環境資訊中心綜合外電;姜唯 編譯;彭瑞祥 審校
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※教你寫出一流的銷售文案?
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※回頭車貨運收費標準
※別再煩惱如何寫文案,掌握八大原則!
※超省錢租車方案
※產品缺大量曝光嗎?你需要的是一流包裝設計!
摘錄自2019年9月23日公視報導
瑞士居民為阿爾卑斯山的冰川舉行了葬禮,受氣候變遷影響,這座冰川從2006年消融速度加快,現在已經消失了90%面積。
大約250個瑞士居民,22日穿著黑衣,披著黑頭紗爬了約兩小時的路程,登上海拔約2700公尺的皮措爾山山頂,為這座即將消失的冰川舉行葬禮。
瑞士蘇黎世聯邦理工學院冰川專家赫斯表示,「照目前情況來看,我們還有約4個足球場大小的冰川,但過去兩年冰川消融的速度迅速增加。」
皮措爾冰川位在瑞士境內的阿爾卑斯山,自從2006年以來,已經失去了將近90%面積,現在只剩下約兩萬6000平方公尺,不到四個足球場大小,科學家認為,冰川消融如此快速是受到氣候變遷影響,如果再不控制溫室氣體排放,這座冰川將會在2030年前完全消失。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※超省錢租車方案
※別再煩惱如何寫文案,掌握八大原則!
※回頭車貨運收費標準
※教你寫出一流的銷售文案?
※FB行銷專家,教你從零開始的技巧
摘要:面對如何在現有的低版本的框架服務上,運行新版本的前端服務問題,華為雲前端推出了一種融合方案,該方案能讓獨立的Angular項目整體運行在低版本的框架服務上,通過各種適配手段,讓Angular項目也能獲取到外層框架服務的資源。
華為雲前端服務前期採用AngularJs作為框架技術棧,技術較為老舊,性能較差,在華為雲快速發展的今天,顯然不能滿足要求。因此我們必須要升級前端技術棧,使用Angular2+來承載我們的前端服務。GeminiDB作為新服務,也是數據庫乃至華為雲未來的重點服務,作為前端部分,必須在技術上使用最前沿的框架,以最大地提高用戶體驗。
但是技術棧的升級不是一蹴而就的,尤其是在華為雲,所有的雲服務必須在框架服務的底座上運行,而框架服務承載了所有的雲服務,如果要進行技術棧升級,必然是一個緩慢的過程。GeminiDB作為華為雲服務里的一員,也不可能脫離框架服務而存在。因此存在一個問題,就是如何在現有的低版本的框架服務上,運行新版本的前端服務。
為了解決以上問題,華為雲前端推出了一種融合方案,該方案能讓獨立的Angular項目整體運行在低版本的框架服務上,通過各種適配手段,讓Angular項目也能獲取到外層框架服務的資源。
底層項目使用webpack打包,打包后通過在index.html里引入businessAll.js文件,以該文件為入口啟動整個框架服務。
<script type="text/javascript" src="businessAll.js"></script>
在底層框架服務啟動后,再渲染出具體雲服務內容。
<div class="service-content-view" ui-view ng-animate="{enter:'fade-enter'}"></div>
Angular項目支持獨立運行,有單獨的index.html,也有單獨的main.ts入口。但是如果希望Angular項目運行在底層框架服務上,就必須把Angular項目看作是一個獨立的模塊,把項目整體引入到底層項目中。因此,我們可以預先把Angular項目編譯好,放到底層項目的一個目錄下。在運行底層項目時,在index.html里將Angular項目引進來,獨立運行。
<link rel="stylesheet" type="text/css" href="{底層項目中Angular項目的路徑}/styles.css" /> <script type="text/javascript" src="{底層項目中Angular項目的路徑}/runtime.js"></script> <script type="text/javascript" src="{底層項目中Angular項目的路徑}/polyfills.js"></script> <script type="text/javascript" src="{底層項目中Angular項目的路徑}/main.js"></script>
底層項目和Angular項目均能獨立,但是要讓兩者融合起來,會遇到以下幾個問題:
1.底層項目中如何渲染出Angular項目。
2.Angular項目依賴底層項目的資源,如何保證Angular項目在底層項目運行起來后再運行。
3.如何解決底層項目和Angular項目的路由衝突問題。
底層項目分為兩部分,一部分是底層框架服務,另一部分是具體雲服務。現在我們要做的是把老的雲服務項目替換成新的Angular項目,因此我們可以直接在渲染老的雲服務的地方替換成新的Angular項目的渲染容器。
<div class="service-content-view" ui-view ng-animate="{enter:'fade-enter'}"></div> <app-root></app-root>
底層框架服務對頁面渲染上做了一些體驗上的優化,因此必須保留原模板中的ui-view,使底層項目正常運行起來,實際上老的雲服務項目的渲染內容已經轉發到新的Angular項目上面。
底層框架服務給雲服務提供了很多公共變量與服務,這些變量和服務是各個雲服務必須要使用的,否則雲服務將不能正常運作。
對於Angular項目來說,要使用底層框架服務提供的內容,首先要求Angular項目在底層項目運行起來之後再運行。這裏採用Augular中的APP_INITIALIZER令牌來解決這個問題。APP_INITIALIZER是一個函數,在程序初始化的時候被調用。這裡在根模塊的providers中以factory的形式來配置。
import { BrowserModule } from "@angular/platform-browser";
import { NgModule } from "@angular/core";
import { AppInitService } from './services/app-init.service';
import { AppComponent } from "./app.component";
@NgModule({
declarations: [AppComponent],
imports: [BrowserModule],
providers: [
AppInitService,
{
provide: APP_INITIALIZER,
useFactory: initializeApp,
deps: [AppInitService],
multi: true
}
],
bootstrap: [AppComponent]
})
export class AppModule {}
export function initializeApp(appInitService: AppInitService) {
return (): Promise<any> => {
return appInitService.Init();
};
}
在appInitService里,先獲取到底層框架的資源,再進行Angular項目的初始化。
import { Injectable } from '@angular/core';
@Injectable()
export class AppInitService {
constructor() {}
Init() {
return new Promise<void>((resolve, reject) => {
// 獲取到底層框架服務的資源
resolve();
});
}
}
底層項目使用的是AngularJs,Angular項目獲取底層框架服務提供的資源不能通過Angular的方式引入,因此需要藉助AngularJS的注入器獲取在底層框架中註冊的服務組件:
static get(inject: string): any { return (window as any).angular.element('html').injector().get(inject);} 如,要獲取 $rootScope: rootScope = (window as any).angular.element('html').injector().get(‘$rootScope’);
Angular項目本身有自己的路由,但是Angular項目是運行在底層框架之上的,Angular項目的路由將會被底層框架所攔截。因此,我們也需要在底層框架的項目中配置相同的路由,以免Angular項目中的有效路由被底層框架識導向為404。
Angular項目路由:
{ path: '', redirectTo: 'ng2app1', pathMatch: 'full' }, { path: 'ng2app1', loadChildren: './ng2app1/ng2app1.module#Ng2app1Module', }, { path: 'ng2app2', loadChildren: './ng2app2/ng2app2.module#Ng2app2Module', } 底層框架路由: var configArr = [ { name: 'ng2app1', url: '/ng2app1' }, { name: 'ng2app2', url: '/ng2app2' } ];
另外,由於底層項目使用的是hash路由,Angular項目中也要做相應的配置,默認是使用的是PathLocationStrategy,需要切換到hash模式。
import { LocationStrategy, HashLocationStrategy } from '@angular/common';
...
providers: [
{
provide: LocationStrategy,
useClass: HashLocationStrategy
}
]
以上方案是在底層框架升級周期長的前提下的一個臨時方案,實際上還是存在着不少的問題。比如底層框架對於老的雲服務容器是有統一管理的,老的雲服務容器會針對不同的場景能夠自適應,而融合方案中的Angular項目則不能;每次啟動整個項目時,必須要預先編譯好裏面的Angular項目,再去啟動外層的底層框架,開發效率比較低。因此,後續GeminiDB服務應該在底層框架升級后,儘快適應到新的底層框架體系中,提高服務的可用性和穩定性。
點擊關注,第一時間了解華為雲新鮮技術~
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※幫你省時又省力,新北清潔一流服務好口碑
※回頭車貨運收費標準
由於身處一家網絡公司,日常項目中涉及到的網絡概念較多,恰逢之後公司組織相關培訓。藉此機會,打算寫下一系列文章用於之后梳理並回顧。文章主要涉及 NA,NP 中所覆蓋的知識。由於網絡分為較多方向,如路由交換,無線,安全等。在今年,大綱正好有所改變,其中無線和路由交換放在一起合稱為企業架構。所以本系列文章以企業架構為主。
在網絡界,Cisco 證書一直被普遍認可,其中分為三個等級 NA,NP,IE. 對於開發人員來說,掌握 NA 水平一般即可,本系列文章會 NA 開始,到 NP 結束。NA 內容較為寬泛,其中涉及知識面較寬,但不深入,用於入門。NP 在 NA 基礎上,更加深入,涉及到更多的協議與概念。
話不多說,在閱讀本文後,應該了解以下內容:
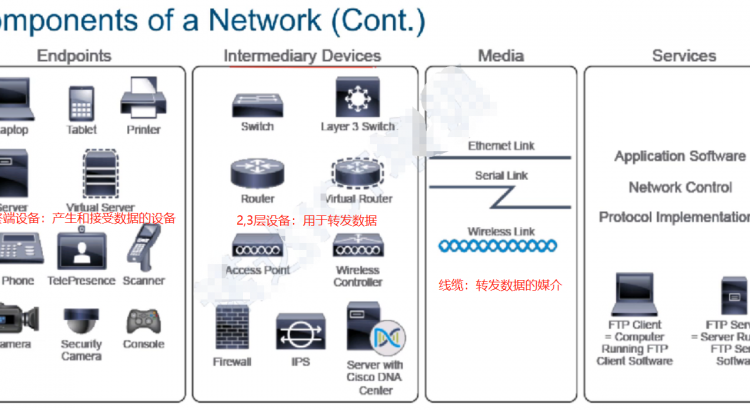
先看一下網絡的組成組件:
主要分為 4 大類:
由此可見,網絡就是由上述設備組成,在其中進行數據產生,轉發的過程。在討論網絡時,一般討論的都是企業網絡,下面是常見的一張企業網絡的架構圖。
從圖中我們可以看到,網絡的大體架構由,終端設備,接入層設備(交換機,用於將設備接入),轉發層設備(路由器)和數據中心組成。舉例子來說,如果左下角的同學 A 想要和右上角的同學 B 同學通信,則需要經歷如下過程:
設備連入的端口,稱為接口,下面是常見的接口類型。
| 接口名稱 | 速度 |
|---|---|
| Ethernet | 10M |
| Fast Ethernet | 100M |
| GigabitEthernet | 1000M |
| 10GigabitEthernet | 10000M |
| 40GigabitEthernet | 40000M |
| 100GigabitEthernet | 1000000M |
| Serial – 串行口 |
在討論或者設計一個網絡架構是,往往會在如下的方面進行討論:
表示數據的發送速率,單位為比特每秒(b/s),意思為一秒鐘發送的比特數,因此帶寬又稱為比特率。(以太網: 10Mbps, 快速以太網:100Mbps)
在設計網絡架構時,要考慮到可拓展性,公司的人數會隨着時間增加。
數據傳輸和存儲的安全。
對流量進行分類整理,拿家庭具體,分類出訪問 QQ 的流量,訪問 P2P 的流量,然後對其進行限制設置上限,防止一個服務佔用過大的帶寬,造成其他服務無法正常訪問。
設備及搭建網絡的費用。
將一個物理設備虛擬化成多個虛擬設備,例如交換機,路由器等。
物理拓撲:實際設備之間的物理連接的布局,稱為物理拓撲。
物理之間拓撲的比較:
| 拓撲類型 | 優點 | |
|---|---|---|
| 總線拓撲 | 1. 所用電纜少 2. 結構簡單 3. 易於擴充 4. 布線方便 |
1. 傳輸距離有限,通信範圍受到限制 2.故障診斷和隔離較困難 3.所有數據經過總線傳送,不具有實時功能 4. 單點故障:所有 PC 不得不共享線纜,一個節點出錯,將影響整個網絡 |
| 環形拓撲 | 1. 增加或減少工作站時,僅需要簡單的連接操作 2. 電纜長度短 3. 傳輸延遲確定 |
1. 傳輸距離有限,通信範圍受到限制 2. 故障診斷和隔離困難 3. 節點過多時影響傳輸效率 4. 任意節點出現故障,整個網絡將癱瘓 |
| 星型拓撲-局域網較為常見 | 1. 集中控制,控制簡單 2. 故障診斷和隔離容易 3. 網絡延遲短 |
1. 中央節點的負擔較重,形成瓶頸 2. 各節點的分佈處理能力較低 3. 網絡共享能里較差 |
| 部分網狀拓撲-廣域網常見 | 1. 系統可靠性高,比較容易擴展 | 1. 結構複雜,每一結點都與多點進行連結 2. 因此必須採用路由算法和流量控制方法。 |
邏輯拓撲:以數據轉發的過程為側重,描述節點之間數據的轉發過程。
在網絡中提供服務的應用種類較多,對應對網絡的要求也一般不同,可大致分為如下幾類:
本篇內容中,多為網絡的基礎概念,方便大家入門,只需理解有個印象就好。接下來的內容,才是真正學習的網絡的開始。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※幫你省時又省力,新北清潔一流服務好口碑
※回頭車貨運收費標準

熟悉React的朋友都知道,React支持jsx語法,我們可以直接將HTML代碼寫到JS中間,然後渲染到頁面上,我們寫的HTML如果有更新的話,React還有虛擬DOM的對比,只更新變化的部分,而不重新渲染整個頁面,大大提高渲染效率。到了16.x,React更是使用了一個被稱為Fiber的架構,提升了用戶體驗,同時還引入了hooks等特性。那隱藏在React背後的原理是怎樣的呢,Fiber和hooks又是怎麼實現的呢?本文會從jsx入手,手寫一個簡易版的React,從而深入理解React的原理。
本文主要實現了這些功能:
簡易版Fiber架構
簡易版DIFF算法
簡易版函數組件
簡易版Hook:
useState娛樂版
Class組件
本文代碼地址:https://github.com/dennis-jiang/Front-End-Knowledges/tree/master/Examples/React/fiber-and-hooks
本文程序跑起來效果如下:
以前我們寫React要支持JSX還需要一個庫叫JSXTransformer.js,後來JSX的轉換工作都集成到了babel裏面了,babel還提供了在線預覽的功能,可以看到轉換后的效果,比如下面這段簡單的代碼:
const App =
(
<div>
<h1 id="title">Title</h1>
<a href="xxx">Jump</a>
<section>
<p>
Article
</p>
</section>
</div>
);
經過babel轉換后就變成了這樣:
上面的截圖可以看出我們寫的HTML被轉換成了React.createElement,我們將上面代碼稍微格式化來看下:
var App = React.createElement(
'div',
null,
React.createElement(
'h1',
{
id: 'title',
},
'Title',
),
React.createElement(
'a',
{
href: 'xxx',
},
'Jump',
),
React.createElement(
'section',
null,
React.createElement('p', null, 'Article'),
),
);
從轉換后的代碼我們可以看出React.createElement支持多個參數:
- type,也就是節點類型
- config, 這是節點上的屬性,比如
id和href- children, 從第三個參數開始就全部是children也就是子元素了,子元素可以有多個,類型可以是簡單的文本,也可以還是
React.createElement,如果是React.createElement,其實就是子節點了,子節點下面還可以有子節點。這樣就用React.createElement的嵌套關係實現了HTML節點的樹形結構。
讓我們來完整看下這個簡單的React頁面代碼:
渲染在頁面上是這樣:
這裏面用到了React的地方其實就兩個,一個是JSX,也就是React.createElement,另一個就是ReactDOM.render,所以我們手寫的第一個目標就有了,就是createElement和render這兩個方法。
對於<h1 id="title">Title</h1>這樣一個簡單的節點,原生DOM也會附加一大堆屬性和方法在上面,所以我們在createElement的時候最好能將它轉換為一種比較簡單的數據結構,只包含我們需要的元素,比如這樣:
{
type: 'h1',
props: {
id: 'title',
children: 'Title'
}
}
有了這個數據結構后,我們對於DOM的操作其實可以轉化為對這個數據結構的操作,新老DOM的對比其實也可以轉化為這個數據結構的對比,這樣我們就不需要每次操作都去渲染頁面,而是等到需要渲染的時候才將這個數據結構渲染到頁面上。這其實就是虛擬DOM!而我們createElement就是負責來構建這個虛擬DOM的方法,下面我們來實現下:
function createElement(type, props, ...children) {
// 核心邏輯不複雜,將參數都塞到一個對象上返回就行
// children也要放到props裏面去,這樣我們在組件裏面就能通過this.props.children拿到子元素
return {
type,
props: {
...props,
children
}
}
}
上述代碼是React的createElement簡化版,對源碼感興趣的朋友可以看這裏:https://github.com/facebook/react/blob/60016c448bb7d19fc989acd05dda5aca2e124381/packages/react/src/ReactElement.js#L348
上述代碼我們用createElement將JSX代碼轉換成了虛擬DOM,那真正將它渲染到頁面的函數是render,所以我們還需要實現下這個方法,通過我們一般的用法ReactDOM.render( <App />,document.getElementById('root'));可以知道他接收兩個參數:
- 根組件,其實是一個JSX組件,也就是一個
createElement返回的虛擬DOM- 父節點,也就是我們要將這個虛擬DOM渲染的位置
有了這兩個參數,我們來實現下render方法:
function render(vDom, container) {
let dom;
// 檢查當前節點是文本還是對象
if(typeof vDom !== 'object') {
dom = document.createTextNode(vDom)
} else {
dom = document.createElement(vDom.type);
}
// 將vDom上除了children外的屬性都掛載到真正的DOM上去
if(vDom.props) {
Object.keys(vDom.props)
.filter(key => key != 'children')
.forEach(item => {
dom[item] = vDom.props[item];
})
}
// 如果還有子元素,遞歸調用
if(vDom.props && vDom.props.children && vDom.props.children.length) {
vDom.props.children.forEach(child => render(child, dom));
}
container.appendChild(dom);
}
上述代碼是簡化版的render方法,對源碼感興趣的朋友可以看這裏:https://github.com/facebook/react/blob/3e94bce765d355d74f6a60feb4addb6d196e3482/packages/react-dom/src/client/ReactDOMLegacy.js#L287
現在我們可以用自己寫的createElement和render來替換原生的方法了:
可以得到一樣的渲染結果:
上面我們簡單的實現了虛擬DOM渲染到頁面上的代碼,這部分工作被React官方稱為renderer,renderer是第三方可以自己實現的一個模塊,還有個核心模塊叫做reconsiler,reconsiler的一大功能就是大家熟知的diff,他會計算出應該更新哪些頁面節點,然後將需要更新的節點虛擬DOM傳遞給renderer,renderer負責將這些節點渲染到頁面上。但是這個流程有個問題,雖然React的diff算法是經過優化的,但是他卻是同步的,renderer負責操作DOM的appendChild等API也是同步的,也就是說如果有大量節點需要更新,JS線程的運行時間可能會比較長,在這段時間瀏覽器是不會響應其他事件的,因為JS線程和GUI線程是互斥的,JS運行時頁面就不會響應,這個時間太長了,用戶就可能看到卡頓,特別是動畫的卡頓會很明顯。在React的官方演講中有個例子,可以很明顯的看到這種同步計算造成的卡頓:
而Fiber就是用來解決這個問題的,Fiber可以將長時間的同步任務拆分成多個小任務,從而讓瀏覽器能夠抽身去響應其他事件,等他空了再回來繼續計算,這樣整個計算流程就顯得平滑很多。下面是使用Fiber后的效果:
上面我們自己實現的render方法直接遞歸遍歷了整個vDom樹,如果我們在中途某一步停下來,下次再調用時其實並不知道上次在哪裡停下來的,不知道從哪裡開始,即使你將上次的結束節點記下來了,你也不知道下一個該執行哪個,所以vDom的樹形結構並不滿足中途暫停,下次繼續的需求,需要改造數據結構。另一個需要解決的問題是,拆分下來的小任務什麼時候執行?我們的目的是讓用戶有更流暢的體驗,所以我們最好不要阻塞高優先級的任務,比如用戶輸入,動畫之類,等他們執行完了我們再計算。那我怎麼知道現在有沒有高優先級任務,瀏覽器是不是空閑呢?總結下來,Fiber要想達到目的,需要解決兩個問題:
- 新的任務調度,有高優先級任務的時候將瀏覽器讓出來,等瀏覽器空了再繼續執行
- 新的數據結構,可以隨時中斷,下次進來可以接着執行
requestIdleCallback是一個實驗中的新API,這個API調用方式如下:
// 開啟調用
var handle = window.requestIdleCallback(callback[, options])
// 結束調用
Window.cancelIdleCallback(handle)
requestIdleCallback接收一個回調,這個回調會在瀏覽器空閑時調用,每次調用會傳入一個IdleDeadline,可以拿到當前還空餘多久,options可以傳入參數最多等多久,等到了時間瀏覽器還不空就強制執行了。使用這個API可以解決任務調度的問題,讓瀏覽器在空閑時才計算diff並渲染。更多關於requestIdleCallback的使用可以查看MDN的文檔。但是這個API還在實驗中,兼容性不好,所以React官方自己實現了一套。本文會繼續使用requestIdleCallback來進行任務調度,我們進行任務調度的思想是將任務拆分成多個小任務,requestIdleCallback裏面不斷的把小任務拿出來執行,當所有任務都執行完或者超時了就結束本次執行,同時要註冊下次執行,代碼架子就是這樣:
function workLoop(deadline) {
while(nextUnitOfWork && deadline.timeRemaining() > 1) {
// 這個while循環會在任務執行完或者時間到了的時候結束
nextUnitOfWork = performUnitOfWork(nextUnitOfWork);
}
// 如果任務還沒完,但是時間到了,我們需要繼續註冊requestIdleCallback
requestIdleCallback(workLoop);
}
// performUnitOfWork用來執行任務,參數是我們的當前fiber任務,返回值是下一個任務
function performUnitOfWork(fiber) {
}
requestIdleCallback(workLoop);
上述workLoop對應React源碼看這裏。
上面我們的performUnitOfWork並沒有實現,但是從上面的結構可以看出來,他接收的參數是一個小任務,同時通過這個小任務還可以找到他的下一個小任務,Fiber構建的就是這樣一個數據結構。Fiber之前的數據結構是一棵樹,父節點的children指向了子節點,但是只有這一個指針是不能實現中斷繼續的。比如我現在有一個父節點A,A有三個子節點B,C,D,當我遍歷到C的時候中斷了,重新開始的時候,其實我是不知道C下面該執行哪個的,因為只知道C,並沒有指針指向他的父節點,也沒有指針指向他的兄弟。Fiber就是改造了這樣一個結構,加上了指向父節點和兄弟節點的指針:
上面的圖片還是來自於官方的演講,可以看到和之前父節點指向所有子節點不同,這裡有三個指針:
- child: 父節點指向第一個子元素的指針。
- sibling:從第一個子元素往後,指向下一個兄弟元素。
- return:所有子元素都有的指向父元素的指針。
有了這幾個指針后,我們可以在任意一個元素中斷遍歷並恢復,比如在上圖List處中斷了,恢復的時候可以通過child找到他的子元素,也可以通過return找到他的父元素,如果他還有兄弟節點也可以用sibling找到。Fiber這個結構外形看着還是棵樹,但是沒有了指向所有子元素的指針,父節點只指向第一個子節點,然後子節點有指向其他子節點的指針,這其實是個鏈表。
現在我們可以自己來實現一下Fiber了,我們需要將之前的vDom結構轉換為Fiber的數據結構,同時需要能夠通過其中任意一個節點返回下一個節點,其實就是遍歷這個鏈表。遍歷的時候從根節點出發,先找子元素,如果子元素存在,直接返回,如果沒有子元素了就找兄弟元素,找完所有的兄弟元素后再返回父元素,然後再找這個父元素的兄弟元素。整個遍歷過程其實是個深度優先遍歷,從上到下,然後最後一行開始從左到右遍歷。比如下圖從div1開始遍歷的話,遍歷的順序就應該是div1 -> div2 -> h1 -> a -> div2 -> p -> div1。可以看到這個序列中,當我們return父節點時,這些父節點會被第二次遍歷,所以我們寫代碼時,return的父節點不會作為下一個任務返回,只有sibling和child才會作為下一個任務返回。
// performUnitOfWork用來執行任務,參數是我們的當前fiber任務,返回值是下一個任務
function performUnitOfWork(fiber) {
// 根節點的dom就是container,如果沒有這個屬性,說明當前fiber不是根節點
if(!fiber.dom) {
fiber.dom = createDom(fiber); // 創建一個DOM掛載上去
}
// 如果有父節點,將當前節點掛載到父節點上
if(fiber.return) {
fiber.return.dom.appendChild(fiber.dom);
}
// 將我們前面的vDom結構轉換為fiber結構
const elements = fiber.children;
let prevSibling = null;
if(elements && elements.length) {
for(let i = 0; i < elements.length; i++) {
const element = elements[i];
const newFiber = {
type: element.type,
props: element.props,
return: fiber,
dom: null
}
// 父級的child指向第一個子元素
if(i === 0) {
fiber.child = newFiber;
} else {
// 每個子元素擁有指向下一個子元素的指針
prevSibling.sibling = newFiber;
}
prevSibling = newFiber;
}
}
// 這個函數的返回值是下一個任務,這其實是一個深度優先遍歷
// 先找子元素,沒有子元素了就找兄弟元素
// 兄弟元素也沒有了就返回父元素
// 然後再找這個父元素的兄弟元素
// 最後到根節點結束
// 這個遍歷的順序其實就是從上到下,從左到右
if(fiber.child) {
return fiber.child;
}
let nextFiber = fiber;
while(nextFiber) {
if(nextFiber.sibling) {
return nextFiber.sibling;
}
nextFiber = nextFiber.return;
}
}
React源碼中的performUnitOfWork看這裏,當然比我們這個複雜很多。
上面我們的performUnitOfWork一邊構建Fiber結構一邊操作DOMappendChild,這樣如果某次更新好幾個節點,操作了第一個節點之後就中斷了,那我們可能只看到第一個節點渲染到了頁面,後續幾個節點等瀏覽器空了才陸續渲染。為了避免這種情況,我們應該將DOM操作都搜集起來,最後統一執行,這就是commit。為了能夠記錄位置,我們還需要一個全局變量workInProgressRoot來記錄根節點,然後在workLoop檢測如果任務執行完了,就commit:
function workLoop(deadline) {
while(nextUnitOfWork && deadline.timeRemaining() > 1) {
// 這個while循環會在任務執行完或者時間到了的時候結束
nextUnitOfWork = performUnitOfWork(nextUnitOfWork);
}
// 任務做完后統一渲染
if(!nextUnitOfWork && workInProgressRoot) {
commitRoot();
}
// 如果任務還沒完,但是時間到了,我們需要繼續註冊requestIdleCallback
requestIdleCallback(workLoop);
}
因為我們是在Fiber樹完全構建后再執行的commit,而且有一個變量workInProgressRoot指向了Fiber的根節點,所以我們可以直接把workInProgressRoot拿過來遞歸渲染就行了:
// 統一操作DOM
function commitRoot() {
commitRootImpl(workInProgressRoot.child); // 開啟遞歸
workInProgressRoot = null; // 操作完后將workInProgressRoot重置
}
function commitRootImpl(fiber) {
if(!fiber) {
return;
}
const parentDom = fiber.return.dom;
parentDom.appendChild(fiber.dom);
// 遞歸操作子元素和兄弟元素
commitRootImpl(fiber.child);
commitRootImpl(fiber.sibling);
}
reconcile其實就是虛擬DOM樹的diff操作,需要刪除不需要的節點,更新修改過的節點,添加新的節點。為了在中斷後能回到工作位置,我們還需要一個變量currentRoot,然後在fiber節點裏面添加一個屬性alternate,這個屬性指向上一次運行的根節點,也就是currentRoot。currentRoot會在第一次render后的commit階段賦值,也就是每次計算完后都會把當次狀態記錄在alternate上,後面更新了就可以把alternate拿出來跟新的狀態做diff。然後performUnitOfWork裏面需要添加調和子元素的代碼,可以新增一個函數reconcileChildren。這個函數裏面不能簡單的創建新節點了,而是要將老節點跟新節點拿來對比,對比邏輯如下:
注意刪除老節點的操作是直接將oldFiber加上一個刪除標記就行,同時用一個全局變量deletions記錄所有需要刪除的節點:
// 對比oldFiber和當前element
const sameType = oldFiber && element && oldFiber.type === element.type; //檢測類型是不是一樣
// 先比較元素類型
if(sameType) {
// 如果類型一樣,復用節點,更新props
newFiber = {
type: oldFiber.type,
props: element.props,
dom: oldFiber.dom,
return: workInProgressFiber,
alternate: oldFiber, // 記錄下上次狀態
effectTag: 'UPDATE' // 添加一個操作標記
}
} else if(!sameType && element) {
// 如果類型不一樣,有新的節點,創建新節點替換老節點
newFiber = {
type: element.type,
props: element.props,
dom: null, // 構建fiber時沒有dom,下次perform這個節點是才創建dom
return: workInProgressFiber,
alternate: null, // 新增的沒有老狀態
effectTag: 'REPLACEMENT' // 添加一個操作標記
}
} else if(!sameType && oldFiber) {
// 如果類型不一樣,沒有新節點,有老節點,刪除老節點
oldFiber.effectTag = 'DELETION'; // 添加刪除標記
deletions.push(oldFiber); // 一個數組收集所有需要刪除的節點
}
然後就是在commit階段處理真正的DOM操作,具體的操作是根據我們的effectTag來判斷的:
function commitRootImpl(fiber) {
if(!fiber) {
return;
}
const parentDom = fiber.return.dom;
if(fiber.effectTag === 'REPLACEMENT' && fiber.dom) {
parentDom.appendChild(fiber.dom);
} else if(fiber.effectTag === 'DELETION') {
parentDom.removeChild(fiber.dom);
} else if(fiber.effectTag === 'UPDATE' && fiber.dom) {
// 更新DOM屬性
updateDom(fiber.dom, fiber.alternate.props, fiber.props);
}
// 遞歸操作子元素和兄弟元素
commitRootImpl(fiber.child);
commitRootImpl(fiber.sibling);
}
替換和刪除的DOM操作都比較簡單,更新屬性的會稍微麻煩點,需要再寫一個輔助函數updateDom來實現:
// 更新DOM的操作
function updateDom(dom, prevProps, nextProps) {
// 1. 過濾children屬性
// 2. 老的存在,新的沒了,取消
// 3. 新的存在,老的沒有,新增
Object.keys(prevProps)
.filter(name => name !== 'children')
.filter(name => !(name in nextProps))
.forEach(name => {
if(name.indexOf('on') === 0) {
dom.removeEventListener(name.substr(2).toLowerCase(), prevProps[name], false);
} else {
dom[name] = '';
}
});
Object.keys(nextProps)
.filter(name => name !== 'children')
.forEach(name => {
if(name.indexOf('on') === 0) {
dom.addEventListener(name.substr(2).toLowerCase(), nextProps[name], false);
} else {
dom[name] = nextProps[name];
}
});
}
updateDom的代碼寫的比較簡單,事件只處理了簡單的on開頭的,兼容性也有問題,prevProps和nextProps可能會遍歷到相同的屬性,有重複賦值,但是總體原理還是沒錯的。要想把這個處理寫全,代碼量還是不少的。
函數組件是React裏面很常見的一種組件,我們前面的React架構其實已經寫好了,我們這裏來支持下函數組件。我們之前的fiber節點上的type都是DOM節點的類型,比如h1什麼的,但是函數組件的節點type其實就是一個函數了,我們需要對這種節點進行單獨處理。
首先需要在更新的時候檢測當前節點是不是函數組件,如果是,children的處理邏輯會稍微不一樣:
// performUnitOfWork裏面
// 檢測函數組件
function performUnitOfWork(fiber) {
const isFunctionComponent = fiber.type instanceof Function;
if(isFunctionComponent) {
updateFunctionComponent(fiber);
} else {
updateHostComponent(fiber);
}
// ...下面省略n行代碼...
}
function updateFunctionComponent(fiber) {
// 函數組件的type就是個函數,直接拿來執行可以獲得DOM元素
const children = [fiber.type(fiber.props)];
reconcileChildren(fiber, children);
}
// updateHostComponent就是之前的操作,只是單獨抽取了一個方法
function updateHostComponent(fiber) {
if(!fiber.dom) {
fiber.dom = createDom(fiber); // 創建一個DOM掛載上去
}
// 將我們前面的vDom結構轉換為fiber結構
const elements = fiber.props.children;
// 調和子元素
reconcileChildren(fiber, elements);
}
然後在我們提交DOM操作的時候因為函數組件沒有DOM元素,所以需要注意兩點:
我們來修改下commitRootImpl:
function commitRootImpl() {
// const parentDom = fiber.return.dom;
// 向上查找真正的DOM
let parentFiber = fiber.return;
while(!parentFiber.dom) {
parentFiber = parentFiber.return;
}
const parentDom = parentFiber.dom;
// ...這裏省略n行代碼...
if{fiber.effectTag === 'DELETION'} {
commitDeletion(fiber, parentDom);
}
}
function commitDeletion(fiber, domParent) {
if(fiber.dom) {
// dom存在,是普通節點
domParent.removeChild(fiber.dom);
} else {
// dom不存在,是函數組件,向下遞歸查找真實DOM
commitDeletion(fiber.child, domParent);
}
}
現在我們可以傳入函數組件了:
import React from './myReact';
const ReactDOM = React;
function App(props) {
return (
<div>
<h1 id="title">{props.title}</h1>
<a href="xxx">Jump</a>
<section>
<p>
Article
</p>
</section>
</div>
);
}
ReactDOM.render(
<App title="Fiber Demo"/>,
document.getElementById('root')
);
useState是React Hooks裏面的一個API,相當於之前Class Component裏面的state,用來管理組件內部狀態,現在我們已經有一個簡化版的React了,我們也可以嘗試下來實現這個API。
我們還是從用法入手來實現最簡單的功能,我們一般使用useState是這樣的:
function App(props) {
const [count, setCount] = React.useState(1);
const onClickHandler = () => {
setCount(count + 1);
}
return (
<div>
<h1>Count: {count}</h1>
<button onClick={onClickHandler}>Count+1</button>
</div>
);
}
ReactDOM.render(
<App title="Fiber Demo"/>,
document.getElementById('root')
);
上述代碼可以看出,我們的useState接收一個初始值,返回一個數組,裏面有這個state的當前值和改變state的方法,需要注意的是App作為一個函數組件,每次render的時候都會運行,也就是說裏面的局部變量每次render的時候都會重置,那我們的state就不能作為一個局部變量,而是應該作為一個全部變量存儲:
let state = null;
function useState(init) {
state = state === null ? init : state;
// 修改state的方法
const setState = value => {
state = value;
// 只要修改了state,我們就需要重新處理節點
workInProgressRoot = {
dom: currentRoot.dom,
props: currentRoot.props,
alternate: currentRoot
}
// 修改nextUnitOfWork指向workInProgressRoot,這樣下次就會處理這個節點了
nextUnitOfWork = workInProgressRoot;
deletions = [];
}
return [state, setState]
}
這樣其實我們就可以使用了:
上面的代碼只有一個state變量,如果我們有多個useState怎麼辦呢?為了能支持多個useState,我們的state就不能是一個簡單的值了,我們可以考慮把他改成一個數組,多個useState按照調用順序放進這個數組裡面,訪問的時候通過下標來訪問:
let state = [];
let hookIndex = 0;
function useState(init) {
const currentIndex = hookIndex;
state[currentIndex] = state[currentIndex] === undefined ? init : state[currentIndex];
// 修改state的方法
const setState = value => {
state[currentIndex] = value;
// 只要修改了state,我們就需要重新處理這個節點
workInProgressRoot = {
dom: currentRoot.dom,
props: currentRoot.props,
alternate: currentRoot
}
// 修改nextUnitOfWork指向workInProgressRoot,這樣下次就會處理這個節點了
nextUnitOfWork = workInProgressRoot;
deletions = [];
}
hookIndex++;
return [state[currentIndex], setState]
}
來看看多個useState的效果:
上面的代碼雖然我們支持了多個useState,但是仍然只有一套全局變量,如果有多個函數組件,每個組件都來操作這個全局變量,那相互之間不就是污染了數據了嗎?所以我們數據還不能都存在全局變量上面,而是應該存在每個fiber節點上,處理這個節點的時候再將狀態放到全局變量用來通訊:
// 申明兩個全局變量,用來處理useState
// wipFiber是當前的函數組件fiber節點
// hookIndex是當前函數組件內部useState狀態計數
let wipFiber = null;
let hookIndex = null;
因為useState只在函數組件裏面可以用,所以我們之前的updateFunctionComponent裏面需要初始化處理useState變量:
function updateFunctionComponent(fiber) {
// 支持useState,初始化變量
wipFiber = fiber;
hookIndex = 0;
wipFiber.hooks = []; // hooks用來存儲具體的state序列
// ......下面代碼省略......
}
因為hooks隊列放到fiber節點上去了,所以我們在useState取之前的值時需要從fiber.alternate上取,完整代碼如下:
function useState(init) {
// 取出上次的Hook
const oldHook = wipFiber.alternate && wipFiber.alternate.hooks && wipFiber.alternate.hooks[hookIndex];
// hook數據結構
const hook = {
state: oldHook ? oldHook.state : init // state是每個具體的值
}
// 將所有useState調用按照順序存到fiber節點上
wipFiber.hooks.push(hook);
hookIndex++;
// 修改state的方法
const setState = value => {
hook.state = value;
// 只要修改了state,我們就需要重新處理這個節點
workInProgressRoot = {
dom: currentRoot.dom,
props: currentRoot.props,
alternate: currentRoot
}
// 修改nextUnitOfWork指向workInProgressRoot,這樣下次requestIdleCallback就會處理這個節點了
nextUnitOfWork = workInProgressRoot;
deletions = [];
}
return [hook.state, setState]
}
上面代碼可以看出我們在將useState和存儲的state進行匹配的時候是用的useState的調用順序匹配state的下標,如果這個下標匹配不上了,state就錯了,所以React裏面不能出現這樣的代碼:
if (something) {
const [state, setState] = useState(1);
}
上述代碼不能保證每次something都滿足,可能導致useState這次render執行了,下次又沒執行,這樣新老節點的下標就匹配不上了,對於這種代碼,React會直接報錯:
這個功能純粹是娛樂性功能,通過前面實現的Hooks來模擬實現Class組件,這個並不是React官方的實現方式哈~我們可以寫一個方法將Class組件轉化為前面的函數組件:
function transfer(Component) {
return function(props) {
const component = new Component(props);
let [state, setState] = useState(component.state);
component.props = props;
component.state = state;
component.setState = setState;
return component.render();
}
}
然後就可以寫Class了,這個Class長得很像我們在React裏面寫的Class,有state,setState和render:
import React from './myReact';
class Count4 {
constructor(props) {
this.props = props;
this.state = {
count: 1
}
}
onClickHandler = () => {
this.setState({
count: this.state.count + 1
})
}
render() {
return (
<div>
<h3>Class component Count: {this.state.count}</h3>
<button onClick={this.onClickHandler}>Count+1</button>
</div>
);
}
}
// export的時候用transfer包裝下
export default React.transfer(Count4);
然後使用的時候直接:
<div>
<Count4></Count4>
</div>
當然你也可以在React裏面建一個空的class Component,讓Count4繼承他,這樣就更像了。
好了,到這裏我們代碼就寫完了,完整代碼可以看我GitHub。
React.createElement。React.createElement返回的其實就是虛擬DOM結構。ReactDOM.render方法是將虛擬DOM渲染到頁面的。父 -> 第一個子,子 -> 兄,子 -> 父這幾個指針,有了這幾個指針,可以從任意一個Fiber節點找到其他節點。父 -> 子 -> 兄 -> 父,也就是從上往下,從左往右。commit)必須是同步的。因為異步的commit可能讓用戶看到節點一個一個接連出現,體驗不好。type是個函數,直接將type拿來運行就可以得到虛擬DOM。useState是在Fiber節點上添加了一個數組,數組裡面的每個值對應了一個useState,useState調用順序必須和這個數組下標匹配,不然會報錯。A Cartoon Intro to Fiber
妙味課堂大聖老師:手寫react的fiber和hooks架構
React Fiber
這可能是最通俗的 React Fiber(時間分片) 打開方式
淺析 React Fiber
React Fiber架構
文章的最後,感謝你花費寶貴的時間閱讀本文,如果本文給了你一點點幫助或者啟發,請不要吝嗇你的贊和GitHub小星星,你的支持是作者持續創作的動力。
作者博文GitHub項目地址: https://github.com/dennis-jiang/Front-End-Knowledges
作者掘金文章匯總:https://juejin.im/post/5e3ffc85518825494e2772fd
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※教你寫出一流的銷售文案?
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※回頭車貨運收費標準
※別再煩惱如何寫文案,掌握八大原則!
※超省錢租車方案
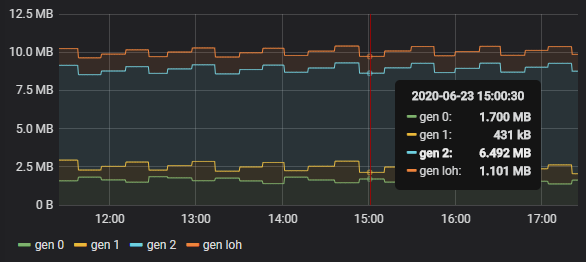
.NET 中GC管理你服務的內存分配和釋放,GC是運行公共語言運行時(CLR Common Language Runtime)中,GC可以幫助開發人員有效的分配內存和和釋放內存,大多數情況下是不需要去擔心的,但是有時候服務總是是出現莫名的問題,所以還是有必要了解一下GC的基礎知識的。這裏就不介紹內存方面的知識了。
GC將對象分為大對象和小對象,如果對象的大小大於或者等於85000byte將被視為大對象,大對象會被分配到到(LOH) Large Object Heap中去。
GC有一個代數的概念Generation,分為三代
Generation 0: 0代,這裏面都是生命周期很短的對象,比如臨時變量,當你new一個對象的時候該對象都會在Generation 0中,這裏的對象將很快的被GC回收,但是當你new的是一個大對象的時候它會直接進去大對象堆(LOH)
Generation 1: 1代,這一代包含的也基本是生命周期很短的對象。它是短期對象和長期對象之間的緩衝區。
Generation 2: 2代,這一代包含的都是生命周期長的對象,它們都是從1代和2代中選拔出來的,LOH屬於2代。
當分配的對象使用的內存超出了GC的閾值時回收就會開始。閾值是隨着服務的運行GC自己調整的。或者直接調用GC.Collect方法也可以開始回收。
回收開始時GC會開始循環遍歷Generation 0中的所有對象並標記所有對象是活動對象還是非活動對象,標記完成後會更新活動對象的引用。最後會回收非活動對象佔用的內存,並把活動對象壓縮后移動到Generation 1中,Generation 1中的或對象在移動到Generation 2是默認不會被壓縮的,因為複製大的對象會導致性能的下降。可以通過GCSettings.LargeObjectHeapCompactionMode來配置壓縮LOH。
GC 回收有兩種類型,WorkStation GC(工作站)和Server GC(服務器),.Net Core服務默認情況下時使用WorkStation GC工作站模式來回收。
Server GC會擁有更大的內存,Server GC會為每個處理器創建一個用於執行垃圾回收的堆和專用線程,每個堆都擁有一個小對象堆和大對象堆,並且所有的堆都可以訪問。 不同堆上的對象可以相互引用。因為多個垃圾回收線程一起工作,所以對於相同大小的堆Server GC垃圾回收比WorkStation GC垃圾回收更快一些。但是Server GC回收會佔用大量資源,這種模式的特點是初始分配的內存較大,並且盡可能不回收內存,進行回收用時會很耗時,並進行內存碎片整理工作。
Workstation GC的內存相對於Server GC就很小啦,且它的回收線程就是服務的線程且有較高的優先級,因為必須與其他線程競爭 CPU 時間來進行回收。
不同模式下的內存分配
GC有三種回收模式
Non-Concurrent GC 非并行回收模式:在非并行模式下,回收時候會掛起所有其他的線程影響服務的性能。
Concurrent GC 并行回收模式: 并行會後可以解決非并行回收引起的線程掛起,讓其他線程和回收線程一起運行,使服務可以更快的響應,并行回收只會發生在Generation 2中,Generation 0/1始終都是非併發的,因為他們都是小對象回收的速度很快。在并行回收的時候我們依舊可以分配對象到Generation 0/1中。
Background GC 後台回收模式:Background GC 是 Concurrent GC的增強版本。 區別在Background GC回收Generation 2的時允許了Generation 0/1 進行清理。在WorkStation GC下會使用一個專用的後台垃圾回收線程,而Server GC下會使用多個線程來進行回收。且Server GC下回收線程不會超時。
非并行回收:
并行回收
WorkStation GC 後台回收
Server GC 後台回收
推薦使用runtimeconfig.json文件和環境變量COMPlus_gcServer來配置。
COMPlus_gcServer 0 = WorkStation GC
COMPlus_gcServer 1 = Server GC
{
"runtimeOptions": {
"configProperties": {
"System.GC.Server": true
//true - Server GC false - WorkStation GC
}
}
}
推薦使用runtimeconfig.json文件和環境變量COMPlus_gcConcurrent來配置。
COMPlus_gcConcurrent 0 =Non-Concurrent GC
COMPlus_gcConcurrent 1 =Background GC
{
"runtimeOptions": {
"configProperties": {
"System.GC.Concurrent": true
//true- Background GC false -Non-Concurrent GC
}
}
}
在一些特殊的情況下強制回收是可以提高服務的性能的,可以向GC.Collect()提供GCCollectionMode枚舉值觸發強制回收。
GC來判斷時間是否是回收對象的最佳時間,如GC判定回收效率不高因此回收不合理的情況下將返回不回收對象。 GC.Collect( (int) GCCollectionMode.Forced);
在我們的服務在檢索數據或者處理邏輯的時候可能會發生垃圾回收,從而妨礙性能,可以通過System.Runtime.GCLatencyMode來配置延遲回收
GCLatencyMode.LowLatency:禁止Generation 2回收,只回收Generation 0/1,這個只能在短時間內使用,如果長時間使用內存處於壓力下GC還是會觸發回收,這個配置只對WorkStation GC可用。
GCLatencyMode.SustainedLowLatency :禁止Generation 2的 Foreground GC (前台回收),只回收Generation 0/1和Generation 2後台回收。WorkStation GC和Server GC都可以使用,且可以長時間使用,但是如果禁用Background GC,將無法使用。
GC.Collect( (int) GCLatencyMode.SustainedLowLatency);
從ASP.NET Core 3.0 preview 特性,了解CLR的Garbage Collection
微軟文檔
參考了一些大佬和官方的文檔簡單的去了解了一下GC的工作原理,方便在開發中有效區分配使用內存資源,文中如有錯誤大佬們可以在評論區指出。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※超省錢租車方案
※別再煩惱如何寫文案,掌握八大原則!
※回頭車貨運收費標準
※教你寫出一流的銷售文案?
摘錄自2019年9月28日聯合報報導
繼菲律賓及南韓之後,位於東南亞地區的東帝汶民主共和國也已經向世界動物衛生組織(OIE)通報發生非洲豬瘟疫情,亞洲地區總計已有十個國家成為非洲豬瘟疫區。
從去年中國大陸爆發非洲豬瘟疫情之後,亞洲地區國家相繼淪陷,農委會主委陳吉仲今天(28日)透過臉書貼文指出,位於東南亞的東帝汶民主共和國已經向世界動物衛生組織通報爆發非洲豬瘟,首次就通報了100例,顯見疫情已經非常嚴重。
陳吉仲表示,東帝汶約有4萬中國人活動,初步判斷是病毒引入的來源,雖然東帝汶與台灣並沒有直航班機,但台灣為超前部署防疫,已經在9月5日時規定東南亞全境所有直航班機都比照疫區標準,旅客行李必須100%檢疫。
根據防檢局官網,目前包含中國、蒙古、越南、柬埔寨、北韓、寮國、緬甸、菲律賓、南韓及東帝汶都有非洲豬瘟疫情,亞洲國家數量已達十個。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※教你寫出一流的銷售文案?
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※回頭車貨運收費標準
※別再煩惱如何寫文案,掌握八大原則!
※超省錢租車方案
6月20日上午消息,知情人士透露,奧迪已經繪製了一份藍圖,計劃推出更多高性能電動汽車,以便在該市場快速騰飛時能幫助其對抗德國競爭對手和美國特斯拉。 奧迪計劃推出首款純電動版R8跑車,並將於2015年在歐洲上市。這款汽車的續航里程達到450公里,接近特斯拉Model S的502公里。與此同時,奧迪還擴大了電動汽車項目的發展計劃,已經將多款高性能電動轎車和SUV的發展計劃提上日程,且其今後的電動汽車都將實現約400公里的續航里程。 奧迪母公司大眾汽車拒絕對此置評,奧迪也尚未作出回應。該公司自2009年以來已經展示了多款混合動力和純電動概念車,但最新藍圖表明,在突破了續航里程的局限後,該公司推出量產車的概率將增加。據透露,其中一個計劃是推出電動版Q8 SUV,以對抗即將發佈的特斯拉Model X。 德國三大豪華汽車製造商都在推進電動汽車業務。寶馬推出了i系列電動汽車,其中包括34,950歐元(約合47,400美元)的城市汽車。奔馳也於今年4月開始生產B級電動汽車。而特斯拉高管已經與寶馬展開了溝通,希望共同推廣電動汽車。
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※幫你省時又省力,新北清潔一流服務好口碑
※回頭車貨運收費標準