新聞
視頻及幻燈片
博客
F# vNext
- F#語言建議:
GitHub項目
最新的發布
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!

 |
結合智慧能源與智慧交通的新創科技品牌Gogoro(睿能創意股份有限公司)7 日公布全台建置與營運中的GoStation 電池交換站已達400 站,再度創造新的里程碑。從2015 年7 月至今,Gogoro 在基隆到屏東的台灣西半部地區,平均每1.8 天即新增一座電池交換站,最近一個月,每日提供將近4 萬名車主接近17,000 顆的電池交換服務,電池交換服務已經成為台灣消費者購買電動機車時的首要選擇。
自從Gogoro 於2015 年在台北市設立首座電池交換站以來,在短短兩年多的時間,建置了400 座電池交換站,廣布於基隆到屏東的各個縣市,推升Gogoro 電動機車市佔率至85.1%,並穩居台灣機車市場第四名的寶座。在今年7 月開通雲嘉地區電池交換站後,暢騎台灣西半部,不再是夢想。同時六都的電池交換站建置更來到一公里一站。
Gogoro 行銷總監陳彥揚說:「我們會依據人口密集度、車輛密極度以及道路的重要性來建置及調度電池交換站。根據車主換電的大數據分析,換電最密集的電池交換站位於Gogoro 永和中正店,而換電的尖峰時刻不外乎是上、下班的時間。有趣的是,雖然全台已經有將近400 座電池交換站,但每名消費者平均只會造訪其中的3-4 站來更換電池。證明Gogoro 能源網路的大數據分析,能計算出消費者換電池的使用行為模式,滿足車主們的需求。」
走在環保、綠能尖端的Gogoro,目前共建置了兩座太陽能換電站,分別是八里公兒四電池交換站和Gogoro 師大和平店站,這兩站設有物聯網智慧平台,透過分析供電情況的螢幕,說明了包括減少碳排量、減少樹木砍伐面積、綠能總儲電量、城市電網和太陽能發電量等訊息,讓每名換電的民眾,清楚的知道,自己對環境的貢獻度。
陳彥揚說:「Gogoro 致力發展潔淨的智慧能源,希望具備能源調度能力的智慧電網,能成為城市的電力調節樞紐,以促成電力平衡。對於Gogoro 車主而言,Gogoro 不再僅是都會的通勤工具,而是更進一步深入使用者的生活,同時讓生活環境更環保、更健康。」
Gogoro 目前擁有近4 萬名車主,總共累積超過570 萬次的電池交換,總里程數超過1 億100 公里,已經替地球減少將近840 萬公斤的二氧化碳排放,隨著未來再生能源比例逐漸提升,Gogoro 的車主們將更對地球與環境產生更多正面的影響力。而Gogoro 更會透過大數據進行科學的規劃,以調控電池供應,未來,即便新增的萬名車主同步上路,也能確保能源及電池的調配無虞。
(合作媒體:。圖片出處:科技新報)
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益
2017年11月16-17日∣中國·上海
人–車–路協同發展創造全面感知新時代
隨著電子、資訊、通信、人工智慧等技術與汽車產業加速融合,汽車產品正加快向智慧化、網聯化方向發展。因此,智慧網聯汽車面臨的資訊安全挑戰也備受業界關注。
頂層設計政策體系為智慧網聯汽車的發展創建了良好的發展環境,與此相關的大資料、雲計算、人工智慧等也在持續提供著技術保障。與此同時,一個較為顯著的問題是,汽車的網聯化也極有可能徹底打開了駭客入侵智慧網聯汽車的通道。智慧網聯汽車與外部的每個介面都可能被惡意利用,每個控制單元都可能被駭客攻擊、病毒感染,智慧網聯汽車的資訊安全防護難度也因之而倍增。
第二屆中國國際智慧網聯汽車論壇將針對智慧網聯汽車資訊安全問題定向邀請包括騰訊科恩實驗室,360奇虎,梆梆安全,中國移動,中國聯通等行業內權威人士對於車聯網資訊安全問題進行更深層次的解析。此次論壇將涉及3個論壇,參觀考察及晚宴,共將有300位行業人士一起,對智慧網聯汽車發展面臨的挑戰、機遇與對策各方面進行為期兩天更深層次並具有建設和戰略性的探討。
會議亮點
Ø 豐富的內容:3大論壇的深度解析
Ø 參會嘉賓:300+高度滿意的企業決策者,160+業內知名企業,40+國家和地區
Ø 演講嘉賓:30+世界新能源汽車行業知名發言嘉賓
Ø 會議形式:3個論壇,2天會議,1個晚宴
會議結構
|
論壇一:智慧網聯汽車發展趨勢分析及國內外項目解析和智慧交通發展 |
|
論壇二:車載通訊資訊技術及車聯網未來發展 |
|
² 迎合中國製造2025,促進智慧網聯汽車發展之路 ² 智慧汽車、車聯網、車載資訊服務:點、線、網、面的格局與階段 ² 智慧汽車技術創新革命 ² 智慧交通/汽車發展不同階段的分析 ² 國際智慧交通與智慧駕駛的銜接發展 |
|
² 車載半導體的機遇與挑戰 ² 車聯網最新技術探討 ² 4G通信在車載行業的應用 ² 分時租賃-建造全民共用汽車 ² 移動互聯網運營與智慧汽車的融合 |
|
論壇三:智慧汽車ADAS駕駛輔助系統和智慧駕駛技術 |
|
考察活動:2017年11月15日 |
|
² ADAS與智慧駕駛解決方案探討 ² ADAS駕駛輔助系統性能及匹配測試 ² 駕駛輔助系統雷達與感測器的核心技術 ² 高精准地圖對於智慧駕駛的重要性 ² 汽車人機交互對於智慧駕駛的重要性及發展展望 |
|
1.參觀上海天合汽車安全系統有限公司 2.參觀上海智慧網聯汽車試點示範區-中國首家(已預訂,如無測試企業屆時即可參觀) |
若您對峰會有更多要求,請撥打021-6093 0815與我們聯繫,謝謝理解和支持!
我們期待與貴單位一起出席於2017年11月16日-17日在上海舉辦的第二屆中國國際智慧網聯汽車論壇2017,以利決策!
欲知更多會議詳情,請登陸官方網站:http://www.ourpolaris.com/2017/icv/index_c.html
連絡人:Latika LIU(劉小姐)
電話:021-6093 0815
傳真:021-6047 5887
郵箱:
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
※智慧手機時代的來臨,RWD網頁設計已成為網頁設計推薦首選

二哥,你好,我想知道一般程序猿都如何接私活,我也想接,能告訴我一些方法嗎?
上面是一個讀者“煩不煩”問我的一個問題。其實不止是“煩不煩”,還有很多讀者問過我類似這樣的問題。
我接的私活不算多,掙到的錢也沒有多少,加起來不到 20W。說實話,這個數目說出來我是有點心虛的,畢竟太少了,大家輕噴。但我想,恰好配得上“一般程序員”這個稱號啊。畢竟蒼蠅再小也是肉,我也算是有經驗的人了。
唾棄接私活、做外包的程序員有很多很多,曾經高傲的我也嫌棄過。但沒辦法,為了掙點零花錢,我垂下了高昂的頭。記得有位朋友曾說過,當年沈從文為了生計,寫了很多稱不上他自己喜歡的文字給報刊。
聽朋友這麼一說,我也不再覺得“接私活”是多麼一件值得羞愧的事情了。人首先要活着,才有體力講情懷啊。好了,言歸正傳,我來替“煩不煩”同學介紹幾個容易上手的操作。
大體上,天底下做生意都只有一條捷徑:從熟人下手。
“哥們,聽說你有個朋友是做程序員的,我這有台電腦不知道為啥黑屏了,能問問他知道什麼原因嗎?要是能修好,保准請你吃頓大餐。”
“老弟啊,我有一個朋友說最近流行炒鞋,我想你不是程序員嘛,找你最合適了,要不我把他推薦給你,談成的話給我發個紅包就行了。”
我的第一個私活,就是之前在蘇州的一個同事介紹的。不過最後黃了。我搞了兩周時間(技術框架用的 JEPF),同事說甲方換方案了,沒把我氣壞。
同事礙於情面,說有機會請我吃頓飯。這一等就是 3 年,3 年過去了,飯還是沒有吃到。主要是因為我這位朋友在蘇州,我在洛陽,吃飯是沒辦法遠程完成啊。
第二個私活,是之前在蘇州的一個領導介紹的。由同事升級為領導,多少靠譜了點。這次做的是蘇州相城區的一個电子商務網站。前後做了三個多月,最後拿到手的錢也就不到一萬塊錢。
現在感覺自己當時是在出售廉價勞動力,何止是廉價,簡直是公益事業。不過,第一次接私活,拿到錢買了個華為的 MateBook,真香。
第二個私活做完后,領導可能覺得虧待了我,良心難安,就介紹了第三個私活給我。這次蠻輕鬆的,一個月搞定,還不累,兩萬塊到手。
既然是私活,當然都是利用業餘時間做的。這個投入的成本和實際得到的回報是一定要考慮的。
我第一個私活打了水漂,辛苦了兩周,零回報。不過,這也是接私活常有的事,需要用平常心來對待。
第二個私活說實話非常辛苦,有幾次熬到半夜兩三點,當時覺得太不划算了。但當初自己接了,就只能忍着拼到底。畢竟咱是敬業愛崗的好同志。
第三個私活就相對輕鬆多了,單位時間內的收益非常高,算下來一個小時有 500 的工時費吧,就彷彿是對前兩個的補償。
總結一下,朋友介紹的項目相對來說還是比較靠譜的,前提條件是要有一定的“人情世故”原始成本積累。如果我當時在蘇州表現得不夠優異,和同事、領導的關係相處的不夠融洽,那自然他們也不會時隔多年後再找到我。
記住一點,做事的同時要好好的做人。當你既有能力,又值得信任的時候,私活就會找上門來。
既然是朋友,自然就不會有很多。也就意味着,單純依賴朋友介紹的私活來源是有限度的。那如果想接更多的私活,該怎麼辦呢?
這就需要個人品牌了。
我平常不是喜歡寫作嘛,分享了很多技術文章在各大平台上,瀏覽量還算不錯。博客園上的排名和瀏覽量都能拿得出手。
博客地址:
當你做了一件事,並且一直在堅持,況且還做出了一定的成績,自然就會有生意主動找上門來——花香蜂自來嘛。
寫博客的好處有很多,比如說吸引一批忠實的讀者,他們追隨你的文字,喜歡你的風格;再比如說勾引一些出版社,他們欣賞你的文字,願意合作互利共贏。
最後,還會有一些做私活的甲方。以前,我總覺得這是不可能發生的事情,他們是怎麼找到我的?很不可思議,但互聯網就是這麼神奇,你覺得不可能,它卻悄悄地發生着。
第一個通過這個途徑找到我的甲方,姓康。康哥找到我后,一上來就對我一頓吹捧(甭管是真是假)。信任建立起來后,他就說自己在醞釀一個很牛逼的項目,看我有沒有意向一起做。
然後呢,承諾項目成功后,再給我一定數額的獎勵金,並且寫到了合同里。吃完他這個大餅,我很飽,忍不住打了好幾個嗝。
再然後,我們就開始整理需求,然後我出報價,他再砍價;他再提需求,我再加價。最後呢,項目總款談到 7.5 萬,兩個多月的工期。合同的細節也敲定的差不多了。
結果,黃了。和我合夥的一個開發人員小何覺得甲方新提的需求需要再追加 600 塊,甲方覺得這點錢擱不住再追加了。總之呢,7.5W 的項目就因為這個細節黃了,很遺憾。
第二個通過這個途徑找到我的甲方,叫鵬哥。開發一個網站,總價一萬多,吃了上次的虧后,我自己就不想參与了,就找了一個讀者(小李)做。
結果這個項目爛尾了。小李交付的產物我自己都覺得不好意思,bug 非常多。在我看來,既然項目的訂金已經收了,作為開發人員,至少應該交付一個說得過去的產物——負責任吧。
很遺憾,個人品牌招攬來的前兩個私活最後都搞砸了。這裡有必要總結一下:作為程序員,既然打定主意要接私活,那麼接到的時候一定要珍惜。如果一開始覺得價錢低,就趁早拒絕,免得因為需求變動等等原因砸了招牌。
當然了,通過這個途徑也做成了四單,每單的價格差不多兩萬。這裏就不再詳談了。
個人品牌的確可以引流來更多的私活,但與此同時,也會浪費很多時間。
像這種泛泛之談的意向客戶有很多。話說,我啥時候變成“社會王”了,我特么是正兒八經的“王老師”好不好?
外包平台有很多,我就不再一一列舉了。只說幾個我認為還不錯的平台,也不打算細說,免得有些讀者“誇我”良苦用心地在打廣告。
在我寫這篇文章的時候,突然收到朋友的一條信息,說她們公司剛剛辭退了一位員工,還通報批評了,就因為接私活被舉報了——她們公司一般不辭退員工,這下子相當於鐵飯碗丟了。
所以說呢,接私活是有風險的。並且在我看來,如果主業沒有遇到瓶頸,強烈不建議接私活。就好比一個小孩子走路還不會,就要求他要跑起來。
時間對於一個程序員來說很寶貴,尤其是一個正在成長中的程序員。
如果你確實急用錢,價格又合適,那就去做。如果不怎麼缺錢,我再強調一次,別去接私活。私活的錢不好掙是一個方面,更重要的是如果你把做私活的時間花在提升自己上,產生的價值就要大得多。等你提升了自己,提升了固定薪水,遠比拿的這點私活的錢划算。千萬不要“撿了芝麻丟了西瓜”。
如果你像我,主業上遇到了瓶頸,平時的時間比較充分,想有一些額外的收入,同時為了保持技術的熟練度,這種情況下,是可以考慮接一些私活的。對於那種投入時間巨大,回報很可憐的項目,千萬不要接!
另外呢,如果甲方只提供幾個簡單的想法,甚至幾張圖片,更或者發一個參照的效果網站,就可以直接忽視了,這類通通不靠譜!
最後呢,還要說一句,如果訂金都收了,自己就算是覺得吃了虧,也應該有點職業素質,把像樣的產品交付,千萬別應付。
謝謝大家的閱讀,原創不易,喜歡就隨手點個贊,這將是我最強的寫作動力。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!
在平時的業務開發中,數組(Array) 是我們經常用到的數據類型,那麼對數組的排序也很常見,除去使用循環遍曆數組的方法來排列數據,使用JS數組中原生的方法 sort 來排列(沒錯,比較崇尚JS原生的力量)。
數組中能夠直接用來排序的方法有:reverse() 和 sort(),由於 reverse()方法不夠靈活,才有了sort()方法。在默認情況下,sort()方法按升序排列數組。
var arr=[1,3,5,9,4];
console.log(arr.sort());
// 輸出: [1, 3, 4, 5, 9]這時發現數據按照從小到大排列,沒問題;於是再把數組改成:var arr=[101,1,3,5,9,4,11];,再調用sort()方法打印排序結果。
var arr=[101,1,3,5,9,4,11];
console.log(arr.sort());
// 輸出: [1, 101, 11, 3, 4, 5, 9]這個時候發現數組101,11都排在3前面,是因為 sort() 方法會調用數組的toString()轉型方法,然後比較得到的字符串,確定如何排序,即使數組中的每一項都是數值,sort()方法比較的也是字符串。
那麼字符串又是怎麼排序的呢,是根據字符串的unicode編碼從小到大排序的。下面我們嘗試打印出數組每一項的unicode編碼看一下。
...
// 轉碼方法
function getUnicode (charCode) {
return charCode.charCodeAt(0).toString(16);
}
// 打印轉碼
arr.forEach((n)=>{
console.log(getUnicode(String(n)))
});
// 輸出: 31 31 31 33 34 35 39
驚奇地發現,1,101,11的字符串unicode編碼都是31
以上發現sort()方法不是按照我們想要的順序排序的,那麼,怎麼解決呢,sort()方法可以接收一個比較函數作為參數,以便指定哪個值位於哪個值前面。
比較函數(compare)接收兩個參數,如果第一個參數位於第二個之前則返回一個負數,如果兩個參數相等則返回0,如果第一個參數位於第二個之後則返回一個整數。
function compare(value1,value2){
if (value1 < value2){
return -1;
} else if (value1 > value2){
return 1;
} else{
return 0;
}
}我們把比較函數傳遞給sort()方法,在對arr數組進行排列,打印結果如下:
var arr=[101,1,3,5,9,4,11];
console.log(arr.sort(compare));
// 輸出: [1, 3, 4, 5, 9, 11, 101];可以發現排序從小到大沒有什麼問題。
sort() 方法通過傳入一個比較函數來排序数字數組,但是在開發中,我們會對一個對象數組的某個屬性進行排序,例如id,年齡等等,那麼怎麼解決呢?
要解決這個問題:我們可以定義一個函數,讓它接收一個屬性名,然後根據這個屬性名來創建一個比較函數並作為返回值返回來(JS中函數可以作為值來使用,不僅可以像傳遞參數一樣把一個函數傳遞給另一個函數,也可以將一個函數作為另一個函數的結果返回,函數作為JS中的第一等公民不是沒有原因的,確實很靈活。),代碼如下。
function compareFunc(prop){
return function (obj1,obj2){
var value1=obj1[prop];
var value2=obj2[prop];
if (value1 < value2){
return -1;
} else if (value1 > value2){
return 1;
} else{
return 0;
}
}
}定義一個數組users,調用sort()方法傳入compareFunc(prop)打印輸出結果:
var users=[
{name:'tom',age:18},
{name:'lucy',age:24},
{name:'jhon',age:17},
];
console.log(users.sort(compareFunc('age')));
// 輸出結果
[{name: "jhon", age: 17},
{name: "tom", age: 18},
{name: "lucy", age: 24}]在默認情況下,調用sort()方法不傳入比較函數時,sort()方法會調用每個對象的toString()方法來確定他們的次序,當我們調用compareFunc(‘age’)方法創建一個比較函數,排序是按照對象的age屬性排序的。
儘管現在很多後台返回數據就是JSON格式的,很輕量又方便解析。但是之前有個項目因為後台返回的都是XML字符串,前端拿到數據后還得進行序列化,有些需要排序,之前的排序都是把XML轉換成數組對象進行排序的,這樣做沒有什麼問題,只不過感覺代碼寫的很冗餘麻煩。後來就突發奇想,xml獲取得到也是類數組對象,把類數組對象轉換成數組不就可以直接排序了么。
// 1.模擬後端返回的XML字符串
var str=`
<root>
<user>
<name>tom</name>
<age>18</age>
</user>
<user>
<name>lucy</name>
<age>24</age>
</user>
<user>
<name>jhon</name>
<age>17</age>
</user>
<root>
`
// 2.定義比較函數
function compareFunction(prop){
return function (a, b) {
var value1= a.getElementsByTagName(prop)[0].textContent;
var value2= b.getElementsByTagName(prop)[0].textContent;
if (value1 < value2){
return -1;
} else if (value1 > value2){
return 1;
} else{
return 0;
}
}
}
// 3.xml字符串轉換成xml對象
var domParser = new DOMParser();
var xmlDoc = domParser.parseFromString(str, 'text/xml');
var userElements=xmlDoc.getElementsByTagName('user'));
// 4.userElements類數組對象轉換成數組再排序
var userElements=Array.prototype.slice.call(xmlDoc.getElementsByTagName('user'));
var _userElements=userElements.sort(compareFunction('age'));
// 5.打印排序后的結果
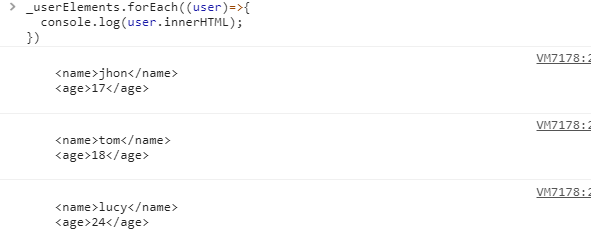
_userElements.forEach((user)=>{
console.log(user.innerHTML);
});打印排序后的結果
可以發現,XML節點已經按照age從小到大排序了。
JS數組的sort方法因為有了傳入比較函數使得排序靈活了許多,還有根據時間,漢字拼音首字母排序等等,我們只要牢記通過傳入比較函數明確比較兩個對象屬性值,通過比較屬性值來決定對象的排序順序即可。自己也是在工作中遇到問題從而發現解決問題的新思路,以上就簡單總結這麼多了,如有不足,多多指正。
參考資料:
《JavaScript高級教程》
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包"嚨底家"
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
說到OSI參考模型,理解網絡與網絡之間的關係,不說太深入難以理解的東西,只求能最大程度上理解與使用。
參考模型是國際標準化組織(ISO)制定的一個用於計算機或通信系統間互聯的標準體系,一般稱為OSI參考模型或七層模型。
概念性的東西,先知道這些就夠了,我們先來聊一聊一個常見的一個模型。
互聯網就是許許多多個局域網組成的,從我們最簡單的一個局域網入手,開始理解
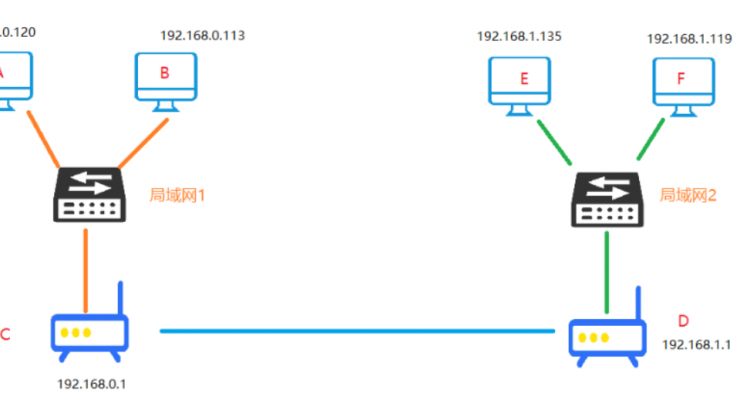
這裏舉例兩個不同的局域網,計算機用網線接入交換機、交換機連接網關路由器,另一處
也是通過相同的方式進行連接。先來了解一下OSI參考模型是如何定義這七層的
參考:
這裏定義的七層只是為了方便我們去理解,實際上是不存在的。
簡單的了解一下這七層是如何定義的,具體的功能還是得舉例子來理解說明。
從最上層的應用層開始說起:如何一步步的封裝數據,到最後進行發送。
應用層是直接面向用戶的最高層,但它卻不是應用程序,它只是為引用程序提供服務的
就好比,我們用的電腦版微信吧!它就是一個實實在在的應用程序,假設要與一個遠方的小姐姐進行聊天會話,這個時候呢,發送一個Hello給遠方的小姐姐。
當你點擊發送的時候,其實做了很多事情,我們就來梳理一下。
需要發送的數據就是:Hello ,當然,應用層首先給這個數據拼接一個AH,這裏就是應用層的報頭,就好比是微信的一個特有的數據,就這樣先理解。
當然,我們總不能發送明文吧,將發送的文本數據進行編碼,平常我們計算機使用的萬國碼UTF-8,肯定要進行一下加密吧
表示層更關心的是所傳送數據的語法和語義,主要包括數據格式變化、與解密、與解壓等
字面意思,就可以理解出這一層表示的意思,建立一個會話,就好比使用Http訪問web的時候,都會存在一個Session 作為標識
讓服務器來區別訪問的計算機。主要功能是負責維護兩個節點之間的傳輸聯接,確保點到點傳輸不中斷,以及管理數據交換等功能。
會話層在應用進程中建立、管理和終止會話。會話層還可以通過對話控制來決定使用何種通信方式,通信或通信。會話層通過自身協議對請求與應答進行協調
傳輸層作為OSI參考模型中,最重要的一層,這裏主要是以端口到端口來區分。這裏涉及到兩個特別重要的協議TCP 以及UDP
一太計算機上同時運行着QQ、微信、以及瀏覽器等。發送數據報,這個數據包到底是哪個程序發出去的呢?當然要從指定的一個端口發出去
計算機的端口範圍 0-65535
0-1023 就是1024個端口為系統佔用端口
了解到這些,就該先來說說UDP協議
UDP協議定義了端口,同一個主機上的每個應用程序都需要指定唯一的端口號,並且規定網絡中傳輸的數據包必須加上端口信息,當數據包到達主機以後,就可以根據端口號找到對應的應用程序了。UDP協議比較簡單,實現容易,但它沒有確認機制,數據包一旦發出,無法知道對方是否收到,因此可靠性較差,為了解決這個問題,提高網絡可靠性,TCP協議就誕生了。
參考:
一個UDP報文包含首部與數據部分,UDP首部佔用8個字節,數據部分最長長度為65535B(字節) 即 64KB
UDP協議是無連接,不保證穩定傳輸的協議,但處理速度較快,通常的音頻、視頻在傳送時候使用UDP較多。
我們這裏的例子是微信,微信能保證數據百分百到達,所以我們採用TCP來具體說明數據的封裝
TCP即傳輸控制協議,是一種面向連接的、可靠的、基於字節流的通信協議。簡單來說TCP就是有確認機制的UDP協議,每發出一個數據包都要求確認,如果有一個數據包丟失,就收不到確認,發送方就必須重發這個數據包。為了保證傳輸的可靠性,TCP協議在UDP基礎之上建立了三次對話的確認機制,即在正式收發數據前,必須和對方建立可靠的連接。TCP數據包和UDP一樣,都是由首部和數據兩部分組成,唯一不同的是,TCP數據包沒有長度限制,理論上可以無限長,但是為了保證網絡的效率,通常TCP數據包的長度不會超過IP數據包的長度,以確保單個TCP數據包不必再分割
參考:
這裏只需要了解的是TCP的基本封裝過程,這裏只涉及到源端口以及目的端口,還未涉及到IP相關的內容。它和UDP協議一樣。就好像是一個改進版的
UDP協議,它能保證數據的可靠傳輸,這個特點記住即可。這裏模擬一下,我們數據的封裝過程。假設微信使用的端口是6666,目標端口就是遠方小姐姐微信
的端口,當然也是一樣的。這裏我為了理解只做簡寫
從上面幾層來看,我們已經將微信的數據封裝成來一個TCP數據報,裡面包含來微信的端口 假設是6666,當然,就好比寫信一樣,我的信封
已經準備好勒,裏面要發送的內容我也已經準備好了,接下來就是地址了。肯定要指定這個報文我要發送到哪裡去。所以呢IP 網際協議,就誕生了。
網絡層引入了IP協議,制定了一套新地址,使得我們能夠區分兩台主機是否同屬一個網絡,這套地址就是網絡地址,也就是所謂的IP地址。IP協議將這個32位的地址分為兩部分,前面部分代表網絡地址,後面部分表示該主機在局域網中的地址。如果兩個IP地址在同一個子網內,則網絡地址一定相同。為了判斷IP地址中的網絡地址,IP協議還引入了子網掩碼,IP地址和子網掩碼通過按位與運算后就可以得到網絡地址
IP地址在這裏我們就比較好理解了。我們平時的生活中都會涉及到。一個IP指向的就是互聯網當中的一台機器或者就是一台路由器了。
我們來封裝數據。再把上面的圖拿下來,說明一下,我們要給E電腦的小姐姐發送消息。比如我是A電腦,小姐姐在另外一個網關下的E電腦
比較重要的兩個參數:
源地址:192.168.0.120
目標地址:192.168.1.135
進行封裝后的數據,這裏將源地址,告訴路由器(郵局) 發件人 就是源地址,以及收件人 也就是目標地址
這裏暫時不細說這個ARP協議的內容。我們只需要知道 ARP協議是用來拿IP換MAC地址的,上面的IP協議也已經提過了,通過子網掩碼和IP地址的換算,可以得到
網絡號,網絡號就可以區別這兩個IP是否在同一個局域網內。 參考這個秒懂:
到這一層,就已經到網卡、網絡設備(交換機)的範疇了。數據鏈路層最重要的協議是以太網協議,數據鏈路層最重要的一點就是數據成幀。
接入以太網的設備必須包含一塊以太網網卡,也就是我們常用的網卡,一組電信號稱作是一個數據幀 、或者叫做一個數據包
網卡都包含一個全球唯一的MAC地址,發送端的和接收端的地址便是指網卡的地址,即Mac地址。
每塊網卡出廠時都被燒錄上一個實際上唯一的Mac地址,長度為48位2進制,通常由12位16進制數表示,(前六位是廠商編碼,后六位是流水線號)
進行數據鏈路層的封裝,將本機的MAC(源MAC地址) 和目標MAC地址封裝在頭部,在尾部加入DT報尾,這樣 一個數據幀算是封裝完成了!
等等。我們好像還不知道小姐姐那邊的目標MAC地址,這時候就需要用ARP協議了。我們知道ARP協議就是用來用IP來換MAC地址的。
上面已經簡單的了解過了,我們要和在B局域網下的E電腦進行通信,但是我們不知道它的MAC地址,於是我們發送一個ARP請求,來獲取目標的MAC地址
目標MAC 為FF:FF:FF:FF:FF:FF 表示的是廣播地址,這個數據包發出去后,所有的子網機器都會收到,收到的機器判斷目標MAC是否是自己,若不是,則直接丟棄
若是,收到報文的主機會通過單播的形式,將MAC地址回傳給我們。
通過路由協議我們可以得知,若不在一個一個子網內,則會交給路由器
路由器返回的包裏面,目標MAC就會變成路由器的MAC地址,我們拿路由器的MAC地址組裝數據鏈路層報文即可。
經過以上的每一層的層層包裝,這時候,我們已經包裝好了一個以太網數據幀,包含源MAC,目標MAC,源IP,目標IP等等一系列數據。
物理層就是將這個數據通過電信號、光信號的方式傳遞過去的,物理層一般都是我么所說的光纜以及網線這些硬件設備。
通過上面的知識,我們已經了解到如何封裝成一個數據幀,以及一些協議的相關內容。那麼這裏就會有一個問題,同一子網、
不同子網、以及相隔很遠的兩個子網是如何進行通信的呢?以及我們撥號上網后,公網IP與內網IP是怎麼一回事呢?
我們先來看一個圖,計算機A要與計算機B進行通信,這時候他們是同處於一個子網內的,這個時候就很簡單了。
按照上面的七層進行封裝數據,這裏的具體參數需要說明一下:
源IP: 0.120(簡寫)
目標IP:0.113
源MAC : A電腦的MAC
目標MAC:B電腦MAC(這裏若不知道就先發送ARP請求)
A將數據報發送出去后,交換機直接查詢目標MAC所轉發的端口,將這個數據報準確的推送到B電腦連接的那個端口即可。
A電腦需要與E電腦進行通信,這時候發現A與E不在一個子網內,這時候呢,就需要路由器來協助了
源IP: A的IP
目標IP: E的IP
源MAC:A的 MAC
目標MAC: 路由器C的MAC
因為不在一個子網內,需要路由器來進行路由這個數據包,送至D路由器后,D路由器拿出數據報中目標的IP,發送ARP請求,
請求E的MAC地址,知道后,將數據報裏面的目標MAC進行替換,然後發送給E即可。
我們在使用路由器上網后,運營商就會給我們分配一個公網IP,按照圖上的指示,C路由器在進行撥號后,就會給C路由器分配一個公網IP
我這裏假設有這樣兩個。這時候需要封裝數據,該如何封裝呢,還是以A電腦與E電腦進行通信,大家肯定會很迷惑。
這裏就需要了解一個協議:網路地址轉換協議:
以下簡稱NAT,NAT 在IPV4 之前起到很大的作用,我們現在也在用,因為IPV4 IP數量的限制,但接入互聯網的電腦又那麼多
該怎麼辦呢。就是給一個路由下分配一個公網IP,路由器下面的IP與公網IP進行一個轉換,這裏面說的轉換就是:NAT
圖中黑色的就是轉換部分,通過端口的轉換,將多個子網IP映射到公網的一個IP上面
這種方式支持端口的映射,並允許多台主機共享一個公網IP地址。 支持端口轉換的NAT又可以分為兩類:源地址轉換和目的地址轉換。前一種情形下發起連接的計算機的IP地址將會被重寫,使得內網主機發出的數據包能夠到達外網主機。后一種情況下被連接計算機的IP地址將被重寫,使得外網主機發出的數據包能夠到達內網主機。實際上,以上兩種方式通常會一起被使用以支持雙向通信。 還是舉例,這時候,我們的A電腦需要與E電腦進行通信,E電腦在廣東省,他們撥號后,都會分配一個公網IP,並且已經在路由器裏面完成了NAT映射,
源IP: A電腦IP
目標IP: E電腦映射后的公網IP
源MAC :A電腦MAC
目標MAC : 本地路由器MAC地址 封裝完成后,將數據報送到C路由器,路由器通過映射表,將源IP進行一個替換
替換后,交給互聯網上的路由器進行數據報的轉發,這就好像發快遞時候一樣,經過一系列的中轉站,到達目的路由。
到達D路由后,D路由將數據報中的目標地址也進行一個轉換,這個地址是可以相互轉的。現在就是公網映射轉到本機IP
轉換后就輕鬆了。按照ARP請求到E機器的MAC地址,然後發報即可。
以上內容皆是自己查看一些博主的總結,通過學習后,能夠加深自己對OIS模型、以及TCP、IP、ARP
這些非常重要的協議的一個認識。以及了解到不同層級下面。兩台電腦如何完成一個通行。這裏講的比較淺,
互聯網的奧妙不是那麼容易就可以理解透的。還是那句,不要停止學習的腳步。就好
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包"嚨底家"
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
我們實現了根據搜索關鍵詞查詢商品列表和根據商品分類查詢,並且使用到了mybatis-pagehelper插件,講解了如何使用插件來幫助我們快速實現分頁數據查詢。本文我們將繼續開發商品詳情頁面和商品留言功能的開發。
關於商品詳情頁,和往常一樣,我們先來看一看jd的示例:
從上面2張圖,我們可以看出來,大體上需要展示給用戶的信息。比如:商品圖片,名稱,價格,等等。在第二張圖中,我們還可以看到有一個商品評價頁簽,這些都是我們本節要實現的內容。
我們根據上圖(權當是需求文檔,很多需求文檔寫的比這個可能還差勁很多…)分析一下,我們的開發大致都要關注哪些points:
根據我們梳理出來的信息,接下來開始編碼就會很簡單了,大家可以根據之前課程講解的,先自行實現一波,請開始你們的表演~
因為我們在實際的數據傳輸過程中,不可能直接把我們的數據庫entity之間暴露到前端,而且我們商品相關的數據是存儲在不同的數據表中,我們必須要封裝一個ResponseDTO來對數據進行傳遞。
ProductDetailResponseDTO包含了商品主表信息,以及圖片列表、商品規格(不同SKU)以及商品具體參數(產地,生產日期等信息)@Data
@ToString
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class ProductDetailResponseDTO {
private Products products;
private List<ProductsImg> productsImgList;
private List<ProductsSpec> productsSpecList;
private ProductsParam productsParam;
}根據我們之前表的設計,這裏使用生成的通用mapper就可以滿足我們的需求。
從我們封裝的要傳遞到前端的ProductDetailResponseDTO就可以看出,我們可以根據商品id分別查詢出商品的相關信息,在controller進行數據封裝就可以了,來實現我們的查詢接口。
查詢商品主表信息(名稱,內容等)
在com.liferunner.service.IProductService中添加接口方法:
/**
* 根據商品id查詢商品
*
* @param pid 商品id
* @return 商品主信息
*/
Products findProductByPid(String pid);接着,在com.liferunner.service.impl.ProductServiceImpl中添加實現方法:
@Override
@Transactional(propagation = Propagation.SUPPORTS)
public Products findProductByPid(String pid) {
return this.productsMapper.selectByPrimaryKey(pid);
}直接使用通用mapper根據主鍵查詢就可以了。
同上,我們依次來實現圖片、規格、以及商品參數相關的編碼工作
查詢商品圖片信息列表
/**
* 根據商品id查詢商品規格
*
* @param pid 商品id
* @return 規格list
*/
List<ProductsSpec> getProductSpecsByPid(String pid);
----------------------------------------------------------------
@Override
public List<ProductsSpec> getProductSpecsByPid(String pid) {
Example example = new Example(ProductsSpec.class);
val condition = example.createCriteria();
condition.andEqualTo("productId", pid);
return this.productsSpecMapper.selectByExample(example);
}查詢商品規格列表
/**
* 根據商品id查詢商品規格
*
* @param pid 商品id
* @return 規格list
*/
List<ProductsSpec> getProductSpecsByPid(String pid);
------------------------------------------------------------------
@Override
public List<ProductsSpec> getProductSpecsByPid(String pid) {
Example example = new Example(ProductsSpec.class);
val condition = example.createCriteria();
condition.andEqualTo("productId", pid);
return this.productsSpecMapper.selectByExample(example);
}查詢商品參數信息
/**
* 根據商品id查詢商品參數
*
* @param pid 商品id
* @return 參數
*/
ProductsParam findProductParamByPid(String pid);
------------------------------------------------------------------
@Override
public ProductsParam findProductParamByPid(String pid) {
Example example = new Example(ProductsParam.class);
val condition = example.createCriteria();
condition.andEqualTo("productId", pid);
return this.productsParamMapper.selectOneByExample(example);
}在上面將我們需要的信息查詢實現之後,然後我們需要在controller對數據進行包裝,之後再返回到前端,供用戶來進行查看,在com.liferunner.api.controller.ProductController中添加對外接口/detail/{pid},實現如下:
@GetMapping("/detail/{pid}")
@ApiOperation(value = "根據商品id查詢詳情", notes = "根據商品id查詢詳情")
public JsonResponse findProductDetailByPid(
@ApiParam(name = "pid", value = "商品id", required = true)
@PathVariable String pid) {
if (StringUtils.isBlank(pid)) {
return JsonResponse.errorMsg("商品id不能為空!");
}
val product = this.productService.findProductByPid(pid);
val productImgList = this.productService.getProductImgsByPid(pid);
val productSpecList = this.productService.getProductSpecsByPid(pid);
val productParam = this.productService.findProductParamByPid(pid);
val productDetailResponseDTO = ProductDetailResponseDTO
.builder()
.products(product)
.productsImgList(productImgList)
.productsSpecList(productSpecList)
.productsParam(productParam)
.build();
log.info("============查詢到商品詳情:{}==============", productDetailResponseDTO);
return JsonResponse.ok(productDetailResponseDTO);
}從上述代碼中可以看到,我們分別查詢了商品、圖片、規格以及參數信息,使用ProductDetailResponseDTO.builder().build()封裝成返回到前端的對象。
按照慣例,寫完代碼我們需要進行測試。
{
"status": 200,
"message": "OK",
"data": {
"products": {
"id": "smoke-100021",
"productName": "(奔跑的人生) - 中華",
"catId": 37,
"rootCatId": 1,
"sellCounts": 1003,
"onOffStatus": 1,
"createdTime": "2019-09-09T06:45:34.000+0000",
"updatedTime": "2019-09-09T06:45:38.000+0000",
"content": "吸煙有害健康“
},
"productsImgList": [
{
"id": "1",
"productId": "smoke-100021",
"url": "http://www.life-runner.com/product/smoke/img1.png",
"sort": 0,
"isMain": 1,
"createdTime": "2019-07-01T06:46:55.000+0000",
"updatedTime": "2019-07-01T06:47:02.000+0000"
},
{
"id": "2",
"productId": "smoke-100021",
"url": "http://www.life-runner.com/product/smoke/img2.png",
"sort": 1,
"isMain": 0,
"createdTime": "2019-07-01T06:46:55.000+0000",
"updatedTime": "2019-07-01T06:47:02.000+0000"
},
{
"id": "3",
"productId": "smoke-100021",
"url": "http://www.life-runner.com/product/smoke/img3.png",
"sort": 2,
"isMain": 0,
"createdTime": "2019-07-01T06:46:55.000+0000",
"updatedTime": "2019-07-01T06:47:02.000+0000"
}
],
"productsSpecList": [
{
"id": "1",
"productId": "smoke-100021",
"name": "中華",
"stock": 2276,
"discounts": 1.00,
"priceDiscount": 7000,
"priceNormal": 7000,
"createdTime": "2019-07-01T06:54:20.000+0000",
"updatedTime": "2019-07-01T06:54:28.000+0000"
},
],
"productsParam": {
"id": "1",
"productId": "smoke-100021",
"producPlace": "中國",
"footPeriod": "760天",
"brand": "中華",
"factoryName": "中華",
"factoryAddress": "陝西",
"packagingMethod": "盒裝",
"weight": "100g",
"storageMethod": "常溫",
"eatMethod": "",
"createdTime": "2019-05-01T09:38:30.000+0000",
"updatedTime": "2019-05-01T09:38:34.000+0000"
}
},
"ok": true
}在文章一開始我們就看過jd詳情頁面,有一個詳情頁簽,我們來看一下:
它這個實現比較複雜,我們只實現相對重要的幾個就可以了。
針對上圖中紅色方框圈住的內容,分別有:
我們來實現上述分析的相對必要的一些內容。
根據我們需要的信息,我們需要從用戶表、商品表以及評價表中來聯合查詢數據,很明顯單表通用mapper無法實現,因此我們先來實現自定義查詢mapper,當然數據的傳輸對象是我們需要先來定義的。
創建com.liferunner.dto.ProductCommentDTO.
@Data
@NoArgsConstructor
@AllArgsConstructor
@Builder
public class ProductCommentDTO {
//評價等級
private Integer commentLevel;
//規格名稱
private String specName;
//評價內容
private String content;
//評價時間
private Date createdTime;
//用戶頭像
private String userFace;
//用戶昵稱
private String nickname;
}在com.liferunner.custom.ProductCustomMapper中添加查詢接口方法:
/***
* 根據商品id 和 評價等級查詢評價信息
* <code>
* Map<String, Object> paramMap = new HashMap<>();
* paramMap.put("productId", pid);
* paramMap.put("commentLevel", level);
*</code>
* @param paramMap
* @return java.util.List<com.liferunner.dto.ProductCommentDTO>
* @throws
*/
List<ProductCommentDTO> getProductCommentList(@Param("paramMap") Map<String, Object> paramMap);在mapper/custom/ProductCustomMapper.xml中實現該接口方法的SQL:
<select id="getProductCommentList" resultType="com.liferunner.dto.ProductCommentDTO" parameterType="Map">
SELECT
pc.comment_level as commentLevel,
pc.spec_name as specName,
pc.content as content,
pc.created_time as createdTime,
u.face as userFace,
u.nickname as nickname
FROM items_comments pc
LEFT JOIN users u
ON pc.user_id = u.id
WHERE pc.item_id = #{paramMap.productId}
<if test="paramMap.commentLevel != null and paramMap.commentLevel != ''">
AND pc.comment_level = #{paramMap.commentLevel}
</if>
</select>如果沒有傳遞評價級別的話,默認查詢全部評價信息。
在com.liferunner.service.IProductService中添加查詢接口方法:
/**
* 查詢商品評價
*
* @param pid 商品id
* @param level 評價級別
* @param pageNumber 當前頁碼
* @param pageSize 每頁展示多少條數據
* @return 通用分頁結果視圖
*/
CommonPagedResult getProductComments(String pid, Integer level, Integer pageNumber, Integer pageSize);在com.liferunner.service.impl.ProductServiceImpl實現該方法:
@Override
public CommonPagedResult getProductComments(String pid, Integer level, Integer pageNumber, Integer pageSize) {
Map<String, Object> paramMap = new HashMap<>();
paramMap.put("productId", pid);
paramMap.put("commentLevel", level);
// mybatis-pagehelper
PageHelper.startPage(pageNumber, pageSize);
val productCommentList = this.productCustomMapper.getProductCommentList(paramMap);
for (ProductCommentDTO item : productCommentList) {
item.setNickname(SecurityTools.HiddenPartString4SecurityDisplay(item.getNickname()));
}
// 獲取mybatis插件中獲取到信息
PageInfo<?> pageInfo = new PageInfo<>(productCommentList);
// 封裝為返回到前端分頁組件可識別的視圖
val commonPagedResult = CommonPagedResult.builder()
.pageNumber(pageNumber)
.rows(productCommentList)
.totalPage(pageInfo.getPages())
.records(pageInfo.getTotal())
.build();
return commonPagedResult;
}因為評價過多會使用到分頁,這裏使用通用分頁返回結果,關於分頁,可查看。
在com.liferunner.api.controller.ProductController中添加對外查詢接口:
@GetMapping("/comments")
@ApiOperation(value = "查詢商品評價", notes = "根據商品id查詢商品評價")
public JsonResponse getProductComment(
@ApiParam(name = "pid", value = "商品id", required = true)
@RequestParam String pid,
@ApiParam(name = "level", value = "評價級別", required = false, example = "0")
@RequestParam Integer level,
@ApiParam(name = "pageNumber", value = "當前頁碼", required = false, example = "1")
@RequestParam Integer pageNumber,
@ApiParam(name = "pageSize", value = "每頁展示記錄數", required = false, example = "10")
@RequestParam Integer pageSize
) {
if (StringUtils.isBlank(pid)) {
return JsonResponse.errorMsg("商品id不能為空!");
}
if (null == pageNumber || 0 == pageNumber) {
pageNumber = DEFAULT_PAGE_NUMBER;
}
if (null == pageSize || 0 == pageSize) {
pageSize = DEFAULT_PAGE_SIZE;
}
log.info("============查詢商品評價:{}==============", pid);
val productComments = this.productService.getProductComments(pid, level, pageNumber, pageSize);
return JsonResponse.ok(productComments);
}FBI WARNING:
@ApiParam(name = “level”, value = “評價級別”, required = false, example = “0”)
@RequestParam Integer level
關於ApiParam參數,如果接收參數為非字符串類型,一定要定義example為對應類型的示例值,否則Swagger在訪問過程中會報example轉換錯誤,因為example缺省為””空字符串,會轉換失敗。例如我們刪除掉level這個字段中的example=”0“,如下為錯誤信息(但是並不影響程序使用。)
2019-11-23 15:51:45 WARN AbstractSerializableParameter:421 - Illegal DefaultValue null for parameter type integer
java.lang.NumberFormatException: For input string: ""
at java.lang.NumberFormatException.forInputString(NumberFormatException.java:65)
at java.lang.Long.parseLong(Long.java:601)
at java.lang.Long.valueOf(Long.java:803)
at io.swagger.models.parameters.AbstractSerializableParameter.getExample(AbstractSerializableParameter.java:412)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at com.fasterxml.jackson.databind.ser.BeanPropertyWriter.serializeAsField(BeanPropertyWriter.java:688)
at com.fasterxml.jackson.databind.ser.std.BeanSerializerBase.serializeFields(BeanSerializerBase.java:721)
at com.fasterxml.jackson.databind.ser.BeanSerializer.serialize(BeanSerializer.java:166)
at com.fasterxml.jackson.databind.ser.impl.IndexedListSerializer.serializeContents(IndexedListSerializer.java:119)有心的小夥伴肯定又注意到了,在Service中處理查詢時,我一部分使用了@Transactional(propagation = Propagation.SUPPORTS),一部分查詢又沒有添加事務,那麼這兩種方式有什麼不一樣呢?接下來,我們來揭開神秘的面紗。
Propagation.SUPPORTS
/**
* Support a current transaction, execute non-transactionally if none exists.
* Analogous to EJB transaction attribute of the same name.
* <p>Note: For transaction managers with transaction synchronization,
* {@code SUPPORTS} is slightly different from no transaction at all,
* as it defines a transaction scope that synchronization will apply for.
* As a consequence, the same resources (JDBC Connection, Hibernate Session, etc)
* will be shared for the entire specified scope. Note that this depends on
* the actual synchronization configuration of the transaction manager.
* @see org.springframework.transaction.support.AbstractPlatformTransactionManager#setTransactionSynchronization
*/
SUPPORTS(TransactionDefinition.PROPAGATION_SUPPORTS),主要關注Support a current transaction, execute non-transactionally if none exists.從字面意思來看,就是如果當前環境有事務,我就加入到當前事務;如果沒有事務,我就以非事務的方式執行。從這方面來看,貌似我們加不加這一行其實都沒啥差別。
划重點:NOTE,對於一個帶有事務同步的管理器來說,這裡有一丟丟的小區別啦。(所以大家在讀註釋的時候,一定要看這個Note.往往這裏面會有好東西給我們,就相當於我們的大喇叭!)
這個同步事務管理器定義了一個事務同步的一個範圍,如果加了這個註解,那麼就等同於我讓你來管我啦,你裏面的資源我想用就可以用(JDBC Connection, Hibernate Session).
SUPPORTS 標註的方法可以獲取和當前事務環境一致的 Connection 或 Session,不使用的話一定是一個新的連接;
再注意下面又一個NOTE,即便上面的配置加入了,但是事務管理器的實際同步配置會影響到真實的執行到底是否會用你。看它的說明:@see org.springframework.transaction.support.AbstractPlatformTransactionManager#setTransactionSynchronization.
/**
* Set when this transaction manager should activate the thread-bound
* transaction synchronization support. Default is "always".
* <p>Note that transaction synchronization isn't supported for
* multiple concurrent transactions by different transaction managers.
* Only one transaction manager is allowed to activate it at any time.
* @see #SYNCHRONIZATION_ALWAYS
* @see #SYNCHRONIZATION_ON_ACTUAL_TRANSACTION
* @see #SYNCHRONIZATION_NEVER
* @see TransactionSynchronizationManager
* @see TransactionSynchronization
*/
public final void setTransactionSynchronization(int transactionSynchronization) {
this.transactionSynchronization = transactionSynchronization;
}描述信息只是說在同一個事務管理器才能起作用,並沒有什麼實際意義,我們來看一下TransactionSynchronization具體的內容:
package org.springframework.transaction.support;
import java.io.Flushable;
public interface TransactionSynchronization extends Flushable {
/** Completion status in case of proper commit. */
int STATUS_COMMITTED = 0;
/** Completion status in case of proper rollback. */
int STATUS_ROLLED_BACK = 1;
/** Completion status in case of heuristic mixed completion or system errors. */
int STATUS_UNKNOWN = 2;
/**
* Suspend this synchronization.
* Supposed to unbind resources from TransactionSynchronizationManager if managing any.
* @see TransactionSynchronizationManager#unbindResource
*/
default void suspend() {
}
/**
* Resume this synchronization.
* Supposed to rebind resources to TransactionSynchronizationManager if managing any.
* @see TransactionSynchronizationManager#bindResource
*/
default void resume() {
}
/**
* Flush the underlying session to the datastore, if applicable:
* for example, a Hibernate/JPA session.
* @see org.springframework.transaction.TransactionStatus#flush()
*/
@Override
default void flush() {
}
/**
* ...
*/
default void beforeCommit(boolean readOnly) {
}
/**
* ...
*/
default void beforeCompletion() {
}
/**
* ...
*/
default void afterCommit() {
}
/**
* ...
*/
default void afterCompletion(int status) {
}
}事務管理器可以通過org.springframework.transaction.support.AbstractPlatformTransactionManager#setTransactionSynchronization(int)來對當前事務進行行為干預,比如將它設置為1,可以執行事務回調,設置為2,表示出錯了,但是如果沒有加入PROPAGATION.SUPPORTS註解的話,即便你在當前事務中,你也不能對我進行操作和變更。
添加
PROPAGATION.SUPPORTS之後,當前查詢中可以對當前的事務進行設置回調動作,不添加就不行。
下一節我們將繼續開發商品詳情展示以及商品評價業務,在過程中使用到的任何開發組件,我都會通過專門的一節來進行介紹的,兄弟們末慌!
gogogo!
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!
11月19日,業界應用最為廣泛的Kubernetes管理平台創建者Rancher Labs(以下簡稱Rancher)宣布Rio發布了beta版本,這是基於Kubernetes的應用程序部署引擎。它於今年5月份推出,現在最新的版本是v0.6.0。Rio結合了多種雲原生技術,從而簡化了將代碼從測試環境發布到生產環境的流程,同時保證了強大而安全的代碼體驗。
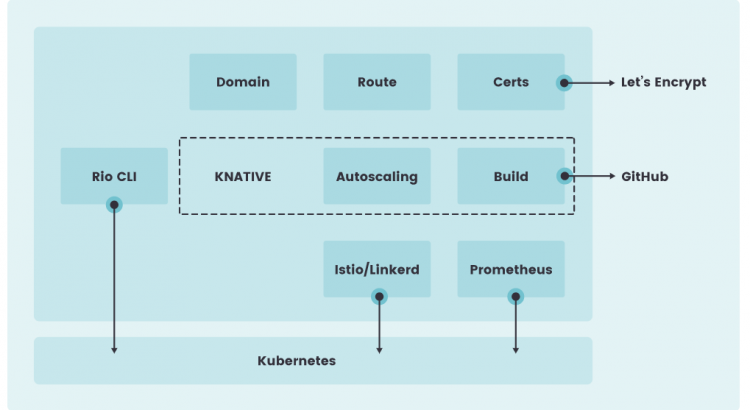
下圖是Rio的架構:
Rio採用了諸如Kubernetes、knative、linkerd、cert-manager、buildkit以及gloo等技術,並將它們結合起來為用戶提供一個完整的應用程序部署環境。
Rio具有以下功能:
從源代碼構建代碼,並將其部署到Kubernetes集群
自動為應用程序創建DNS記錄,並使用Let’s Encrypt的TLS證書保護這些端點
基於QPS以及工作負載的指標自動擴縮容
支持金絲雀發布、藍綠髮布以及A/B部署
支持通過服務網格路由流量
支持縮容至零的serverless工作負載
Git觸發的部署
Rio屬於Rancher整套產品生態的一部分,這些產品支持從操作系統到應用程序的應用程序部署和容器運維。當Rio和諸如Rancher 2.3、k3s和RKE等產品結合使用時,企業可以獲得完整的部署和管理應用程序及容器的體驗。
要了解Rio如何實現上述功能,我們來深入了解一些概念以及工作原理。
Kubernetes版本在1.15以上的Kubernetes集群
為集群配置的kubeconfig(即上下文是你希望將Rio安裝到的集群)
在$PATH中安裝的Rio CLI工具,可參閱以下鏈接,了解如何安裝CLI:
https://github.com/rancher/rio/blob/master/README.md
使用安裝好的Rio CLI工具,調用rio install。你可能需要考慮以下情況:
ip-address:節點的IP地址的逗號分隔列表。你可以在以下情況使用:
你不使用(或不能使用)layer-4的負載均衡器
你的節點IP不是你希望流量到達的IP地址(例如,你使用有公共IP的EC2實例)
在Rio中,service是一個基本的執行單位。從Git倉庫或容器鏡像實例化之後,一個service由單個容器以及服務網格的關聯sidecar組成(默認啟用)。例如,運行使用Golang構建的一個簡單的“hello world”應用程序。
rio run https://github.com/ebauman/rio-demo或者運行容器鏡像版本:
rio run ebauman/demo-rio:v1還有其他選項也可以傳遞給rio run,如需要公開的任意端口(-p 80:8080/http),或者自動擴縮的配置(--scale 1-10)。你可以通過這一命令rio help run,查看所有可傳遞的選項。
想要查看你正在運行的服務,請執行rio ps:
$ rio ps
NAME IMAGE ENDPOINT
demo-service default-demo-service-4dqdw:61825 https://demo-service...每次你運行一個新的服務,Rio將會為這一服務生成一個全局性的端點:
$ rio endpoints
NAME ENDPOINTS
demo-service https://demo-service-default.op0kj0.on-rio.io:30282請注意,此端點不包括版本——它指向由一個common name標識的服務,並且流量根據服務的權重進行路由。
默認情況下,所有Rio集群都將為自己創建一個on-rio.io主機名,並以隨機字符串開頭(如lkjsdf.on-rio.io)。該域名成為通配符域名,它的記錄解析到集群的網關。如果使用NodePort服務,則該網關可以是layer-4負載均衡器,或者是節點本身。
除了創建這個通配符域名,Rio還會使用Let’s Encrypt為這個域名生成一個通配符證書。這會允許自動加密任何HTTP工作負載,而無需用戶進行配置。要啟動此功能,請傳遞-p參數,將http指定為協議,例如:
rio run -p 80:8080/http ...Rio可以根據每秒所查詢到的指標自動擴縮服務。為了啟用這一特性,傳遞--scale 1-10作為參數到rio run,例如:
rio run -p 80:8080/http -n demo-service --scale 1-10 ebauman/rio-demo:v1執行這個命令將會構建ebauman/rio-demo並且部署它。如果我們使用一個工具來添加負載到端點,我們就能夠觀察到自動擴縮容。為了證明這一點,我們需要使用HTTP端點(而不是HTTPS),因為我們使用的工具不支持TLS:
$ rio inspect demo-service
<snipped>
endpoints:
- https://demo-service-v0-default.op0kj0.on-rio.io:30282
- http://demo-service-v0-default.op0kj0.on-rio.io:31976
<snipped>rio inspect除了端點之外還會显示其他信息,但我們目前所需要的是端點信息。使用HTTP端點以及HTTP基準測試工具rakyll / hey,我們可以添加綜合負載:
hey -n 10000 http://demo-service-v0-default.op0kj0.on-rio.io:31976這將會發送10000個請求到HTTP端點,Rio將會提高QPS並適當擴大規模,執行另一個rio ps將會展示已經擴大的規模:
$ rio ps
NAME ... SCALE WEIGHT
demo-service ... 2/5 (40%) 100%注意
對於每個服務,都會創建一個全局端點,該端點將根據基礎服務的權重路由流量。
Rio可以先交付新的服務版本,然後再推廣到生產環境。分階段發布一個新的版本十分簡單:
rio stage --image ebauman/rio-demo:v2 demo-service v2這一命令使用版本v2,分階段發布demo-service的新版本,並且使用容器鏡像ebauman/rio-demo:v2。我們通過執行rio ps這一命令,可以看到新階段的發布:
$ rio ps
NAME IMAGE ENDPOINT WEIGHT
demo-service@v2 ebauman/rio-demo:v2 https://demo-service-v2... 0%
demo-service ebauman/rio-demo:v1 https://demo-service-v0... 100%請注意,新服務的端點具有v2的新增功能,因此即使權重設置為0%,訪問此端點仍將帶你進入服務的v2。這可以讓你能夠在向其發送流量之前驗證服務的運行情況。
說到發送流量:
$ rio weight demo-service@v2=5%
$ rio ps
NAME IMAGE ENDPOINT WEIGHT
demo-service@v2 ebauman/rio-demo:v2 https://demo-service-v2... 5%
demo-service ebauman/rio-demo:v1 https://demo-service-v0... 95%使用rio weight命令,我們現在將發送我們5%的流量(從全局的服務端點)到新版本。當我們覺得demo-service的v2性能感到滿意之後,我們可以將其提升到100%:
$ rio promote --duration 60s demo-service@v2
demo-service@v2 promoted超過60秒之後,我們的demo-service@v2服務將會逐漸提升到接收100%的流量。在這一過程中任意端點上,我們可以執行rio ps,並且查看進程:
$ rio ps
NAME IMAGE ENDPOINT WEIGHT
demo-service@v2 ebauman/rio-demo:v2 https://demo-service-v2... 34%
demo-service ebauman/rio-demo:v1 https://demo-service-v0... 66%Rio可以根據主機名、路徑、方法、標頭和cookie的任意組合將流量路由到端點。Rio還支持鏡像流量、注入故障,配置retry邏輯和超時。
為了開始制定路由決策,我們必須首先創建一個路由器。路由器代表一個主機名和一組規則,這些規則確定發送到主機名的流量如何在Rio集群內進行路由。你想要要定義路由器,需要執行rio router add。例如,要創建一個在默認測試時接收流量並將其發送到demo-service的路由器,請使用以下命令:
rio route add testing to demo-service這將創建以下路由器:
$ rio routers
NAME URL OPTS ACTION TARGET
router/testing https://testing-default.0pjk... to demo-service,port=80發送到https://testing-default…的流量將通過端口80轉發到demo-service。
請注意,此處創建的路由為testing-default. 。Rio將始終使用命名空間資源,因此在這種情況下,主機名測試已在默認命名空間中進行了命名。要在其他命名空間中創建路由器,請將 -n <namespace>傳遞給rio命令:
rio -n <namespace> route add ...為了定義一個基於路徑的路由,當調用rio route add時,指定一個主機名加上一個路徑。這可以是新路由器,也可以是現有路由器。
$ rio route add testing/old to demo-service@v1以上命令可以創建一個基於路徑的路由,它會在https://testing-default. /old接收流量,並且轉發流量到 demo-service@v1服務。
Rio支持基於HTTP標頭和HTTP verbs的值做出的路由策略。如果你想要創建基於特定標頭路由的規則,請在rio route add命令中指定標頭:
$ rio route add --header X-Header=SomeValue testing to demo-service以上命令將創建一個路由規則,它可以使用一個X-Header的HTTP標頭和SomeValue的值將流量轉發到demo-service。類似地,你可以為HTTP方法定義規則:
$ rio route add --method POST testing to demo-serviceRio路由有一項有趣的功能是能夠將故障注入響應中。通過定義故障路由規則,你可以設置具有指定延遲和HTTP代碼的失敗流量百分比:
$ rio route add --fault-httpcode 502 --fault-delay-milli-seconds 1000 --fault-percentage 75 testing to demo-serviceRio支持按照權重分配流量、為失敗的請求重試邏輯、重定向到其他服務、定義超時以及添加重寫規則。要查看這些選項,請參閱以下鏈接:
https://github.com/rancher/rio
將git倉庫傳遞給rio run將指示Rio在提交到受監控的branch(默認值:master)之後構建代碼。對於Github倉庫,你可以通過Github webhooks啟動此功能。對於任何其他git repo,或者你不想使用webhooks,Rio都會提供一項“gitwatcher”服務,該服務會定期檢查您的倉庫中是否有更改。
Rio還可以根據受監控的branch的拉取請求構建代碼。如果你想要進行配置,請將--build-pr傳遞到rio run。還有其他配置這一功能的選項,包括傳遞Dockerfile的名稱、自定義構建的鏡像名稱以及將鏡像推送到指定的鏡像倉庫。
Rio使用稱為Riofile的docker-compose-style manifest定義資源
configs:
conf:
index.html: |-
<!DOCTYPE html>
<html>
<body>
<h1>Hello World</h1>
</body>
</html>
services:
nginx:
image: nginx
ports:
- 80/http
configs:
- conf/index.html:/usr/share/nginx/html/index.htmlRiofile定義了一個簡單的nginx Hello World網頁所有必要的組件。通過rio up部署它,會創建一個Stack(堆棧),它是Riofile定義的資源的集合。
Riofile具有許多功能,例如觀察Git庫中的更改以及使用Golang模板進行模板化。
Rio還有許多功能,例如configs、secrets以及基於角色訪問控制(RBAC)。詳情可參閱:
https://rio.io/
Rio的beta版本包括了一個全新的儀錶盤,使得Rio組件可視化。要訪問此儀錶盤,請執行命令:rio dashboard。在有GUI和默認瀏覽器的操作系統上,Rio將自動打開瀏覽器並加載儀錶盤。
你可以使用儀錶盤來創建和編輯堆棧、服務、路由等。此外,可以直接查看和編輯用於各種組件技術(Linkerd、gloo等)的對象,儘管不建議這樣做。儀錶盤目前處於開發的早期階段,因此某些功能的可視化(如自動縮放和服務網格)尚不可用。
作為Rio的默認服務網格,Linked附帶了一個儀錶盤作為產品的一部分。該儀錶盤可以通過執行rio linkerd來使用,它將代理本地本地主機流量到linkerd儀錶盤(不會在外部公開)。與Rio儀錶盤類似,有GUI和默認瀏覽器的操作系統上,Rio將自動打開瀏覽器並加載儀錶盤:
Linkerd儀錶盤显示了Rio集群的網格配置、流量和網格組件。Linkerd提供了Rio路由的某些功能組件,因此這些配置可能會显示在此儀錶盤上。還有一些工具可用於測試和調試網格配置和流量。
Rio為用戶提供許多功能,是一款強大的應用程序部署引擎。這些組件可以在部署應用程序時為開發人員提供強大的功能,使流程穩定而安全,同時輕鬆又有趣。在Rancher產品生態中,Rio提供了企業部署和管理應用程序和容器的強大功能。
如果你想了解Rio的更多信息,歡迎訪問Rio主頁或Github主頁:
https://rio.io
https://github.com/rancher/rio
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包"嚨底家"
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
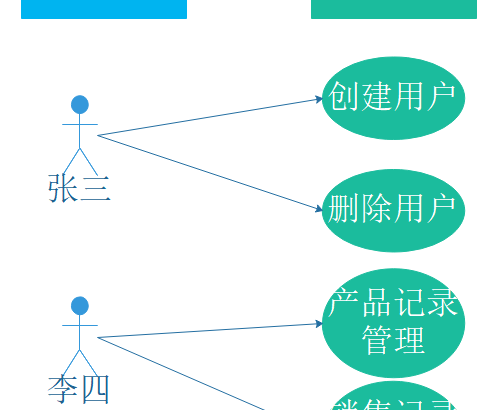
我們開發一個系統,必然面臨權限控制的問題,即不同的用戶具有不同的訪問、操作、數據權限。形成理論的權限控制模型有:自主訪問控制(DAC: Discretionary Access Control)、強制訪問控制(MAC: Mandatory Access Control)、基於屬性的權限驗證(ABAC: Attribute-Based Access Control)等。最常被開發者使用也是相對易用、通用的就是RBAC權限模型(Role-Based Access Control),本文就將向大家介紹該權限模型。
RBAC權限模型(Role-Based Access Control)即:基於角色的權限控制。模型中有幾個關鍵的術語:
RBAC權限模型核心授權邏輯如下:
想到權限控制,人們最先想到的一定是用戶與權限直接關聯的模式,簡單地說就是:某個用戶具有某些權限。如圖:
這種模型能夠清晰的表達用戶與權限之間的關係,足夠簡單。但同時也存在問題:
在實際的團體業務中,都可以將用戶分類。比如對於薪水管理系統,通常按照級別分類:經理、高級工程師、中級工程師、初級工程師。也就是按照一定的角色分類,通常具有同一角色的用戶具有相同的權限。這樣改變之後,就可以將針對用戶賦權轉換為針對角色賦權。
我們可以用下圖中的數據庫設計模型,描述這樣的關係。
但是在實際的應用系統中,一個用戶一個角色遠遠滿足不了需求。如果我們希望一個用戶既擔任銷售角色、又暫時擔任副總角色。該怎麼做呢?為了增加系統設計的適用性,我們通常設計:
我們可以用下圖中的數據庫設計模型,描述這樣的關係。
為了適應這種需求,我們可以把頁面資源(菜單)和操作資源(按鈕)分表存放,如上圖。也可以把二者放到一個表裡面存放,用一個字段進行標誌區分。
數據權限比較好理解,就是某個用戶能夠訪問和操作哪些數據。
所以為了面對複雜的需求,數據權限的控制通常是由程序員書寫個性化的SQL來限制數據範圍的,而不是交給權限模型或者Spring Security或shiro來控制。當然也可以從權限模型或者權限框架的角度去解決這個問題,但適用性有限。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!
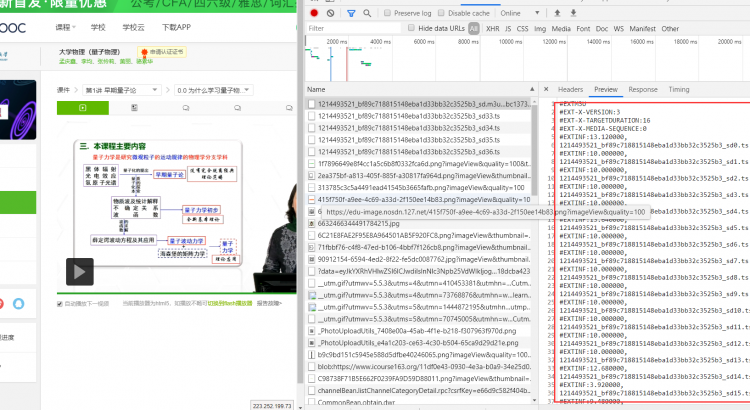
m3u8是一種很常見的網頁視頻播放器的視頻源,比如說中國大學MOOC中課程就是使用了該種視頻格式。
隨便打開一門課程,就可以發現在網絡請求中存在一個m3u8的文件,在preview中預覽,它並不像我們想象中是亂碼的視頻流。
裏面是一個列表,有一堆ts結尾的文件名,每個下面還跟了一個EXTINF的字段,好像是時間,在我們播放視頻時,網絡請求中會不斷出現請求ts的內容。
隨便打開一個ts文件,它的內容卻是如圖視頻流一般亂碼的。
說到這裏,你可能有猜測了,m3u8並不是視頻流的文件,而有可能是組織ts文件的規範,EXTINF代表播放每多少秒去請求下一片ts流。
這種邊看邊加載的方法無疑可以減少我們的網絡負荷。
要用爬蟲爬取這類視頻的方法也很簡單,我們只需要獲得m3u8文件,就可以得到視頻的ts地址了,將所有ts請求下來之後進行合併,就可以得到視頻文件了。
不過要提的一點是,很多視頻網站會對他們的ts進行加密,我們下載下來合併之後可能視頻能看,但是播放器放着放着就卡住了,然後之後黑屏畫面。
我們先根據m3u8來判斷一下創建咋樣一個代表M3U8視頻對象的類。
我們首先需要定義一個list,來存放這個m3u8視頻下所有的ts文件,也就是後面說到的TS類。
這裏提一點,m3u8裏面的ts的路徑一般對路徑,會和m3u8在同一文件夾,我們代碼中也是這麼認為了,但是難免有些網站會單獨存放m3u8和ts文件,如果遇到這種情況,修改一下代碼即可。
有了ts的名稱,我們還需要URL的前綴,也就是圖中紫色劃線部分,也就是basepath。
此外,我們還需要一個TS對象。
這個對象中存儲TS文件名稱以及時間EXTINF。
定義完實體類,就需要編寫下載視頻的過程了。
首先需要請求到m3u8的文件,此處使用Java的HttpURLConnection來請求獲取,其它語言類似,只需要請求到文件即可。
請求到了m3u8的文本內容,我們還需要解析它 ,從中得到ts的名稱。
得到了M3U8視頻對象之後,我們就可以遍歷請求它的list中TS對象的名稱屬性來下載ts文件了。
這麼多ts文件如果我們在單線程中遍歷請求,會很耗費時間,Java給我們提供了Stream,其中parallel可以讓我們併發去遍歷集合,效率會提升不少。
依舊是使用HttpURLConnection來做請求,不過最好本次設置超時時間。
這樣就可以請求到所有ts文件了。
最後要做的就是合併這些ts文件成為一個MP4文件。
對於未加密的正常ts文件,我們只需要按照編號順序直接拼接即可。
這樣就算是完成了M3U8視頻抓取了。
下載地址:
在命令行中java -jar m3u8-down.jar [m3u8地址],會显示報錯信息。
也可以直接m3u8-down.jar [m3u8地址],不會显示保存信息,會在後台執行。
最終會在同目錄下生成一個output.mp4的文件,temp文件可以刪除。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包"嚨底家"
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整