對於DevOps的理解大家眾說紛紜,就連維基百科(Wikipedia)都沒有給出一個統一的定義。一般的解釋都是從字面上來理解,就是把開發(Development)和運維(Operations)整合到一起,來加速產品從啟動到上線的過程,並使之自動化。這個是對DevOps的廣義解釋,而且大多數人都是認可的。但這個解釋太寬泛了,幾乎包括了IT的所有內容,使之沒有太大意義。 而DevOps是近幾年才興起的(2014年才開始流行),它是對某種項目模式的描述,是有着其特定內涵的。任何項目都可以分成開發和運維兩個部分,而開發的一整套流程和工具在DevOps之前早就有了,並沒有改變。
DevOps真正改變的是運維。因此從運維的角度去理解DevOps,才能抓住它的本質。你可以把它理解為用開發的方式做運維(Operation as Development),這就是對它的狹義的理解。 開發的方式就是寫代碼,換句話說DevOps就是通過寫代碼來做運維。運維里一個非常流行的概念叫“Iac()” 基礎設施即代碼,也就是把運行環境的創建用代碼的形式來描述出來,通過運行代碼來創建環境。它是運維領域的一場革命,開創了現代運維技術,它也是DevOps的基石。但基礎設施創建只是運維的一部分,如果我們把這場革命繼續延伸到運維的各個領域,讓代碼覆蓋整個運維,那時就是代碼即運維(Operation as Code),這才是DevOps的精髓。
那麼從一個應用程序項目的角度看,什麼是DevOps呢?它就是把應用程序的代碼和運維的代碼都放到一個源程序庫中,並對它進行版本管理,這樣你就擁有了關於這個項目的所有信息,隨時可以部署這個程序(包括程序本身和它的運行環境),而且可以保證每次創建出來的程序的運行結果是一樣的(因為它的運行環境也是一樣的)。
運維即代碼(Operation as Code):
下面我們就把運維所做的事情一件一件拆分開,看看他們是怎麼用代碼來實現的。
運維的工作通常包括下面幾個方面:
- 基礎設施:即程序運行環境的創建和維護。
- 持續部署:部署應用程序,並使整個過程自動化。
- 服務的健壯性:是指當服務的的運行環境出現了問題,例如網絡故障或服務過載或某些微服務宕機的情況下,程序仍能夠提供部分或大部分服務。
- 運行監測:它既包含對程序的監測也包含對運行環境的監測。
基礎設施即代碼 (Infrastructure as code)
我們通過一個Go(別的語言也大同小異)微服務程序做例子來展示如何用代碼來創建基礎設施。程序本身的功能非常簡單,只是用SQL語句訪問數據庫中的數據,並寫入日誌。你可以簡單地把它分成兩層,後端數據訪問層和數據庫層。程序的部署環境是基於k8s的容器環境。在k8s中它被分成兩個服務。一個是後端程序服務,另一個是數據庫(用MySQL)服務。後端程序要調用數據庫服務,然後會把一些數據寫入日誌。
在這種新的模式下,運行環境的代碼和應用程序的代碼是存在一個源碼庫中的,這樣當你下載了源碼庫之後,你不但擁有了程序的所有源碼,而且也擁有了運行環境的源碼。這樣當要創建新的運行環境時,只要運行一遍代碼就能創建出整套的運行環境,而且每次創建出來的環境都是一致的。
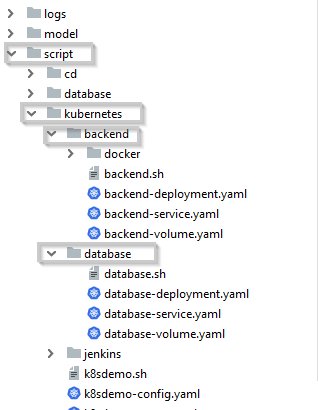
上面就是這個Go程序的目錄結構,它裏面有一個目錄“script”是專門存放與運行環境相關的文件的,裏面的“kuburnetes”子目錄就是整個運行環境的代碼。除了“script”之外的其它目錄存有應用程序的代碼。這樣,與這個應用程序有關的信息都以代碼的方式保存在了一個源代碼庫。有了它之後,你可以隨時部署出一個相同的程序的運行環境,而且保證是一模一樣的。
“kubernetes”目錄下有兩個子目錄“backend”和“database”分別存放後端程序和數據庫的配置文件。它們內部的結構是類似的,都有三個“yaml”文件:
- backend-deployment.yaml:部署配置文件,
- backend-service.yaml:服務配置文件
- backend-volume.yaml:持久卷配置文件.
另外還有一個“.sh”文件是它的運行命令,當你運行這個shell文件時,它就調用上面三個k8s配置文件來創建運行環境。
kubernetes目錄的最外層有兩個“yaml”文件“k8sdemo-config.yaml”和”k8sdemo-secret.yaml”,它們是用來創建k8s運行環境參數的,因為它們是被不同服務共享的,因此放在最外層。另外還有一個”k8sdemo.sh”文件是k8s命令文件,用來創建k8s對象。
這種源程序結構的一個好處就是使應用程序和它的運行環境能夠更好地集成。舉個例子,當你要修改服務的端口時,以前,你需要在運行環境和源碼里分別修改,但它是分別由開發和運維完成的,這很容易造成修改的不同步。當你把它們放在同一個源碼庫中,只需要修改一個地方,這樣就保證了應用程序和運行環境的一致性。
下面就是後端服務的k8s配置代碼:
apiVersion: v1
kind: Service
metadata:
name: k8sdemo-backend-service
labels:
app: k8sdemo-backend
spec:
type: NodePort
selector:
app: k8sdemo-backend
ports:
- protocol : TCP
nodePort: 32080
port: 80
targetPort: 8080由於篇幅的關係,這裏就不詳細解釋程序了,有興趣的請參見.
基礎設施可以分成兩個層面,一個就是上面講到的k8s層面,也就是容器層面,這個是跟應用程序緊密相關的。還有一個層面就是容器下面的支持層,也就是虛機層面,當然還包括網絡,負載均衡等設備或軟件。當你在阿里雲或華為雲上創建k8s之前,先要把這些構建好才行。它的部署也可以用代碼來完成。Terraform就是一款非常流行的用來完成創建的工具,它是被ThoughtWorks推薦的(詳見 ),它支持用代碼來創建虛機。
代碼如下:
resource "aws_instance" "example" {
count = 10
ami = "ami-v1"
instance_type = "t2.micro"
}但在這一層面,基礎設施的工作與應用程序的關聯並沒有那麼緊密,因此這部分的代碼沒有放在應用程序里,你可以單獨創建一個基礎設施的源碼項目,用來存放這部分代碼。
持續部署(Continuous Deployment)
部署應用程序是運維的一項重要工作。隨着商業競爭的加劇,要求更快的程序更新,從原來的的幾周部署一次,到後來的一天部署十幾次甚至幾十次。這樣手工部署就完全不能滿足需要,於是就要把整個流程自動化,這就是持續部署。
管線(pipeline)是一個很重要的概念,它用來描述持續部署的整個步驟和流程。Jenkin是一款非常流行的持續集成和部署工具,它提出了“管線即代碼”(“Pipeline as code”,詳見)。就是把持續部署的管線也作為程序源碼的一部分,和應用程序一起管理起來,讓它有着和應用程序一樣的版本和複審流程。
下面我們就通過一個具體例子來說明他是怎樣實現的。這個例子用的是和上面一樣的程序。先來看一下程序的目錄結構。
與持續部署相關的文件都在“script”目錄下,他被分成兩部分,一個是“cd”子目錄,它存有Jenkins的管線,另一個是“Kubernetes”下的“jenkins”子目錄,它存有Jenkinsde的k8s配置文件。你如果仔細看一下的話會發現它裏面的文件和前面講到的後端程序和數據庫的k8s配置文件很相似,有了它,你就可以在k8s里創建出Jenkins的運行環境。
這裏我把Jenkins的k8s配置文件也放在應用程序里了,但實際上它是應該放在前面提到的基礎設施項目源碼里。因為Jenkins是被應用程序共享的,而不是屬於單獨的一個應用。這裏為了說明方便放在一起了,真正用的時候要把它抽取出來。
下面就是管線的代碼:
def POD_LABEL = "k8sdemopod-${UUID.randomUUID().toString()}"
podTemplate(label: POD_LABEL, cloud: 'kubernetes', containers: [
containerTemplate(name: 'modified-jenkins', image: 'jfeng45/modified-jenkins:1.0', ttyEnabled: true, command: 'cat')
],
volumes: [
hostPathVolume(mountPath: '/var/run/docker.sock', hostPath: '/var/run/docker.sock')
]) {
node(POD_LABEL) {
def kubBackendDirectory = "/script/kubernetes/backend"
stage('Checkout') {
container('modified-jenkins') {
sh 'echo get source from github'
git 'https://github.com/jfeng45/k8sdemo'
}
}
stage('Build image') {
def imageName = "jfeng45/jenkins-k8sdemo:${env.BUILD_NUMBER}"
def dockerDirectory = "${kubBackendDirectory}/docker/Dockerfile-k8sdemo-backend"
container('modified-jenkins') {
withCredentials([[$class: 'UsernamePasswordMultiBinding',
credentialsId: 'dockerhub',
usernameVariable: 'DOCKER_HUB_USER',
passwordVariable: 'DOCKER_HUB_PASSWORD']]) {
sh """
docker login -u ${DOCKER_HUB_USER} -p ${DOCKER_HUB_PASSWORD}
docker build -f ${WORKSPACE}${dockerDirectory} -t ${imageName} .
docker push ${imageName}
"""
}
}
}
stage('Deploy') {
container('modified-jenkins') {
sh "kubectl apply -f ${WORKSPACE}${kubBackendDirectory}/backend-deployment.yaml"
sh "kubectl apply -f ${WORKSPACE}${kubBackendDirectory}/backend-service.yaml"
}
}
}
}由於篇幅的關係,這裏不詳細解釋。如果有興趣並想了解如何運行Jenkins來完成持續部署,請參閱 .
這裏我用的是Jenkins軟件,它另外還有一個子項目叫Jenkins-x,是專門為k8s環境量身打造的,它的主要功能是能夠幫助你自動生成管線代碼(你需要回答他的一些問題)。如果你不想自己寫代碼,那麼你可以試一下它,詳情請見。
服務的韌性(Service Resilience as Code)
又叫服務的健壯性,這部分不像前面兩個部分有着公認的名字,英文叫“Service Resilience”,翻譯成中文就五花八門了,我覺得叫服務的韌性比較合適。
“Service Resilience”是指當服務的的運行環境出現了問題,例如網絡故障或服務過載或某些微服務宕機的情況下,程序仍能夠提供部分或大部分服務,這時我們就說服務的韌性很強。它是衡量服務質量的一個重要指標。
這部分的功能包括下面幾個部分:
- 服務超時 (Timeout)
- 服務重試 (Retry)
- 服務限流(Rate Limiting)
- 熔斷器 (Circuit Breaker)
- 故障注入(Fault Injection)
- 艙壁隔離技術(Bulkhead)
這部分與前面兩個部分略有不同,前面兩個部分都是典型的運維任務,而這部分以前是應用程序的一部分,只是這些年才慢慢開始轉移到運維的。
最開始的時候,這些功能都是和程序的業務邏輯混在一起,對業務邏輯的侵入很大,後來,大家開始把這部分邏輯抽取出來,劃分成單獨的一部分。下面通過一個具體的例子(Go微服務程序)來講解:
上圖是程序的目錄結構,它分為客戶端(client)和服務端(server),它們的內部結構是類似的。“middleware”包是實現服務韌性功能的包。 “service”包是業務邏輯包,在服務端就是微服務的實現函數,在客戶端就是調用服務端的函數。在客戶端(client)下的“middleware”包中包含四個文件並實現了三個功能:服務超時,服務重試和熔斷器。“clientMiddleware.go”是總入口。在服務端(server)下的“middleware”包中包含了兩個文件並實現了一個功能,服務限流。“serverMiddleware.go”是總入口。
注意,這裏的服務韌性的功能是完全從業務邏輯中抽出來了,對業務邏輯沒有任何侵入,它是在一個單獨的包(middleware)里實現的。這裏用的是修飾模式。有關程序實現的詳情,請參閱。
上面講的是用程序來實現這些功能,但從本質上來講這些功能不應該屬於應用程序,而是應該由基礎設施來完成。現在公認的看法是,服務網格(Service Mesh)是完成這些功能的最佳方案。使用服務網格的方式和k8s類似,也是創建配置文件,然後通過運行配置文件來建立服務網格的運行環境。我們這裏用Istio來舉例說明,Istio是一款非常流行的服務網格軟件。
上圖就是下載的Istio軟件的目錄,“bookinfo”是它的一個示例程序,在這個例子里,它展示了多種使用Istio的方式,其中就有如何實現服務韌性的方法。詳情請參見.
運行監測 (Monitoring or Observability)
運行監測是運維的一項重要內容,它通常包含如下幾個方面的內容:
- 日誌(logging): 記錄的是程序運行過程中的信息
- 跟蹤(tracing): 記錄的是與一條請求相關的信息,特別是請求的與時間有關的信息。
- 指標(metrics): 與上面的離散的信息不同,這裏記錄的是可累加的信息,一般是按照時間軸進行累加。
我們經常稱之為觀測的三個支柱(Three Pillars of Observabilty),有一篇很不錯的講解它們之間關係的文章,詳情請見””。
這部分的內容可能會有些爭議。因為前幾個部分都是清清楚楚的運維工作,即使服務韌性, 雖然以前是開發的工作,但現在也已經一直公認是運維的事,而且它們的代碼都能很乾凈的摘出來。但運行監測不一樣,雖然主要工作還是由運維來完成,但它的代碼與業務邏輯代碼混在一起,很難摘得清楚。
日誌:
這部分的代碼都是在應用程序里,但日誌的採集,匯總,分析和展示都是由運維來完成。它的代表就是著名的ELK系列。採用DevOps之後,這裏面的變化不大,頂多就是採集代理(Agent)更好地和服務網格或k8s進行集成,使之變得更為容易。
分佈式跟蹤:
這部分有點像服務韌性,開始的時候是由程序完成,慢慢地把它變成單獨的部分與應用程序隔離開,最終大部分的工作交由服務網格來完成。但它又與服務韌性不太相同。服務韌性可以和應用程序做一個非常乾淨的切割,而分佈式跟蹤取決於跟蹤的顆粒度。如果僅是服務之間的跟蹤,就一點問題都沒有,完全可以由服務網格來完成。但如果是服務內部的跟蹤,服務網格就無能為力了,還是要由程序代碼來完成,就像日誌一樣。但我覺得服務之間的跟蹤是投入產出比最高的,大多數情況下有它就足夠了,不必需要服務內部的跟蹤。
詳細情況請參見
Metrics:
這部分觀測的是累加信息。大多數情況下,只要安裝好工具,就能採集數據進行分析。最流行的工具是Prometheus. 你不需要寫代碼來獲取數據,不過你如果想要快速地找到需要的信息,k8s的配置還是要和Prometheus的設置相匹配,因此你需要做一些詳細的設計。詳細情況請參見。
當然你如果有一些更細緻的監測需求,Prometheus不能直接滿足。這時需要在應用程序里插入一些Prometheus的監測代碼來滿足你的需要。
其他工作
是不是還有其他運維工作被漏掉了?
持續集成(Continious Integration)
很多人都把持續集成(CI)算作DevOps的重要組成部分,那是因為他用的是廣義的定義。按照狹義的理解,DevOps只包括運維的內容。持續集成(CI)與持續部署(CD)有着明顯的不同,持續集成是開發的工作,而持續部署是運維的工作,下圖展示了它們的差異。
如圖所示,整個流程是這樣的:
程序員從源碼庫(Source Control)中下載源代碼,編寫程序,完成后提交代碼到源碼庫,持續集成(Continuous Integration)工具從源碼庫中下載源代碼,編譯源代碼,然後提交到運行庫(Repository),然後持續交付(Continuous Delivery)工具從運行庫(Repository)中下載代碼,生成發布版本,併發布到不同的運行環境(例如DEV,QA,UAT, PROD)。
圖中,左邊的部分是持續集成,它主要跟開發和程序員有關;右邊的部分是持續部署,它主要跟測試和運維有關。持續交付(Continuous Delivery)又叫持續部署(Continuous Deployment),它們如果細分的話還是有一點區別的,但我們這裏不分得那麼細,統稱為持續部署
我並沒有把持續集成放到DevOps裏面,因為本文用的是狹義的解釋,也就是只包含運維的部分。
結論
本文從代碼的視角詮釋了對DevOps的理解,DevOps的精髓就是用寫代碼的方式來做運維,並對運維的各個部分給出了具體的實例,希望能對想採用DevOps的朋友有所幫助。DevOps對開發和運維的改變都是巨大的,尤其是對運維。在不久的將來,就沒有開發和運維之分了,只有一個工作,就是寫代碼,當然也許會細分成開發碼農和運維碼農。運維的工作都是通過寫代碼來完成。應用程序里不但包括業務邏輯的代碼,也包括運維的代碼,它們會被同時存儲在一個源碼庫中。
源碼庫
完整源碼的github鏈接:
索引:
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益