == null || nodes.isEmpty()) { continue; } /** * 查找還有指定時間(單位秒)才開始的主任務列表 */ List<Task> tasks = taskRepository.listNotStartedTasks(config.getFetchDuration()); if(tasks == null || tasks.isEmpty()) { continue; } for(Task task:tasks) { boolean accept = strategy.accept(nodes, task, config.getNodeId()); /** * 不該自己拿就不要搶 */ if(!accept) { continue; } /** * 先設置成待執行 */ task.setStatus(TaskStatus.PENDING); task.setNodeId(config.getNodeId()); /** * 使用樂觀鎖嘗試更新狀態,如果更新成功,其他節點就不會更新成功。如果其它節點也正在查詢未完成的 * 任務列表和當前這段時間有節點已經更新了這個任務,version必然和查出來時候的version不一樣了,這裏更新 * 必然會返回0了 */ int n = taskRepository.updateWithVersion(task); Date nextStartTime = task.getNextStartTime(); if(n == 0 || nextStartTime == null) { continue; } /** * 封裝成延時對象放入延時隊列,這裏再查一次是因為上面樂觀鎖已經更新了版本,會導致後面結束任務更新不成功 */ task = taskRepository.get(task.getId()); DelayItem<Task> delayItem = new DelayItem<Task>(nextStartTime.getTime() - new Date().getTime(), task); taskQueue.offer(delayItem); } Thread.sleep(config.getFetchPeriod()); } catch(Exception e) { logger.error("fetch task list failed,cause by:{}", e); } } } } class Boss implements Runnable { @Override public void run() { for (;;) { try { /** * 時間到了就可以從延時隊列拿出任務對象,然後交給worker線程池去執行 */ DelayItem<Task> item = taskQueue.take(); if(item != null && item.getItem() != null) { Task task = item.getItem(); /** * 真正開始執行了設置成執行中 */ task.setStatus(TaskStatus.DOING); /** * loader線程中已經使用樂觀鎖控制了,這裏沒必要了 */ taskRepository.update(task); /** * 提交到線程池 */ Future future = workerPool.submit(new Worker(task)); /** * 暫存在doingFutures */ doingFutures.put(task.getId(),future); } } catch (Exception e) { logger.error("fetch task failed,cause by:{}", e); } } } } class Worker implements Callable<String> { private Task task; public Worker(Task task) { this.task = task; } @Override public String call() { logger.info("Begin to execute task:{}",task.getId()); TaskDetail detail = null; try { //開始任務 detail = taskRepository.start(task); if(detail == null) return null; //執行任務 task.getInvokor().invoke(); //完成任務 finish(task,detail); logger.info("finished execute task:{}",task.getId()); /** * 執行完后刪了 */ doingFutures.remove(task.getId()); } catch (Exception e) { logger.error("execute task:{} error,cause by:{}",task.getId(), e); try { taskRepository.fail(task,detail,e.getCause().getMessage()); } catch(Exception e1) { logger.error("fail task:{} error,cause by:{}",task.getId(), e); } } return null; } } /** * 完成子任務,如果父任務失敗了,子任務不會執行 * @param task * @param detail * @throws Exception */ private void finish(Task task,TaskDetail detail) throws Exception { //查看是否有子類任務 List<Task> childTasks = taskRepository.getChilds(task.getId()); if(childTasks == null || childTasks.isEmpty()) { //當沒有子任務時完成父任務 taskRepository.finish(task,detail); return; } else { for (Task childTask : childTasks) { //開始任務 TaskDetail childDetail = null; try { //將子任務狀態改成執行中 childTask.setStatus(TaskStatus.DOING); childTask.setNodeId(config.getNodeId()); //開始子任務 childDetail = taskRepository.startChild(childTask,detail); //使用樂觀鎖更新下狀態,不然這裏可能和恢複線程產生併發問題 int n = taskRepository.updateWithVersion(childTask); if (n > 0) { //再從數據庫取一下,避免上面update修改后version不同步 childTask = taskRepository.get(childTask.getId()); //執行子任務 childTask.getInvokor().invoke(); //完成子任務 finish(childTask, childDetail); } } catch (Exception e) { logger.error("execute child task error,cause by:{}", e); try { taskRepository.fail(childTask, childDetail, e.getCause().getMessage()); } catch (Exception e1) { logger.error("fail child task error,cause by:{}", e); } } } /** * 當有子任務時完成子任務后再完成父任務 */ taskRepository.finish(task,detail); } } /** * 添加任務 * @param name * @param cronExp * @param invockor * @return * @throws Exception */ public long addTask(String name, String cronExp, Invocation invockor) throws Exception { Task task = new Task(name,cronExp,invockor); return taskRepository.insert(task); } /** * 添加子任務 * @param pid * @param name * @param cronExp * @param invockor * @return * @throws Exception */ public long addChildTask(Long pid,String name, String cronExp, Invocation invockor) throws Exception { Task task = new Task(name,cronExp,invockor); task.setPid(pid); return taskRepository.insert(task); } /** * 立即執行任務,就是設置一下延時為0加入任務隊列就好了,這個可以外部直接調用 * @param taskId * @return */ public boolean startNow(Long taskId) { Task task = taskRepository.get(taskId); task.setStatus(TaskStatus.DOING); taskRepository.update(task); DelayItem<Task> delayItem = new DelayItem<Task>(0L, task); return taskQueue.offer(delayItem); } /** * 立即停止正在執行的任務,留給外部調用的方法 * @param taskId * @return */ public boolean stopNow(Long taskId) { Task task = taskRepository.get(taskId); if(task == null) { return false; } /** * 該任務不是正在執行,直接修改task狀態為已完成即可 */ if(task.getStatus() != TaskStatus.DOING) { task.setStatus(TaskStatus.STOP); taskRepository.update(task); return true; } /** * 該任務正在執行,使用節點配合心跳發布停用通知 */ int n = nodeRepository.updateNotifyInfo(NotifyCmd.STOP_TASK,String.valueOf(taskId)); return n > 0; } /** * 立即停止正在執行的任務,這個不需要自己調用,是給心跳線程調用 * @param taskId * @return */ public boolean stop(Long taskId) { Task task = taskRepository.get(taskId); /** * 不是自己節點的任務,本節點不能執行停用 */ if(task == null || !config.getNodeId().equals(task.getNodeId())) { return false; } /** * 拿到正在執行任務的future,然後強制停用,並刪除doingFutures的任務 */ Future future = doingFutures.get(taskId); boolean flag = future.cancel(true); if(flag) { doingFutures.remove(taskId); /** * 修改狀態為已停用 */ task.setStatus(TaskStatus.STOP); taskRepository.update(task); } /** * 重置通知信息,避免重複執行停用通知 */ nodeRepository.resetNotifyInfo(NotifyCmd.STOP_TASK); return flag; } }
好吧,其實實現很簡單,關鍵在於思路,不BB了,詳細代碼見: 在下告辭!
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包"嚨底家"
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整