CS-LogN思維導圖:記錄CS基礎 面試題
開源地址:https://github.com/FISHers6/CS-LogN
JUC
分類
線程管理
-
線程池相關類
- Executor、Executors、ExecutorService
- 常用的線程池:FixedThreadPool、CachedThreadPool、ScheduledThreadPool、SingleThreadExecutor
-
能獲取子線程的運行結果
- Callable、Future、FutureTask
併發流程管理
- CountDwonLatch、CyclicBarrier、Semaphore、Condition
實現線程安全
-
互斥同步(鎖)
- Synchronzied、及工具類Vector、Collections
- Lock接口的相關類:ReentrantLock、讀寫鎖
-
非互斥同(原子類)
- 原子基本類型、引用類型、原子升級、累加器
-
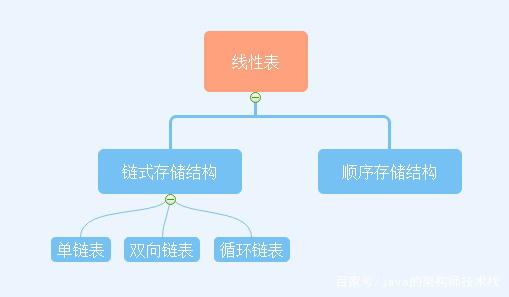
併發容器
- ConcurrentHashMap、CopyOnWriteArrayList、BlockingQueue
-
無同步與不可變方案
- final關鍵字、ThreadLocal棧封閉
線程池
使用線程池的作用好處
-
降低資源消耗
- 重複利用已創建的線程降低線程創建和銷毀造成的消耗
-
提高響應速度
- 任務到達,可以不需要等到線程創建就能立即執行
-
提高線程的可管理性
- 使用線程池可以進行統一的分配,調優和監控
線程池的參數
-
corePoolSize、maximumPoolSize、keepAliveTime、workQueue、threadFactory、handler
-
圖示
常用線程池的創建與規則
-
線程添加規則
-
1.如果線程數量小於corePoolSize,即使工作線程處於空閑狀態,也會創建一個新線程來運行新任務,創建方法是使用threadFactory
-
2.如果線程數量大於corePoolSize但小於maximumPoolSize,則將任務放入隊列
-
3.如果workQueue隊列已滿,並且線程數量小於maxPoolSize,則開闢一個非核心新線程來運行任務
-
4.如果隊列已滿,並且線程數大於或等於maxPoolSize,則拒絕該任務,執行handler
-
圖示(分別與3個參數比較)
-
-
常用線程池
-
newFixedThreadPool
- 創建固定大小的線程池,使用無界隊列會發生OOM
-
newSingleThreadExecutor
- 創建一個單線程的線程池,線程數為1
-
newCachedThreadPool
- 創建一個可緩存的線程池,60s會回收部分空閑的線程。採用直接交付的隊列 SynchronousQueue ,隊列容量為0,來一個創建一個線程
-
newScheduledThreadPool
- 創建一個大小無限的線程池。此線程池支持定時以及周期性執行任務的需求
-
-
如何設置初始化線程池的大小?
-
可根據線程池中的線程
處理任務的不同進行分別估計-
CPU 密集型任務
- 大量的運算,無阻塞
通常 CPU 利用率很高
應配置盡可能少的線程數量
設置為 CPU 核數 + 1
- 大量的運算,無阻塞
-
IO 密集型任務
- 這類任務有大量 IO 操作
伴隨着大量線程被阻塞
有利於并行提高CPU利用率
配置更多數量: CPU 核心數 * 2
- 這類任務有大量 IO 操作
-
-
-
使用線程池的注意事項
- 1.避免任務堆積(無界隊列會OOM)、2.避免線程數過多(cachePool直接交付隊列)、3.排查線程泄露
線程池的狀態和常用方法
-
線程池的狀態
- RUNNING(接受並處理任務中)、
SHUTDOWN(不接受新任務但處理排隊任務)、
STOP(不接受新任務 也不處理排隊任務 並中斷正在進行的任務)、
TIDYING、TEMINATED(運行完成)
- RUNNING(接受並處理任務中)、
-
線程池停止
-
shutdown
- 通知有序停止,先前提交的任務務會執行
-
shutdownNow
- 嘗試立即停止,忽略隊列里等待的任務
-
線程池的源碼解析
-
線程池的組成
-
1.線程池管理器
2.工作線程
3.任務隊列:無界、有界、直接交付隊列
4.任務接口Task -
圖示
-
-
Executor家族
-
Executor頂層接口,只有一個execute方法
-
ExecutorService繼承了Executor,增加了一些新的方法,比如shutdown擁有了初步管理線程池的功能方法
-
Executors工具類,來創建,類似Collections
-
圖示
-
-
線程池實現任務復用的原理
-
線程池對線程作了包裝,不需要啟動線程,不需要重複start線程,只是調用已有線程固定數量的線程來跑傳進來的任務run方法
-
添加工作線程
- 4步:1. 獲取線程池狀態、4.判斷是否進入任務隊列 3.根據狀態檢測是否增加工作線程4.執行拒絕handler
-
重複利用線程執行不同的任務
-
面試題
- 為什麼要使用線程池?
- 如何使用線程池?
- 線程池有哪些核心參數?
- 初始化線程池的大小的如何算?
- shutdown 和 shutdownNow 有什麼區別?
ThreadLocal
ThreadLocal的作用好處
- 為每個線程提供存儲自身獨立的局部變量,實現線程間隔離
- 即:達到線程安全,不需要加鎖節省開銷,減少參數傳遞
ThreadLocal的使用場景
- 1.每個線程需要一個獨享的對象,如 線程不安全的工具類,(線程隔離)
- 2.每個線程內需要保存全局變量,如 攔截器中的用戶信息參數,讓不同方法直接使用,避免參數傳遞過多,(局部變量安全,參數傳遞)
ThreadLocal的實現原理
-
每個 Thread 維護着一個 ThreadLocalMap 的引用;ThreadLocalMap 是 ThreadLocal 的內部類,用 Entry 來進行存儲;key就對應一個個ThreadLocal
-
get方法:取出當前線程的ThreadLocalMap,然後調用map.getEntry方法,把ThreadLocal作為key參數傳入,取出對應的value
-
set方法:往 ThreadLocalMap 設置ThreadLocal對應值
initalValue方法:延遲加載,get的時候設置初始化 -
圖示
缺陷注意
-
value內存泄漏
-
原因:ThreadLocal 被 ThreadLocalMap 中的 entry 的 key 弱引用。如果 ThreadLocal 沒有被強引用, 那麼 GC 時 Entry 的 key 就會被回收,但是對應的 value 卻不會回收,就會造成內存泄漏
-
解決方案:每次使用完 ThreadLocal,都調用它的 remove () 方法,清除value數據。
-
源碼圖示
-
面試題
- ThreadLocal 的作用是什麼?
- 講一講ThreadLocal的實現原理(組成結構)
- ThreadLocal有什麼風險?
Callable與Future
Callable
-
引入目的
-
解決Runnable的缺陷
- 1.沒有返回值,因為返回類型為void
- 2.不能拋出異常,因為沒有繼承Execption接口
-
-
是什麼如何使用
- Callable是類似於Runnable的接口,實現Callable接口的類和實現Runnable的類都是可被其它線程執行的任務。
- 實現Call方法,可以有返回值
Future
-
引入目的
- Future的核心思想是:一個方法的計算過程可能非常耗時,一直在原地等待方法返回,顯然不明智。可以把該計算過程放到子線程去執行,並通過Future去控制方法的計算過程,在計算出結果后直接獲取該結果。
-
常用方法
- get方法:獲取結果,在沒有計算出結果前,會進入阻塞態
-
使用場景
- 用法1:線程池的submit方法返回Future對象
- 用法2:用FutureTask來創建Future
-
注意點
- 當for循環批量獲取future的結果時,容易block,get方法調用時應使用timeout限制
- Future和Callable的生命周期不能後退
-
Callable和Future的關係
-
Future相當於一個存儲器,它存儲未來call()任務方法的返回值結果
-
可以用Future.get方法來獲取Callable接口的執行結果,在call()未執行完畢之前沒調用get的線程會被阻塞
-
線程池傳入Callable,submit返回Future,get獲取值
-
-
FutureTask
-
FutureTask是一種包裝器,可以把Callable轉化成Future和Runnable,它同時實現了二者的接口。所以既可以作為Runnable任務被線程執行,又可以作為Future得到Callable的返回值
-
圖示
-
final與不變性
什麼是不變性(Immutable)
- 如果對象在被創建后,狀態就不能被修改,那麼它就是不可變的。
- 具有不變性的對象一定是線程安全的,我們不需要對其採取任何額外的安全措施,也能保證線程安全。
final的作用
- 類防止被繼承、方法防止被重寫、變量防止被修改
- 天生是線程安全的(因為不能修改),而不需要額外的同步開銷
final的3種用法:修飾變量、方法、類
-
final修飾變量
-
被final修飾的變量,意味着值不能被修改。
如果變量是對象,那麼對象的引用不能變,但是對象自身的內容依然可以變化。 -
賦值時機
-
屬性被聲明為final后,該變量則只能被賦值一次。且一旦被賦值,final的變量就不能再被改變,如論如何也不會變。
-
區分為3種
-
final instance variable(類中的final屬性)
- 等號右側、構造函數、初始化代碼塊
-
final static variable(類中的static final屬性)
- 等號右側、靜態初始化代碼塊
-
final local variable(方法中的final變量)
- 使用前複製即可
-
-
為什麼規定時機
- 根據JVM對類和成員變量、靜態成員變量的加載規則來看:如果初始化不賦值,後續賦值,就是從null變成新的賦值,這就違反final不變的原則了!
-
-
-
final修飾方法(構造方法除外)
- 不可被重寫,也就是不能被override,即便是子類有同樣名字的方法,那也不是override,與static類似*
-
final修飾類
- 不可被繼承,例如典型的String類就是final的
棧封閉 實現線程安全
- 在方法里新建的局部便咯,實際上是存儲在每個線程私有的棧空間,線程棧不能被其它線程訪問,所以不會有線程安全問題,如ThreadLocal
面試題
CAS
什麼是CAS
- 我認為V的值應該是A,如果是的話那我就把它改成B,如果不是A(說明被別人修改過了),那我就不修改了,避免多人同時修改導致出錯。
- CAS有三個操作數:內存值V、預期值A、要修改的值B,當且僅當預期值A和內存值V相同時,才將內存值修改為B,否則什麼都不做。最後返回現在的V值。
- 最終執行CPU處理機提供的的原子指令
缺點
-
ABA問題
- 我認為 V的值為A,有其它線程在這期間修改了值為B,但它又修改成了A,那麼CAS只是對比最終結果和預期值,就檢測不出是否修改過
-
CAS+自旋,導致自旋時間過長
-
改進:通過版本號的機制來解決。每次變量更新的時候,版本號加 1,如AtomicStampedReference的compareAndSet ()
應用場景
- 1 樂觀鎖:數據庫、git版本號; 自旋 2 concurrentHashMap:CAS+自旋
3 原子類
CAS底層實現
- 通過Unsafe獲取待修改變量的內存遞增,
比較預期值與結果,調用彙編cmpxchg指令
以AtomicInteger為例,分析在Java中是如何利用CAS實現原子操作的?
- 1.使用Unsafe類拿到value的內存遞增,通過偏移量 直接操作內存數據
- 2.Unsafe的getAndAddInt方法,使用CAS+自旋嘗試修改數據
- CAS的參數通過 預期值 與 實際拿到的值進行比較,相同就修改,不相同就自旋
- Unsafe提供硬件級別的原子操作,最終調用原子彙編指令的cmpxchg指令
鎖
鎖的分類
Lock鎖接口
-
簡介
- Lock鎖是一種工具,用於控制對共享資源的訪問
- 如:ReentrantLock
-
Lock和Synchronized的異同點
-
相同點
- 都能達到線程安全的目的
-
不同點
-
Lock 有比 synchronized 更精確的線程語義和更好的性能;高級功能
-
1 實現原理不同
- Synchronized 是關鍵字,屬於 JVM 層面,底層是通過 monitorenter 和 monitorexit 完成,依賴於 monitor 對象來完成;
- Lock 是 java.util.concurrent.locks.lock 包下的,底層是AQS
-
2 靈活性不同
- Synchronized 代碼完成之後系統自動讓線程釋放鎖;ReentrantLock 需要用戶手動釋放鎖,加鎖解鎖靈活
-
3 等待時是否可以中斷
- Synchronized 不可中斷,除非拋出異常或者正常運行完成;ReentrantLock 可以中斷。一種是通過 tryLock,另一種是 lockInterruptibly () 放代碼塊中,調用 interrupt () 方法進行中斷;
-
-
-
可見性
- happens-before規則約定;Lock與Synchronized一致都可以保證可見性
- 即下一個線程加鎖時可以看到上一個釋放鎖的線程發生的所有操作
樂觀鎖與悲觀鎖
-
悲觀鎖(互斥同步鎖)
-
思想
- 鎖住數據,讓別人無法訪問,確保數據萬無一失
-
實例
- Synchronized、Lock相關類
- 應用實例:select 把庫鎖住,屬於悲觀鎖,更新期間其它人不能修改
-
缺點
- 在阻塞和喚醒性能開銷大(用戶態核心態切換、上下文切換、檢查是否有線程被喚醒)
- 持有鎖的線程被阻塞時無法釋放,有可能造成永久阻塞
-
-
樂觀鎖
-
思想
- 認為自己在操作數據時不會有其它線程干擾,所以不需要鎖住被操作對象
- 在更新數據的時候,去對比修改期間有沒有被其它人改變過,沒改過就正常修改(類似CAS思想)
- 樂觀鎖一般由CAS實現:CAS在一個原子操作內把數據對比且交換,在此期間不能被打斷的
-
實例
- 原子類、併發容器
- 應用實例:數據庫版本號控制、git版本號
-
優缺點對比
- 悲觀鎖一旦切換就不用再考慮切換CPU等操作了,一勞永逸,開銷固定
- 樂觀鎖,會一步步嘗試自旋來獲取鎖,自旋開銷
-
-
對比
可重入鎖與非可重入鎖
-
什麼是可重入
- 拿到鎖的線程又請求這把鎖,允許通過
-
可重入的好處
- 避免死鎖(拿到鎖的線程內部又請求該鎖)
- 提升封裝性,避免一次次加鎖
-
可重入鎖ReentrantLock與非可重入鎖ThreadPoolExecutor的Worker類對比
公平鎖和非公平鎖
-
公平鎖
-
介紹
- 公平鎖是指多個線程按照申請鎖的順序來獲取鎖,線程直接進入隊列中排隊,隊列中的第一個線程才能獲得鎖
-
優點
- 公平鎖的優點是公平執行,等待鎖的線程不會餓死
-
缺點
- 缺點是整體吞吐效率相對非公平鎖要低,等待隊列中除第一個線程以外的所有線程都會阻塞,CPU喚醒阻塞線程的開銷比非公平鎖大
-
-
非公平鎖
-
介紹
- 多個線程加鎖時直接嘗試獲取鎖,獲取不到才會到等待隊列的隊尾等待。但如果此時鎖剛好可用,那麼這個線程可以無需阻塞直接獲取到鎖,所以非公平鎖有可能出現后申請鎖的線程先獲取鎖的場景
-
優點
- 減少喚起線程的開銷,整體的吞吐效率高,因為線程有幾率不阻塞直接獲得鎖,CPU不必喚醒所有線程
-
缺點
- 處於等待隊列中的線程可能會餓死,或者等很久才會獲得鎖
-
-
優缺點對比
-
源碼分析
共享鎖和排他鎖
-
排他鎖
-
介紹
- 排他鎖,獲取鎖后,既能讀又能寫,但是此時其它線程不能獲取這個鎖了,只能由當前線程修改數據獨享鎖,保證了線程安全,synchronized
- 又稱為 獨佔鎖,寫鎖
-
-
共享鎖
-
介紹
- 獲取共享鎖后,其它線程也可以獲取共享鎖完成讀操作,但都不能修改刪除數據
- 又成為 讀鎖
-
-
ReentrantReadWriteLock
-
讀寫鎖的作用
- 共享鎖減少了多個讀都加鎖的開銷,線程也安全
- 在讀的地方使用讀鎖,在寫的地方寫鎖;在沒有寫鎖的情況下,讀操作無阻塞,提高程序效率
-
讀寫鎖的規則
- 要麼可以多讀,要麼只能一寫
- 讀寫鎖只是一把鎖,可以通過兩個方式鎖定:讀鎖定 或 寫鎖定
-
一把鎖兩種方式鎖定
- readLock() 讀鎖
- writeLock() 寫鎖
-
讀線程插隊策略(非公平下)
- 寫鎖可以隨時插隊,參与競爭
- 讀鎖僅在等待隊列頭節點為寫的時候不允許插隊;當隊頭為讀的時候可以去插隊。
-
鎖升級
-
引入場景
- 假如一開始持有寫鎖,但我寫需求完了,後面都是讀的需求了,如果還佔用寫鎖就浪費資源開銷
-
策略
- 只允許降級,不允許升級
-
-
適合場景
- 讀多寫少,提高併發效率
-
自旋鎖和阻塞鎖
-
阻塞鎖
-
思想
- 沒拿到鎖之前,會直接把線程阻塞,直到被喚醒
-
開銷缺陷
- 阻塞或喚醒一個線程需要操作系統切換CPU狀態來完成,恢復現場等需要消耗處理機時間;如果同步代碼塊的內容過於簡單,狀態轉換消耗的時間有可能比用戶代碼執行的時間還要長,得不償失
-
-
自旋鎖
-
思想
- 讓當前搶鎖失敗的線程進行自旋,如果在自旋完成后前面鎖定同步資源的線程已經釋放了鎖,那麼當前線程就可以不必阻塞而是直接獲取同步資源,從而避免切換線程的開銷
-
開銷缺陷
- 自旋佔用時間長,起始開銷低,但消耗CPU資源開銷會線性增長
-
-
源碼分析
-
atomic包下的類基本都是自旋鎖的實現
-
AtomicInteger的實現:自旋鎖實現原理是CAS,Atomic調用Unsafe進行自增add的源碼中的do-while循環就是一個自旋操作,使用CAS如果修改過程中遇到其它線程修改導致沒有秀嘎四成功,就在while里死循環,直至修改成功
-
圖示
-
-
適用場景
- 多核、臨界區短小
可中斷鎖
-
介紹
- 線程B等待線程A釋放鎖時,線程B不想等待了,想處理其它事情,我們可以中斷它
-
使用場景
- synchronized是不可中斷鎖,Lock是可中斷鎖(tryLock(time) 和 lockInterruptibly)響應中斷
鎖優化
-
JDK1.6 后對synchronized鎖的優化
-
JDK1.6 對鎖的實現引入了大量的優化,如偏向鎖、輕量級鎖、自旋鎖、適應性自旋鎖、鎖消除、鎖粗化等技術來減少鎖操作的開銷。
-
偏向鎖
- 無競爭條件下,消除整個同步互斥,連CAS都不操作;即這個鎖會偏向於第一個獲得它的線程
-
輕量級鎖
- 無競爭條件下,通過CAS消除同步互斥,減少傳統的重量級鎖使用操作系統互斥量產生的性能消耗。
-
重量級鎖
- 互斥同步鎖
-
自旋鎖
- 為了減少線程狀態改變帶來的消耗,不停地執行當前線程
-
自適應自旋鎖
- 自旋的時間不固定了,如設置自旋次數
-
鎖消除
- 不可能存在共享數據競爭的鎖進行消除;
-
鎖粗化
- 鎖粗化就是增大鎖的作用域;如解決加鎖操作在循環體內的頻開銷
-
-
寫代碼時的優化
- 縮小同步代碼塊、如不要鎖住方法
- 減少鎖的請求次數, 如一批一批請求
- 參考LongAdder的思想,每個段有自己的計數器,最後才合併
面試題
- 什麼是公平鎖?什麼是非公平鎖?
- 自旋鎖解決什麼問題?自旋鎖的原理是什麼?自旋的缺點?
- 說說 JDK1.6 之後的synchronized 關鍵字底層做了哪些優化,可以詳細介紹一下這些優化嗎?
- 說說 synchronized 和 java.util.concurrent.locks.Lock 的異同?
原子類atomic包
原子類的作用
- 原子類的作用和鎖類似,都是為了保證併發下線程安全
- 粒度更細,變量級別
- 效率更高,除了高度競爭外
原子類的種類
- Atomic*基本類型原子類:AtomicInteger、AtomicLong、AtomicBoolean
- Atomic*Array數組類型原子類:AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray
- Atomic*Reference 引用類型原子類:AtomicReference等
- AtomicIntegerFiledUpdate等升級類型原子類
- Adder累加器、Accumlator累加器
AtomicInteger
-
常用方法
- get、getAndSet、getAndIncrement、compareAndSet(int expect,int update)
-
實現原理
- AtomicInteger 內部使用 CAS 原子語義來處理加減等操作。CAS通過判斷內存某個位置的值是否與預期值相等,如果相等則進行值更新
- CAS 是內部是通過 Unsafe 類實現,而 Unsafe 類的方法都是 native 的,在 JNI 里是藉助於一個 CPU 指令完成的,屬於原子操作。
-
缺點
- 循環開銷大。如果 CAS 失敗,會一直嘗試
- 只能保證單個共享變量的原子操作,對於多個共享變量,CAS 無法保證,引出原子引用類
- 用CAS存在 ABA 問題
Adder累加器
-
引入目的/改進思想
- AtomicLong在每一次加法都要flush和refresh主存,與JMM內存模型有關。工作線程之間不能直接通信,需要通過主內存間接通信
-
設計思想
- Java8引入,高併發下LongAdder比AtomicLong效率高,本質是空間換時間
- 競爭激烈時,LongAdder把不同線程對應到不同的Cell單元上進行修改,降低了衝突的概率,是多段鎖的理念,提高了併發性
- 每個線程都有自己的一個計數器,不存在競爭
- sum源碼分析:最終把每一個Cell的計數器與base主變量相加
面試題
- AtomicInteger 怎麼實現原子操作的?
- AtomicInteger 有哪些缺點?
併發容器
ConcurrentHashMap
-
集合類歷史
- Vector的方法被synchronizd修飾,同步鎖;不允許多個線程同時執行。併發量大的時候性能不好
- Hashtable是線程安全的HashMap,方法也是被synchronized修飾,同步但併發性能差
- Collections工具類,提高的有synchronizedList和synchronizedMap,代碼內使用sync互斥變量加鎖
-
為什麼需要
-
為什麼不用HashMap
- 1.多線程下同時put碰撞導致數據丟失
- 2.多線程下同時put擴容導致數據丟失
- 3.死循環造成的CPU100%
-
為什麼不用Collection.synchronizedMap
- 同步鎖併發性能低
-
-
數據結構與併發策略
-
JDK1.7
- 數組+鏈表,拉鏈法解決衝突
- 採用分段鎖,每個數組結點是一個獨立的ReentrantLock鎖,可以支持同時併發寫
-
JDK1.8
- 數組+鏈表+紅黑樹,拉鏈法和樹化解決衝突
- 採用CAS+synchronized鎖細化
-
1.7到1.8改變後有哪些優點
- 1.數據結構由鏈表變為紅黑樹,樹查詢效率更高
- 2.減少了Hash碰撞,1.7拉鏈法
- 3.保證了併發安全和性能,分段鎖改成CAS+synchronized
- 為什麼超過8要轉為紅黑樹,因為紅黑樹存儲空間是結點的兩倍,經過泊松分佈,8衝突概率低
-
-
注意事項
- 組合操作線程不安全,應使用putIfAbsent提供的原子性操作
CopyOnWriteArrayList
-
引入目的
- Vector和SynchronizedList鎖的粒度太大併發效率低,並且迭代時無法編輯exceptMod!=Count
-
適合場景
- 讀多寫少,如黑名單管理每日更新
-
讀寫規則
- 是對讀寫鎖的升級:讀取完全不用加鎖,讀時寫入也不會阻塞。只有寫入和寫入之間需要同步
-
實現原理
- 創建數據的新副本,實現讀寫分離,修改時整個副本進行一次複製,完成后最後再替換回去;由於讀寫分離,舊容器不變,所以線程安全無需鎖
- 在計算機內存中修改不直接修改主內存,而是修改緩存(cache、對拷貝的副本進行修改),再進行同步(指針指向新數據)。
-
缺點
- 1.數據一致性問題,拷貝不能保證數據實時一致,只能保證數據最終一致性
- 2.內存佔用問題,寫複製機制,寫操作時內存會同時駐紮兩個對象的內存
併發隊列
-
為什麼使用隊列
- 用隊列可以在線程間傳遞數據,緩存數據
- 考慮鎖等線程安全問題的重任轉移到了“隊列”上
-
併發隊列關係圖示
-
BlockingQueue阻塞隊列
-
阻塞隊列是局由自動阻塞功能的隊列,線程安全;take方法移除隊頭,若隊列無數據則阻塞直到有數據;put方法插入元素,如果隊列已滿就無法繼續插入則阻塞直到隊列里有了空閑空間
-
ArrayBlockQueue
- 有界可指定容量、可公平
- Put源碼加鎖,可中斷的上鎖方法。沒滿才可以入隊,否則一直await等待。
-
LinkedBlockingQueue
- 無界容量為MAX_VALUE,內部結構Node
- 使用了兩把鎖take鎖和put鎖互補干擾
-
PriorityBlockingQueue
- 支持優先級,無界隊列
-
SynchronousQueue
- 直接傳遞的隊列,容量0,效率高線程池的CacheExecutorPool使用其作為工作隊列
-
DelayQueue
- 無界隊列,根據延遲時間排序
-
-
非阻塞隊列
-
ConcurrentLinkedQueue
- 使用鏈表作為隊列存儲結構
- 使用Unsafe的CAS非阻塞方法來實現線程安全,無需阻塞,適合對性能要求較高的併發場景
-
-
選擇合適的隊列
-
邊界上看
- ArrayBlockQueue有界;LinkedBlockQueue無界適合容量大容量激增
-
內存上看
- ArrayBlockQueue內部結構是array,從內存存儲上看,連續存儲更加整齊。而LinkedBlockQueue採用鏈表結點,可以非連續存儲。
-
吞吐量上看
- 從性能上看LinkedBlockQueue的put鎖和鎖分開,鎖粒度更細,所以優於ArrayBlockQueue
-
總結併發容器對比
- 分為3類:Concurrent、CopyOnWrite、Blocking*
- Concurrent*的特定是大部分使用CAS併發;而CopyOnWrite通過複製一份元數據寫加鎖實現;Blocking通過ReentLock鎖底層AQS實現
併發流程控制工具類
控制併發流程工具類的作用
-
控制併發流程的工具類,作用是幫助程序員更容易讓線程之間相互配合,來滿足業務邏輯
-
併發工具類圖示
CountDownLatch倒計時門閂
-
作用(事件)
- 一個線程等多個線程、或多個線程等一個線程完成到達,才能繼續執行
-
常用方法
- 構造函數中傳入倒數值、await、countDown
Semaphore信號量
-
作用
- 用來限制管理數量有限的資源的使用情況,相當於一定數量的“許可證”
-
常用方法
- 構造函數中傳入數量、acquire、release
Condition條件對象
-
作用
- 等待條件滿足才放行,否則阻塞;一個鎖可以對應多個條件
-
常用方法
- lock.newCondition、await、signal
CyclicBarrier循環柵欄
-
作用(線程)
- 多個線程互相等待,直到達到同一個同步點(屏障),再繼續一起執行
-
常用方法
- 構造函數中傳入個數、await
AQS
AQS的作用
- AQS是一個用於構建鎖、同步器、協作工具類的框架,有了AQS后,更多的協作工具類都可以很方便的寫出來
AQS的應用場景
-
Exclusive(獨佔)
- ReentrantLock 公平和非公平鎖
-
Share(共享)
- Semaphore/CountDownLatch/CyclicBarrier
AQS原理解析
-
核心三要素
-
1.sate
- 使用一個 int 成員變量來表示同步狀態 state,被volatile修飾,會被併發修改,各方法如getState、setState等使用CAS保證線程安全
- 在ReentrantLock中,表示可重入的次數
- 在Semaphore中,表示剩餘許可證信號的數量
- 在CountDownLatch中,表示還需要倒數的個數
-
2.控制線程搶鎖和配合的FIFO隊列
- 獲取資源線程的排隊工作
-
3.期望協作工具類去實現的“獲取/釋放”等喚醒分配的方法策略
-
-
AQS的用法
- 第一步:寫一個類,想好協作的邏輯,實現獲取/釋放方法
- 第二步:內部寫一個Sync類繼承AbstractQueueSynchronizer
- 第三步:Sync類根據獨佔還是共享重寫tryAcquire/tryRelease或tryAcquireShared和tryReleaseShared等方法,在之前寫的獲取/釋放方法中調用AQS的acquire/release或則Shared方法
AQS應用實例源碼解析
-
AQS在CountDownLatch的應用
-
內部類Sync繼承AQS
-
1.state表示門閂倒數的count數量,對應getCount方法獲取
-
2.釋放方法,countDown方法會讓state減1,直到減為0時就喚醒所有線程。countDown方法調用releaseShared,它調用sync實現的tryReleaseShared,其使用CAS+自旋鎖,來實現安全的計數-1
-
3.阻塞方法,await會調用sync提供的aquireSharedInterruptly方法,當state不等於0時,最終調用LockUpport的park,它利用Unsafe的park,native方法,把線程加入阻塞隊列
-
總結
-
-
AQS在Semphore的應用
-
state表示信號量允許的剩餘許可數量
-
tryAcquire方法,判斷信號量大於0就成功獲取,使用CAS+自旋改變state狀態。如果信號量小於0了,再請求時tryAcquireShared返回負數,調用aquireSharedInterruptly方法就進入阻塞隊列
-
release方法,調用sync實現的releaseShared,會利用AQS去阻塞隊列喚醒一個線程
-
總結
-
-
AQS在ReentrantLock的應用
- state表示已重入的次數,獨佔鎖權保存在AQS的Thread類型的exclusiveOwnerThread變量中
- 釋放鎖: unlock方法調用sync實現的release方法,會調用tryRelease,使用setState而不是CAS來修改重入次數state,當state減到0完全釋放鎖
- 加鎖lock方法:調用sync實現的lock方法。CAS嘗試修改鎖的所有權為當前線程,如果修改失敗就要調用acquire方法再次嘗試獲取,acquire方法調用了AQS的tryAcquire,這個實現在ReentantLock的裏面,獲取失敗加入到阻塞隊列
通過AQS自定義同步器
- 自定義同步器在實現時只需要根據業務邏輯需求,實現共享資源 state 的獲取與釋放方式策略即可
- 至於具體線程等待隊列的維護(如獲取資源失敗入隊 / 喚醒出隊等),AQS 已經在頂層實現好了
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家公司費用,距離,噸數怎麼算?達人教你簡易估價知識!
※教你寫出一流的銷售文案?
※超省錢租車方案
 繼新北市電動機車 E-bike 於 10 月上路後,台北市政府也採用能源局補助業者研發旳氫燃料電池機車,每台配備 2 支金屬儲氫罐,交換費用 30 元,行駛中排水,但二氧化碳排放為 0,續航力定速時可達 86 公里,不過,若在行駛市區時,遇上紅綠燈走走停停,續航力會降為 50 公里。環保局表示,廠商提供試騎的 15 輛氫燃料電池機車將用於環保稽查、工地巡查、土地丈量等業務。 環保局表示,氫燃料電池首創用於機車,金屬容器包覆氫氧化物粉末,相較氣體狀較安全,業者提供的 15 部試騎機車將停於於市府公務停車場,也會提供交換氣體,試用 3 個月後評估成效。 負責研發的亞太燃料電池科技專案經理陳建豪表示,氣燃料電池不須充電,而是利用能源轉換,將氫氣透過觸媒轉換成電能,轉換過程僅會排放水,該款氫燃料電池機車時速最快可達 60 公里。業者說,量產後機車售價約 7 萬元,但免燃料稅。陳建豪表示,全球各國多有氫燃料電池的安全使用規範,但台灣沒有,盼政府能協助立法。 (Source:)
繼新北市電動機車 E-bike 於 10 月上路後,台北市政府也採用能源局補助業者研發旳氫燃料電池機車,每台配備 2 支金屬儲氫罐,交換費用 30 元,行駛中排水,但二氧化碳排放為 0,續航力定速時可達 86 公里,不過,若在行駛市區時,遇上紅綠燈走走停停,續航力會降為 50 公里。環保局表示,廠商提供試騎的 15 輛氫燃料電池機車將用於環保稽查、工地巡查、土地丈量等業務。 環保局表示,氫燃料電池首創用於機車,金屬容器包覆氫氧化物粉末,相較氣體狀較安全,業者提供的 15 部試騎機車將停於於市府公務停車場,也會提供交換氣體,試用 3 個月後評估成效。 負責研發的亞太燃料電池科技專案經理陳建豪表示,氣燃料電池不須充電,而是利用能源轉換,將氫氣透過觸媒轉換成電能,轉換過程僅會排放水,該款氫燃料電池機車時速最快可達 60 公里。業者說,量產後機車售價約 7 萬元,但免燃料稅。陳建豪表示,全球各國多有氫燃料電池的安全使用規範,但台灣沒有,盼政府能協助立法。 (Source:)