一、簡介
pytest+allure+jenkins進行接口測試、生成測試報告、結合jenkins進行集成。
pytest是python的一種單元測試框架,與python自帶的unittest測試框架類似,但是比unittest框架使用起來更簡潔,效率更高
allure-pytest是python的一個第三方庫。用於連接pytest和allure,使它們可以配合在一起使用。
allure-pytest基於pytest的原始執行結果生成適用於allure的json格式結果。該json格式結果可以用於後續適用allure生成html結果。
二、安裝
1、安裝pytest,命令行或終端中輸入
1 pip install pytest
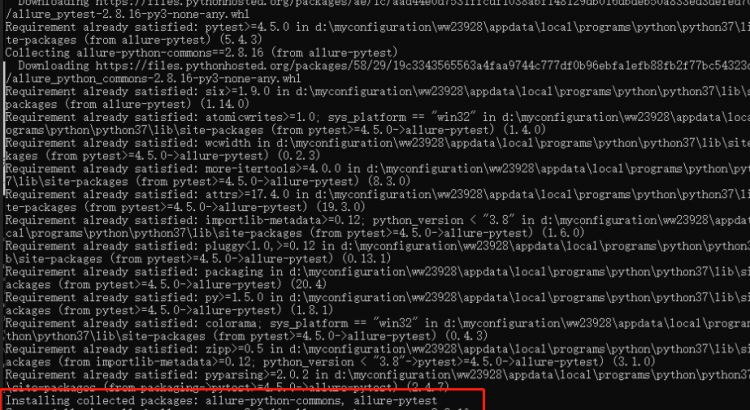
2、安裝allure-pytest,安裝成功
1 pip install allure-pytest
allure-pytest安裝成功后截圖如下。
3、下載安裝JDK
官方下載:https://www.oracle.com/java/technologies/javase-jdk11-downloads.html
安裝與配置不作闡述請諒解
4、下載安裝Jenkins
官方下載:https://www.jenkins.io/
安裝與配置不作闡述請諒解
三、下載Allure並配置
下載allure並配置
1、allure官網下載:https://github.com/allure-framework/allure2/releases
如下圖所示
2、allure2下載下來是一個zip的壓縮包,我們要解壓至自己的文件目錄下(可解壓放至項目的測試用例下或python安裝目錄下),自己可找到文件即可。
3、打開allure2目錄,找到bin目錄,複製bin文件目錄, 然後進行環境變量的配置,設置環境變量的目的就是讓系統無論在哪個目錄下都可以運行allure2。
4、環境變量設置:(桌面——我的電腦——右鍵屬性——高級系統配置——環境變量——系統變量——Path——編輯環境變量——把我們上面複製的目錄路徑新增至環境變量中即可)
設置環境變量,如下圖所示。
5、配置好后,打開cmd終端,輸入allure,出現以下幫助文檔,就說明配置成功了。
四、Allure裝飾器描述
Allure裝飾器
五、Pytest+Allure的應用
上述我們講了一些理論的知識,下面我們就來實戰練習一下吧。進一步理解Pytest+allure如何結合應用的。
1、新建testcase文件夾,用來存放測試用例,新建test_Demo.py文件,作為pytest的具體測試用例文件。在test_Demo.py文件中輸入以下代碼。
1 # test_Demo.py 2 # Creator:wuwei 3 # Date:2020-06-09 4 5 import pytest 6 import requests 7 import allure 8 import sys 9 sys.dont_write_bytecode = True 10 11 @allure.epic('測試描述'.center(30, '*')) 12 @allure.feature('測試模塊') 13 @allure.suite('測試套件') 14 class TestPytestOne(): 15 @allure.story('用戶故事描述:用例一') 16 @allure.title('測試標題:用例一') 17 @allure.description('測試用例描述:用例一') 18 @allure.testcase('測試用例地址:https://www.baidu.com/') 19 @allure.tag('測試用例標籤:用例一') 20 def test_one(self): 21 print('執行第一個用例') 22 assert 1 == 1 23 24 @allure.story('用戶故事描述:用例二') 25 @allure.title('測試標題:用例二') 26 @allure.description('測試用例描述:用例二') 27 @allure.testcase('測試用例地址:https://www.sogou.com/') 28 @allure.tag('測試用例標籤:用例二') 29 def test_two(self,action): 30 print('執行第二個用例') 31 assert True == True 32 33 # pytest運行 34 if __name__ == "__main__": 35 pytest.main(['-s', '-v', 'test_Demo.py', '-q', '--alluredir', '../reports'])
2、我們再來創建一個conftest.py,conftest用來共享數據及不同層次之間共享使用的文件,測試用例的前置和後置中一般都可以用到的。
1 # conftest.py 2 # Creator:wuwei 3 # Date:2020-06-09 4 5 import pytest 6 import sys 7 sys.dont_write_bytecode = True 8 9 @pytest.fixture() 10 def action(): 11 print("測試用例開始".center(30, '*')) 12 yield 13 print("測試用例結束".center(30, '*'))
3、運行test_Demo.py文件,test_Demo文件中已經pytest+allure的結合,可查看allure的運行結果,可看出在根目錄中生成了一個reports文件夾,其中生成了測試報告的json文件,這裏面的json文件可通過allure生成html的測試報告。
運行test_Demo.py,終端显示如下圖所示。
生成的Json格式的測試報告,如下圖所示。
4、使用allure將json文件生成html的測試報告,定位至項目文件根目錄下,運行以下命令,會在項目根目錄下生成一個名為allure_reports的文件夾,用來存放html測試報告。命令下如所示。
1 allure generate reports -o allure_reports/
成功運行allure,結果如下圖所示。
項目根目錄下的allure_reports文件,存放的是allure生成的測試報告。可看出文件下有一個HTML文件,可通過Python的編輯器Pycharm來打開該HTML文件(測試報告),或可通過allure命令來打開該HTML,展示HTML測試報告。如下所示。
測試報告文件,HTML測試報告如下。
allure命令打開HTML測試報告。命令如下所示。
1 allure open allure_reports/
如下圖所示。
打開生成的HTML測試報告如下圖所示。
六、Pytest+Allure+Jenkins的應用
1、Jenkins插件網站上下載allure插件最新版本:
http://mirrors.jenkins-ci.org/plugins/allure-jenkins-plugin/
2、Jenkins的安裝我已經在Postman+Newman+Git+Jenkins的篇章中講過了,沒看小夥伴可以看一下那篇文章。確認Jenkins服務是否開啟。確認開啟后,在瀏覽器中輸入:http://localhost:8080/,進入Jenkins配置頁面。
3、http://localhost:8080/,登錄Jenkins的頁面,在管理Jenkins——插件管理——高級中找到上傳插件。將(1)步驟中下載的.hpi的文件上傳至jenkins上。
上傳安裝好的allure-jenkins-plugin的插件,安裝完成並成功,是藍色圓點显示,因我已經安裝過一次,會提示已經安裝,重啟Jenkins即可生效。(注意:不是關閉瀏覽器重新打開,而是重啟Jenkins服務)
4、全局變量中配置allure路徑與JDK的路徑,
配置JDK安裝的路徑,如下圖所示。
配置allure安裝的路徑,如下圖所示。
5、新建Item,配置構建后的allure測試報告生成。這裏配置Pytest執行完成之後,生成的allure文件所在的目錄位置。
項目中生成allure的json測試報告的位置。需與下面構建后操作中的Results的Path文件一致。
構建后操作的allure生成測試報告的配置,如下圖所示
6、配置構建命令。就是上述在cmd中運行項目時的命令。如下圖所示。
注意:運行后發現有報錯。“Build step ‘Execute Windows batch command’ marked build as failure”,解決方案,在運行項目的命令后添加exit 0。如下圖所示。
7、修改運行命令后我們再來運行一下。我們可發現運行后,allure裏面沒任務數據。因為我們還沒設置運行的項目路徑。設置工作空間,打開工作空間目錄,將我們的項目複製到jenkins的工作目錄中。
我們可將代碼傳至GitHub上,在Jenkins中設置相關Github項目的配置,也可進行Jenkins部署。我在Postman+Newman+Git+Jenkins這篇博客里就應用到了。有興趣的可參考看看這篇Jenkins如何Git項目。在這裏我們使用本地項目來部署。
測試報告無數據因為工作空間裏面沒有項目配置。
複製項目至Jenkins工作空間的目錄中。
8、添加項目后,我們再運行一下,藍點則為運行成功,可看到後面已經生成了allure的測試報告了。可直接點擊後面的alluree圖標跳轉至HTML的測試報告。如下圖所示。
allure生成的HTML測試報告
八、總結
上述我們聊了下pytest+allure+jenkins如何結合集成一起使用的,本地啟動jenkins,運行項目,調用allure生成測試報告。也簡單的做了一個小Demo。後期我將結合Requests接口測試和seleniumWeb測試應用至具體項目中。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家公司費用,距離,噸數怎麼算?達人教你簡易估價知識!
※教你寫出一流的銷售文案?
※超省錢租車方案
※回頭車貨運收費標準