在本號之前的文章中,已經為大家介紹了很多關於Spring Security的使用方法,也介紹了RBAC的基於角色權限控制模型。但是很多朋友雖然已經理解了RBAC控制模型,但是仍有很多的問題阻礙他們進一步開發。比如:
- RBAC模型的表結構該如何創建?
- 具體到某個頁面,某個按鈕權限是如何控制的?
- 為了配合登錄驗證表,用戶表中應該包含哪些核心字段?
- 這些字段與登錄驗證或權限分配的需求有什麼關係?
那麼本文就希望將這些問題,與大家進行一下分享。
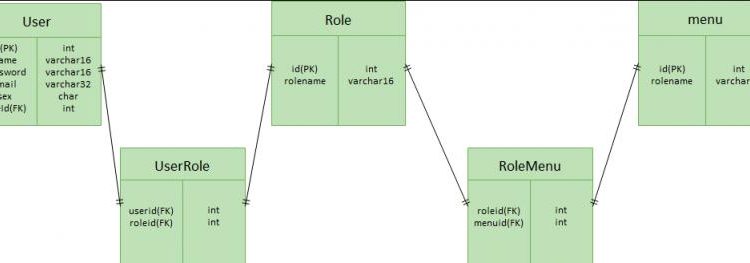
一、回顧RBAC權限模型
- 用戶與角色之間是多對多的關係,一個用戶有多個角色,一個角色包含多個用戶
- 角色與權限之間是多對多關係,一個角色有多種權限,一個權限可以屬於多個角色
上圖中:
- User是用戶表,存儲用戶基本信息
- Role是角色表,存儲角色相關信息
- Menu(菜單)是權限表,存儲系統包含哪些菜單及其屬性
- UserRole是用戶和角色的關係表
- RoleMenu是角色和權限的關係表
本文講解只將權限控制到菜單的訪問級別,即控制頁面的訪問權限。如果想控制到頁面中按鈕級別的訪問,可以參考Menu與RoleMenu的模式同樣的實現方式。或者乾脆在menu表裡面加上一個字段區別該條記錄是菜單項還是按鈕。
為了有理有據,我們參考一個比較優秀的開源項目:若依後台管理系統。
二、組織部門管理
2.1.需求分析
之所以先將部門管理提出來講一下,是因為部門管理沒有在我們上面的RBAC權限模型中進行提現。但是部門這樣一個實體仍然是,後端管理系統的一個重要組成部分。通常有如下的需求:
- 部門要能體現出上下級的結構(如上圖中的紅框)。在關係型數據庫中。這就需要使用到部門id及上級部門id,來組合成一個樹形結構。這個知識是SQL學習中必備的知識,如果您還不知道,請自行學習。
- 如果組織與用戶之間是一對多的關係,就在用戶表中加上一個org_id標識用戶所屬的組織。原則是:實體關係在多的那一邊維護。比如:是讓老師記住自己的學生容易,還是讓學生記住自己的老師更容易?
- 如果組織與用戶是多對多關係,這種情況現實需求也有可能存在。比如:某人在某單位既是生產部長,又是技術部長。所以他及歸屬於技術部。也歸屬於生產部。對於這種情況有兩種解決方案,把該人員放到公司級別,而不是放到部門級別。另外一種就是從數據庫結構上創建User與Org組織之間的多對多關係。
- 組織信息包含一些基本信息,如組織名稱、組織狀態、展現排序、創建時間
- 另外,要有基本的組織的增刪改查功能
2.2 組織部門表的CreateSQL
以下SQL以MySQL為例:
CREATE TABLE `sys_org` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`org_pid` INT(11) NOT NULL COMMENT '上級組織編碼',
`org_pids` VARCHAR(64) NOT NULL COMMENT '所有的父節點id',
`is_leaf` TINYINT(4) NOT NULL COMMENT '0:不是恭弘=叶 恭弘子節點,1:是恭弘=叶 恭弘子節點',
`org_name` VARCHAR(32) NOT NULL COMMENT '組織名',
`address` VARCHAR(64) NULL DEFAULT NULL COMMENT '地址',
`phone` VARCHAR(13) NULL DEFAULT NULL COMMENT '電話',
`email` VARCHAR(32) NULL DEFAULT NULL COMMENT '郵件',
`sort` TINYINT(4) NULL DEFAULT NULL COMMENT '排序',
`level` TINYINT(4) NOT NULL COMMENT '組織層級',
`status` TINYINT(4) NOT NULL COMMENT '0:啟用,1:禁用',
PRIMARY KEY (`id`)
)
COMMENT='系統組織結構表'
COLLATE='utf8_general_ci'
ENGINE=InnoDB
;注意:mysql沒有oracle中的start with connect by的樹形數據匯總SQL。所以通常需要為了方便管理組織之間的上下級樹形關係,需要加上一些特殊字段,如:org_pids:該組織所有上級組織id逗號分隔,即包括上級的上級;is_leaf是否是恭弘=叶 恭弘子結點;level組織所屬的層級(1,2,3)。
三、菜單權限管理
3.1 需求分析
- 由上圖可以看出,菜單仍然是樹形結構,所以數據庫表必須有id與menu_pid字段
- 必要字段:菜單跳轉的url、是否啟用、菜單排序、菜單的icon矢量圖標等
- 最重要的是菜單要有一個權限標誌,具有唯一性。通常可以使用菜單跳轉的url路徑作為權限標誌。此標誌作為權限管理框架識別用戶是否具有某個頁面查看權限的重要標誌
- 需要具備菜單的增刪改查基本功能
- 如果希望將菜單權限和按鈕超鏈接相關權限放到同一個表裡面,可以新增一個字段。用戶標誌該權限記錄是菜單訪問權限還是按鈕訪問權限。
3.2 菜單權限表的CreateSQL
CREATE TABLE `sys_menu` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`menu_pid` INT(11) NOT NULL COMMENT '父菜單ID',
`menu_pids` VARCHAR(64) NOT NULL COMMENT '當前菜單所有父菜單',
`is_leaf` TINYINT(4) NOT NULL COMMENT '0:不是恭弘=叶 恭弘子節點,1:是恭弘=叶 恭弘子節點',
`name` VARCHAR(16) NOT NULL COMMENT '菜單名稱',
`url` VARCHAR(64) NOT NULL COMMENT '跳轉URL',
`icon` VARCHAR(45) NULL DEFAULT NULL,
`icon_color` VARCHAR(16) NULL DEFAULT NULL,
`sort` TINYINT(4) NULL DEFAULT NULL COMMENT '排序',
`level` TINYINT(4) NOT NULL COMMENT '菜單層級',
`status` TINYINT(4) NOT NULL COMMENT '0:啟用,1:禁用',
PRIMARY KEY (`id`)
)
COMMENT='系統菜單表'
COLLATE='utf8_general_ci'
ENGINE=InnoDB
;四、角色管理
上圖為角色修改及分配權限的頁面
4.1.需求分析
- 角色本身的管理需要注意的點非常少,就是簡單的增刪改查。重點在於角色分配該如何做。
- 角色表包含角色id,角色名稱,備註、排序順序這些基本信息就足夠了
- 為角色分配權限:以角色為基礎勾選菜單權限或者操作權限,然後先刪除sys_role_menu表內該角色的所有記錄,在將新勾選的權限數據逐條插入sys_role_menu表。
- sys_role_menu的結構很簡單,記錄role_id與menu_id,一個角色擁有某一個權限就是一條記錄。
- 角色要有一個全局唯一的標識,因為角色本身也是一種權限。可以通過判斷角色來判斷某用戶的操作是否合法。
- 通常的需求:不會在角色管理界面為角色添加用戶,而是在用戶管理界面為用戶分配角色。
4.2.角色表與角色菜單權限關聯表的的CreateSQL
CREATE TABLE `sys_role` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`role_id` VARCHAR(16) NOT NULL COMMENT '角色ID',
`role_name` VARCHAR(16) NOT NULL COMMENT '角色名',
`role_flag` VARCHAR(64) NULL DEFAULT NULL COMMENT '角色標識',
`sort` INT(11) NULL DEFAULT NULL COMMENT '排序',
PRIMARY KEY (`id`)
)
COMMENT='系統角色表'
COLLATE='utf8_general_ci'
ENGINE=InnoDB
;CREATE TABLE `sys_role_menu` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`role_id` VARCHAR(16) NOT NULL COMMENT '角色ID',
`menu_id` INT(11) NOT NULL COMMENT '菜單ID',
PRIMARY KEY (`id`)
)
COMMENT='角色菜單多對多關聯表'
COLLATE='utf8_general_ci'
ENGINE=InnoDB
;五、用戶管理
5.1.需求分析
- 上圖中點擊左側的組織菜單樹結點,要能显示出該組織下的所有人員(系統用戶)。在組織與用戶是一對多的關係中,需要在用戶表加上org_id字段,用於查詢某個組織下的所有用戶。
- 用戶表中要保存用戶的用戶名、加密后的密碼。頁面提供密碼修改或重置的功能。
- 角色分配:實際上為用戶分配角色,與為角色分配權限的設計原則是一樣的。所以可以參考。
- 實現用戶基本信息的增刪改查功能
5.2.sys_user 用戶信息表及用戶角色關係表的CreateSQL
CREATE TABLE `sys_user` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`org_id` INT(11) NOT NULL,
`username` VARCHAR(64) NULL DEFAULT NULL COMMENT '用戶名',
`password` VARCHAR(64) NULL DEFAULT NULL COMMENT '密碼',
`enabled` INT(11) NULL DEFAULT '1' COMMENT '用戶賬戶是否可用',
`locked` INT(11) NULL DEFAULT '0' COMMENT '用戶賬戶是否被鎖定',
`lockrelease_time` TIMESTAMP NULL '用戶賬戶鎖定到期時間',
`expired_time` TIMESTAMP NULL '用戶賬戶過期時間',
`create_time` TIMESTAMP NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '用戶賬戶創建時間',
PRIMARY KEY (`id`)
)
COMMENT='用戶信息表'
ENGINE=InnoDB
;CREATE TABLE `sys_user_role` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`role_id` VARCHAR(16) NULL DEFAULT NULL,
`user_id` VARCHAR(18) NULL DEFAULT NULL,
PRIMARY KEY (`id`)
)
COLLATE='utf8_general_ci'
ENGINE=InnoDB
;在用戶的信息表中,體現了一些隱藏的需求。如:多次登錄鎖定與鎖定到期時間的關係。賬號有效期的設定規則等。
當然用戶表中,根據業務的不同還可能加更多的信息,比如:用戶頭像等等。但是通常在比較大型的業務系統開發中,業務模塊中使用的用戶表和在權限管理模塊使用的用戶表通常不是一個,而是根據某些唯一字段弱關聯,分開存放。這樣做的好處在於:經常發生變化的業務需求,不會去影響不經常變化的權限模型。
期待您的關注
- 向您推薦博主的系列文檔:
- 本文轉載註明出處(必須帶連接,不能只轉文字):。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※平板收購,iphone手機收購,二手筆電回收,二手iphone收購-全台皆可收購
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益