環境資訊中心綜合外電;姜唯 編譯;林大利 審校
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家公司費用,距離,噸數怎麼算?達人教你簡易估價知識!
※教你寫出一流的銷售文案?
※超省錢租車方案
摘錄自2020年08月01日中央通訊社法國報導
法國今天(1日)同時發布熱浪及大雷雨橘色警戒,巴黎、里昂等地氣溫飆至40度。極端氣候導致法國缺水危機日益嚴重,多個省分今天下令限水。
氣象局表示,今天是「強烈熱度的高峰」,而熱浪又遇上週末及8月暑假出遊車潮,出現熱度加乘效應。這波熱浪於今日達到高峰,並會持續整個週末。面對熱浪與大雷雨,今天全法國96個省中有32個已經發出橘色警戒,其中13個熱浪警報、19個大雷雨警報。
法國近日接連發生森林大火。27日波爾多北部吉倫特省(Gironde)和巴黎南方盧瓦雷省(Loiret)兩處的惡火燒掉超過500公頃的森林。30日晚間,西南部鄰近大西洋的安格雷鎮(Anglet)的森林也出現熊熊大火,燒毀165公頃森林。所幸幾起事故都沒有傷及人員性命。雖然3起森林大火起火原因仍在調查中,但據信連日高溫及季節乾旱,皆助長火勢。
尤其是聖讓德呂(Saint-Jean-de-Luz)30日下午出現超高溫41.9度,創下當地有史以來最高溫紀錄。
生物多樣性
土地利用
國際新聞
法國
森林大火
乾旱
棲地保育
森林
災害
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計最專業,超強功能平台可客製化
摘錄自2020年08月01日中央通訊社阿拉伯聯合大公國報導
阿拉伯聯合大公國今天(1日)宣布,境內的巴拉卡核能發電廠(Barakah Nuclear Energy Plant)正式啟動運轉,這不僅是阿聯第一座核電廠,也是阿拉伯世界首座。
國際原子能總署(International Atomic Energy Agency)的阿聯代表阿爾卡比(Hamad Alkaabi)在推特發文表示:「阿拉伯聯合大公國巴拉卡核能發電廠的首座核反應爐,已達到初次臨界並成功啟動。」法新社報導,阿聯當局對巴拉卡核電廠4座反應爐的首座反應爐核發許可後,阿聯今年2月開始將燃料棒放入反應爐內,以期未來邁向商轉。
人口約有1000萬人的阿聯蘊藏豐富石油及天然氣,但國內用電需求量相當龐大。位於波斯灣沿岸的巴拉卡核電廠,原本預計在2017年開始供電,但官方聲稱因為安全和管理規定等因素而多次延宕。
能源轉型
國際新聞
阿拉伯聯合大公國
巴拉卡
核能發電廠
核能
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※南投搬家公司費用需注意的眉眉角角,別等搬了再說!
※教你寫出一流的銷售文案?
摘錄自2020年08月02日中央通訊社日本報導
日本觀測史上首度出現「7月零颱風」,沒想到也可能造成珊瑚大規模白化。日本專家指出,颱風不來就無法讓海水溫度下降,沖繩本島周邊有可能出現大範圍的珊瑚白化。
珊瑚適合生存在攝氏18度到28度的海水中,如果水溫維持高溫,對珊瑚生長來說不可或缺的褐蟲藻就會離開,然後造成珊瑚白化。日本氣象廳表示,沖繩周邊海域海面溫度在7月31日為30度。今年7月一個颱風都沒有生成,創下日本1951年開始觀測以來紀錄。颱風一方面雖然會帶來災情,但另一方面也有攪動海水、為夏天升高的水溫降溫的效果。
日本政府環境省石垣自然保護官辦公室7月調查石垣市的名藏灣,已確認部分珊瑚白化。自然保護官大嶽若緒說,期待颱風能適當地攪動海水降低海水溫度。
生物多樣性
物種保育
海洋
氣候變遷
國際新聞
日本
沖繩
珊瑚白化
颱風
海水升溫
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※想知道最厲害的網頁設計公司"嚨底家"!
※別再煩惱如何寫文案,掌握八大原則!
※產品缺大量曝光嗎?你需要的是一流包裝設計!
摘錄自2020年7月30日中央社報導
聯合國今天(30日)發布COVID-19對東南亞的影響報告(Policy Brief: The Impact of COVID-19 on South-East Asia)指出,武漢肺炎疫情加深東南亞的不平等現象,東南亞國家的政府應該把重點放在疫情對社會經濟的影響。疫情對政治、經濟和健康的影響,重擊社會底層人民,使他們失業且更加貧窮。
報告指出,東南亞要從疫情中復甦有四個關鍵領域,包括打擊不平等、消弭數位落差、綠化經濟並保持人權和良好的治理。
報告也進一步強調,在面對疫情時,東南亞國家以及他們的領導人在保障人權以及良好治理上具有重要的角色。領導人們應該多利用以社區為中心的組織、促進包容及團結,並挺身而出反對歧視。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※超省錢租車方案
※教你寫出一流的銷售文案?
※網頁設計最專業,超強功能平台可客製化
※產品缺大量曝光嗎?你需要的是一流包裝設計!
摘錄自2020年8月3日公視報導
有一群日本高中生研發出可以自動分解,而且魚類不小心吃下去,也會吐掉的塑膠袋;預計再過一兩年,就能夠上市使用。
神奈川縣川崎市的「洗足學園高中」,有學生團體突發奇想,決定研發能在大自然中自行分解,卻又不會被魚類跟海龜吞食的塑膠袋,於是用「苯甲地那銨」進行實驗。
在大學跟贊助企業的協助下,學生團隊實驗製作出含有2%到20%「苯甲地那銨」的可自動分解塑膠袋。實驗後發現,只要有「苯甲地那銨」4%含量,就會讓魚類在吃進塑膠時,因為苦味而吐出。
目前這款塑膠袋,以能在海洋分解的材質製造,只要進入海洋,到完全自然分解,只需要1到2年時間。目前學生團隊,還在研究新成分,期盼降低製造費用,以便廣為商家使用。另外也將持續改善,塑膠袋完全分解前,苦味可能已經消失的缺點,進行修正。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※南投搬家公司費用需注意的眉眉角角,別等搬了再說!
※教你寫出一流的銷售文案?
摘錄自2020年8月3日公視報導
美國南加州、洛杉磯東邊櫻桃谷的森林大火,上星期五在聖伯蒂納市附近爆發後持續延燒,四天過去消防員只控制住12%的火勢,在風勢助長下,延燒面積已來到80平方公里,相當於燒掉307座大安森林公園。加州動員超過1300名消防員,從地面跟空中兵分兩路打火,當地至少2600戶住家,將近7800位居民緊急撤離,所幸目前還沒傳出人員傷亡。
由於當地氣候相當炎熱乾燥,最高溫可能達到攝氏41度,預料火勢還將持續擴大,至於起火原因已展開調查,不排除人為刻意縱火。
至於南美洲巴西境內,全球最大的熱帶濕地系統,潘特納爾濕地,今年7月份有將近1700個地點發生大火,創歷史新高,也是去年同期的三倍。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※想知道最厲害的網頁設計公司"嚨底家"!
※別再煩惱如何寫文案,掌握八大原則!
※產品缺大量曝光嗎?你需要的是一流包裝設計!
今天要給大家介紹RocketMQ中的兩個功能,一個是“廣播”,這個功能是比較基礎的,幾乎所有的mq產品都是支持這個功能的;另外一個是“延遲消費”,這個應該算是RocketMQ的特色功能之一了吧。接下來,我們就分別看一下這兩個功能。
廣播是把消息發送給訂閱了這個主題的所有消費者。這個定義很清楚,但是這裏邊的知識點你都掌握了嗎?咱們接着說“廣播”的機會,把消費者這端的內容好好和大家說說。
好了,說了這麼多,我們實驗一下吧,先把消費者配置成廣播,如下:
@Bean(name = "broadcast", initMethod = "start",destroyMethod = "shutdown")
public DefaultMQPushConsumer broadcast() throws MQClientException {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("broadcast");
consumer.setNamesrvAddr("192.168.73.130:9876;192.168.73.131:9876;192.168.73.132:9876;");
consumer.subscribe("cluster-topic","*");
consumer.setMessageModel(MessageModel.BROADCASTING);
consumer.registerMessageListener((MessageListenerConcurrently) (msgs, context) -> {
for (MessageExt msg : msgs) {
System.out.println(new String(msg.getBody()));
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
});
return consumer;
}
consumer.setMessageModel(MessageModel.BROADCASTING);這段代碼,設置消費者為廣播。咱們可以看一下,MessageModel枚舉中只有兩個值,BROADCASTING和CLUSTERING,默認為CLUSTERING。因為要測試廣播,所以我們要啟動多個消費者,還記得什麼是消費者嗎?對了,一個ip+端口算是一個消費者,在這裏我們啟動兩個應用,端口分別是8080和8081。發送端的程序不變,如下:
@Test
public void producerTest() throws Exception {
for (int i = 0;i<5;i++) {
MessageExt message = new MessageExt();
message.setTopic("cluster-topic");
message.setKeys("key-"+i);
message.setBody(("this is simpleMQ,my NO is "+i+"---"+new Date()).getBytes());
SendResult sendResult = defaultMQProducer.send(message);
System.out.println("i=" + i);
System.out.println("BrokerName:" + sendResult.getMessageQueue().getBrokerName());
}
}
我們執行一下發送端的程序,日誌如下:
i=0
BrokerName:broker-a
i=1
BrokerName:broker-a
i=2
BrokerName:broker-b
i=3
BrokerName:broker-b
i=4
BrokerName:broker-b
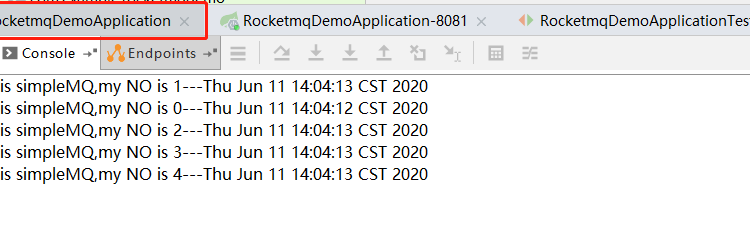
再來看看8080端口的應用後台打印出來的日誌:
消費了5個消息,再看看8081的後台打印的日誌,
也消費了5個。兩個消費者同時消費了消息,這就是廣播。有的小夥伴可能會有疑問了,如果不設置廣播,會怎麼樣呢?私下里實驗一下吧,上面的程序中,只要把設置廣播的那段代碼註釋掉就可以了。運行的結果當然是只有一個消費者可以消費消息。
延遲消息是指消費者過了一個指定的時間后,才去消費這個消息。大家想象一個電商中場景,一個訂單超過30分鐘未支付,將自動取消。這個功能怎麼實現呢?一般情況下,都是寫一個定時任務,一分鐘掃描一下超過30分鐘未支付的訂單,如果有則被取消。這種方式由於每分鐘查詢一下訂單,一是時間不精確,二是查庫效率比較低。這個場景使用RocketMQ的延遲消息最合適不過了,我們看看怎麼發送延遲消息吧,發送端代碼如下:
@Test
public void producerTest() throws Exception {
for (int i = 0;i<1;i++) {
MessageExt message = new MessageExt();
message.setTopic("cluster-topic");
message.setKeys("key-"+i);
message.setBody(("this is simpleMQ,my NO is "+i+"---"+new Date()).getBytes());
message.setDelayTimeLevel(2);
SendResult sendResult = defaultMQProducer.send(message);
System.out.println("i=" + i);
System.out.println("BrokerName:" + sendResult.getMessageQueue().getBrokerName());
}
}
message.setDelayTimeLevel(2);setDelayTimeLevel是什麼意思,設置的是2,難道是2s后消費嗎?怎麼參數也沒有時間單位呢?如果我要自定義延遲時間怎麼辦?我相信很多小夥伴都有這樣的疑問,我也是帶着這樣的疑問查了很多資料,最後在RocketMQ的Github官網上看到了說明,
// org/apache/rocketmq/store/config/MessageStoreConfig.java
private String messageDelayLevel = "1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h";
再看看消費端的代碼,
@Bean(name = "broadcast", initMethod = "start",destroyMethod = "shutdown")
public DefaultMQPushConsumer broadcast() throws MQClientException {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("broadcast");
consumer.setNamesrvAddr("192.168.73.130:9876;192.168.73.131:9876;192.168.73.132:9876;");
consumer.subscribe("cluster-topic","*");
consumer.setMessageModel(MessageModel.BROADCASTING);
consumer.registerMessageListener((MessageListenerConcurrently) (msgs, context) -> {
for (MessageExt msg : msgs) {
Date now = new Date();
System.out.println("消費時間:"+now);
Date msgTime = new Date();
msgTime.setTime(msg.getBornTimestamp());
System.out.println("消息生成時間:"+msgTime);
System.out.println(new String(msg.getBody()));
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
});
return consumer;
}
啟動兩個消費者8080和8081,發送消息,再看看消費者的後台日誌,
消費時間:Thu Jun 11 14:45:53 CST 2020
消息生成時間:Thu Jun 11 14:45:48 CST 2020
this is simpleMQ,my NO is 0---Thu Jun 11 14:45:47 CST 2020
我們看到消費時間比生成時間晚5s,符合我們的預期。這個功能還是比較實用的,如果能夠自定義延遲時間就更好了。
RocketMQ的這兩個知識點還是比較簡單的,大家要分清楚什麼是消費者組,什麼是消費者,什麼是消費者線程。另外就是延遲消息是不支持自定義的,大家可以在Github上看一下源碼。好了~今天就到這裏了。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※台北網頁設計公司全省服務真心推薦
※想知道最厲害的網頁設計公司"嚨底家"!
※推薦評價好的iphone維修中心
曹工說JDK源碼(1)–ConcurrentHashMap,擴容前大家同在一個哈希桶,為啥擴容后,你去新數組的高位,我只能去低位?
曹工說JDK源碼(2)–ConcurrentHashMap的多線程擴容,說白了,就是分段取任務
曹工說JDK源碼(3)–ConcurrentHashMap,Hash算法優化、位運算揭秘
這個基本也是redis 面試的經典題目了,然而,網上不少博客對這個詞的定義都含糊不清,各執一詞。
主要有兩類說法:
大量緩存key,由於設置了相同的過期時間,在某個時刻同時失效,導致此刻的查詢請求,全部湧向db,本來db的tps大概是幾千左右,結果湧入了幾十萬的請求,那db肯定直接就扛不住了
這種說法下面,解決方案一般是,把過期時間增加一個隨機值,這樣,也就不會大批量的key同時失效了
另外一種說法是,本來redis扛下了大部分的請求,但是,由於緩存所在的機器,發生了宕機。此時,緩存這台機器之間就連不上了,redis服務也掛了,此時,你的服務里,發現redis取不到,然後全都跑去查數據庫,那,就發生和前面一樣的情況了,請求全部湧向db,db無響應。
兩類說法,也不用覺得,這個對,那個不對,不過是一個技術名詞,當初發明這個詞的人,估計也沒想那麼多,結果傳播開來之後,就變成了現在這個樣子。
我們這裏主要採用下面那一種說法,因為下面這種說法,其實是已經包含了上面的情景。但是,下面這種場景,要複雜的多,因為redis此時就是一個完全不可信的東西了,你得想好,怎麼不讓它掛掉,那是不是應該部署sentinel、cluster集群?同時,持久化必須要開啟。
這樣呢,掛掉后,短暫的不可用之後,大概幾十s吧,緩存集群就恢復了,就又可用了。
同時,我們還得考慮,假設,現在redis掛了,我們代碼的降級策略是什麼?
大家發現redis掛了,首先,估計是會拋異常了,連接超時;拋了異常后,要直接拋到前端嗎?作為一個穩健的後端程序,那肯定是不行的,你redis掛了,數據庫又沒掛;好吧,那我們就大家一起去查數據庫。
結果,大量的查詢請求,就烏泱泱地跑去查庫了,然後,db卒。這個肯定不行。
所以,我們必須要控制的一點是,當發現某個key失效了,不是大家都去查庫,而是要進行 併發控制。
什麼是併發控制?就是不能全部放過去查庫,只能放少部分,免得把脆弱的db打死。
併發控制,基本就是要爭奪去查庫的權利了,這一步,基本就是一個選舉的過程,可以通過搶鎖的方式,比如Reentrentlock,synchronized,cas也可以。
搶到鎖的線程,有資格去查庫,其他線程要麼被阻塞,要麼自旋
搶到鎖的線程,去查庫,查到數據后,將數據存放在某個地方,通知其他線程去取(如果其他線程被阻塞的話);或者,如果其他線程沒被阻塞,比如sleep 50ms,再去指定的地方拿數據那種,這種就不需要通知
總之,如果其他線程要我們通知,我們就通知;不要我們通知,我們就不通知。
在while(true)里,sleep 50ms,然後再去取數據
這種類似於忙等待,但是每次sleep一會,所以還不錯
將自己阻塞,等待搶到鎖的線程,構建完緩存后,來喚醒
在while(true)里,一直忙循環,期間一直檢查數據是否已經ok了,這種方案呢,要看裏面:檢查數據的操作,是否耗時;如果只是檢查jvm內存里的數據,那還好;否則的話,假設要去檢查redis的話,這種io比較耗時的操作的話,就不合適了,cpu會一直空轉。
主線程構建緩存時,其他線程,在while(true)里,sleep 一定時間,然後再檢查數據是否ready。
說了這麼多,好像和題目里的concurrenthashmap沒啥關係,不,是有關係的,因為,這個思路,其實就是來自於concurrentHashMap。
在我們用無參構造函數,去new一個ConcurrentHashMap時,此時還不會去創建底層數組,這個是一個小優化。什麼時候創建數組呢,是在我們第一次去put的時候。
put的時候,會調用putVal。
其中,putVal代碼如下:
transient volatile Node<K,V>[] table;
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
// 1
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// 2
if (tab == null || (n = tab.length) == 0)
tab = initTable();
1處,把field table,賦值給局部變量tab
2處,如果tab為null,則進行initTable初始化
這個2處,在多線程put的時候,是可能多個線程同時進來的。有併發問題。
我們接下來,看看initTable是怎麼解決這個問題的,畢竟,我們new數組,只new一次即可,new那麼多次,沒用,對性能有損耗。所以,這裏面肯定會多線程爭奪初始化權利的代碼。
private transient volatile int sizeCtl;
transient volatile Node<K,V>[] table;
/**
* Initializes table, using the size recorded in sizeCtl.
*/
private final Node<K,V>[] initTable() {
Node<K,V>[] tab;
int sc;
// 0
while ((tab = table) == null || tab.length == 0) {
// 1
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
// 2
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
// 3
if ((tab = table) == null || tab.length == 0) {
// 4
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
// 5
sizeCtl = sc;
}
break;
}// end if
}// end while
return tab;
}
1處,這裏把sizeCtl,賦值給局部變量sc。這裏的sizeCtl是一個很重要的field,當我們new完之後,默認這個字段,要麼為0,要麼為準備創建的底層數組的長度。
這裏去判斷是否小於0,那肯定不滿足,小於0,會是什麼意思?當某個線程,搶到了這個initTable中的底層數組的創建權利時,就會把sizeCtl改為 -1。
所以,這裏的意思是,看看是否已經有其他線程在初始化了,如果已經有了,則直接調用:
Thread.yield();
這個方法的意思是,暗示操作系統,自己準備放棄cpu;但操作系統,自有它自己的線程調度規則,所以,這個方法可能沒什麼效果;我們業務代碼,這裏一般可以修改為Thread.sleep。
這個方法調用完成后,後續也沒有其他代碼,所以會直接跳轉到循環開始處(0處代碼),判斷table是否初始化ok了,如果沒有ok,則會繼續進來。
2處,使用cas,如果此時,sizeCtl的值等於sc的值,就修改sizeCtl為 -1;如果成功,則返回true,進入3處
否則,會跳轉到0處,繼續循環。
3處,雖然搶到了控制權,但是這裏還是要再判斷一下,不然可能出現重複初始化,即,不加這一行,4處的代碼,會被重複執行
4處開始,這裏去執行真正的初始化邏輯。
//
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
// 1
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
// 2
table = tab = nt;
sc = n - (n >>> 2);
這裏的1處,new數組;2處,賦值給field:table;此時,因為table 這個field是volatile修飾的,所以其他線程會馬上感知到。0處代碼就不會為true了,就不會繼續循環了。
5處,修改sizeCtl為正數。
這裏說下,為啥要加3處的那個判斷。
現在,假設線程A,在初始化完成后,走到了5處,修改了sizeCtl為正數;而線程B,剛好執行1處代碼:
// 1
if ((sc = sizeCtl) < 0)
那肯定,1處就不滿足了;然後就會進到2處,cas修改成功,進行初始化。沒有3處判斷的話,就會重複初始化。
我這裏的方案,還是比較簡單那種,就是,n個線程同時爭奪構建緩存的權利;winner線程,構建緩存后,會把緩存設置到redis;其他線程則是一直在while(true)里sleep一段時間,然後檢查redis里的數據是否不為空。
這個方案中,redis掛了這種情況,是沒在考慮中的,但是一個方案,沒辦法立馬各方面全部到位,後續我再完善一下。
@Override
public Users getUser(long userId) {
ValueOperations<String, Users> ops = redisTemplate.opsForValue();
// 1
Users s = ops.get(String.valueOf(userId));
if (s == null) {
/**
* 2 這裏要去查庫獲取值
*/
Users users = getUsersFromDB(userId);
// 3
ops.set(String.valueOf(users.getUserId()),users);
return users;
}
return s;
}
private Users getUsersFromDB(long userId) {
Users users = new Users();
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("spent 1s to get user from db");
users.setUserId(userId);
users.setUserName("zhangsan");
return users;
}
直接看上面的1,2,3處。就是檢查、構建緩存,設置到緩存的過程。
// 1
private volatile int initControl;
@Override
public Users getUser(long userId) {
ValueOperations<String, Users> ops = redisTemplate.opsForValue();
Users users;
while (true) {
// 2
users = ops.get(String.valueOf(userId));
if (users != null) {
// 3
break;
}
// 4
int initControlLocal = initControl;
/**
* 5 如果已經有線程在進行獲取了,則直接放棄cpu
*/
if (initControlLocal < 0) {
// log.info("initControlLocal < 0,just yield and wait");
// Thread.yield();
try {
Thread.sleep(50);
} catch (InterruptedException e) {
log.warn("e:{}", e);
}
continue;
}
/**
* 6 爭奪控制權
*/
boolean bGotChanceToInit = U.compareAndSwapInt(this,
INIT_CONTROL, initControlLocal, -1);
// 7
if (bGotChanceToInit) {
try {
// 8
users = ops.get(String.valueOf(userId));
if (users == null) {
log.info("got change to init");
/**
* 9 這裏要去查庫獲取值
*/
users = getUsersFromDB(userId);
ops.set(String.valueOf(users.getUserId()), users);
log.info("init over");
}
} finally {
// 10
initControl = 0;
}
break;
}// end if (bGotChanceToInit)
}// end while
return users;
}
1處,定義了一個field,initControl;默認為0.線程們會去使用cas,修改為-1,成功的線程,即獲得初始化緩存的權利。
注意,要定義為volatile,保證線程間的可見性
2處,去redis獲取緩存,如果不為null,直接返回
4處,如果沒取到緩存,則進入此處;此處,將field:initControl賦值給局部變量
5處,判斷局部變量initControlLocal,是否小於0;小於0,說明已經有線程在進行初始化了,直接contine,繼續下一次循環
6處,如果當前還沒有線程在初始化,則開始競爭初始化的權利,誰成功地用cas,修改field:initControl為-1,誰就獲得這個權利
7處,如果當前線程獲得了權利,則進入8處,否則,會繼續下一次循環
8處,再次去redis,獲取緩存,如果不為空,則進入9處
9處,查庫,設置緩存
10處,修改field:initControl為0,表示退出初始化
這裏的代碼,整體和hashmap中的initTable是一模一樣的。
上面的方案,怎麼測試沒問題呢?我寫了一段測試代碼。
ThreadPoolExecutor executor = new ThreadPoolExecutor(100, 100,
60, TimeUnit.SECONDS, new ArrayBlockingQueue<>(1000), new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
log.info("discard:{}",r);
}
});
@RequestMapping("/test.do")
public void test() {
// 0
iUsersService.deleteUser(111L);
CyclicBarrier barrier = new CyclicBarrier(100);
for (int i = 0; i < 100; i++) {
executor.submit(new Runnable() {
@Override
public void run() {
try {
barrier.await();
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
long start = System.currentTimeMillis();
// 1
Users users = iUsersService.getUser(111L);
log.info("result:{},spent {} ms", users, System.currentTimeMillis() - start);
}
});
}
}
上面模擬100併發下,獲取緩存。
0處,把緩存刪了,模擬緩存失效
1處,調用方法,獲取緩存。
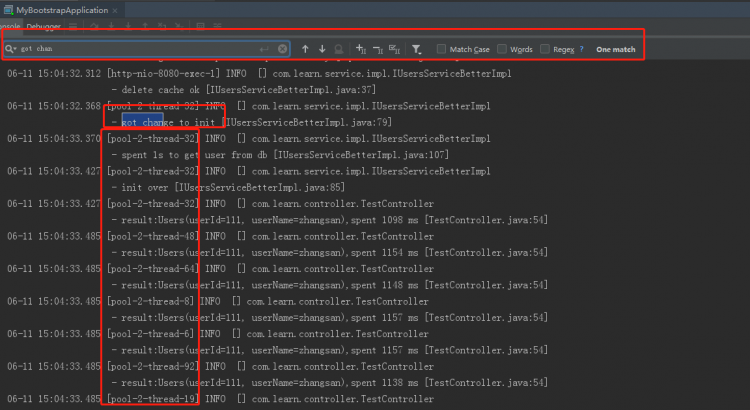
效果如下:
可以看到,只有一個線程拿到了初始化權利。
https://gitee.com/ckl111/all-simple-demo-in-work-1/tree/master/redis-cache-avalanche
jdk的併發包,寫得真是有水平,大家仔細研究的話,必有收穫。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家公司費用,距離,噸數怎麼算?達人教你簡易估價知識!
※教你寫出一流的銷售文案?
※超省錢租車方案
Spring的依賴注入分為基於構造函數的依賴注入和基於setter方法的依賴注入。
<!-- 通過構造器參數索引方式依賴注入 -->
<bean id="byIndex" class="cn.javass.spring.chapter3.HelloImpl3">
<constructor-arg index="0" value="Hello World!"/>
<constructor-arg index="1" value="1"/>
</bean>
<!-- 通過構造器參數類型方式依賴注入 -->
<bean id="byType" class="cn.javass.spring.chapter3.HelloImpl3">
<constructor-arg type="java.lang.String" value="Hello World!"/>
<constructor-arg type="int" value="2"/>
</bean>
<!-- 通過構造器參數名稱方式依賴注入 -->
<bean id="byName" class="cn.javass.spring.chapter3.HelloImpl3">
<constructor-arg name="message" value="Hello World!"/>
<constructor-arg name="index" value="3"/>
</bean>
<!-- 通過靜態的工廠方法注入 -->
<bean id="byName" class="cn.javass.spring.chapter3.HelloImpl3" factory-method="getBean">
<constructor-arg name="message" value="Hello World!"/>
<constructor-arg name="index" value="3"/>
</bean>
<bean class="...HelloImpl4">
<property name="message" value="Hello"/>
<property name="index" value="1"/> //value中的值全部是字符串形式,如果轉換出錯會報異常
</bean>
<bean id="Hello2" class="com.csx.personal.web.services.HelloImpl2">
<property name="msg" ref="message"/> //msg屬性是一個類對象
</bean>
循環依賴:創建Bean A需要Bean B,創建Bean B需要Bean C,創建Bean C需要Bean A 這樣就形成了循環依賴。 Spring的解決方案:Spring創建Bean的時候會維護一個池,在創建A的時候會去池中查找A是否在池子中,假如發現就拋出循環依賴異常。
避免依賴注入時的循環依賴:可以使用setter方式注入,不要使用構造器形式的注入。
<bean id="myDataSource" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<!-- results in a setDriverClassName(String) call -->
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/mydb"/>
<property name="username" value="root"/>
<property name="password" value="masterkaoli"/>
</bean>
這邊分別給出了一個引用當前容器和引用父容器中Bean的列子。
<bean id="Hello2" class="com.csx.personal.web.services.HelloImpl2">
<property name="msg"> //msg屬性是一個類對象
<ref bean="message"/> //引用同一個容器中id="message"的Bean
</property>
</bean>
<!-- 引用父容器中的Bean -->
<!-- in the parent context -->
<bean id="accountService" class="com.something.SimpleAccountService">
<!-- insert dependencies as required as here -->
</bean>
<!-- in the child (descendant) context -->
<bean id="accountService" <!-- bean name is the same as the parent bean -->
class="org.springframework.aop.framework.ProxyFactoryBean">
<property name="target">
<ref parent="accountService"/> <!-- notice how we refer to the parent bean -->
</property>
<!-- insert other configuration and dependencies as required here -->
</bean>
內部bean:這種bean一般只讓某個外部bean使用(和內部類相似),不讓容器中的其他Bean使用。
<bean id="outer" class="...">
<property name="target">
<!-- this is the inner bean -->
<bean class="com.example.Person">
<property name="name" value="Fiona Apple"/>
<property name="age" value="25"/>
</bean>
</property>
</bean>
集合類的注入建議使用util命名空間
<util:map id="myMap" key-type="java.lang.String" value-type="java.lang.String">
<entry key="key1" value="chen"/>
<entry key="key2" value="zhao"/>
</util:map>
<util:list id="myList" value-type="java.lang.String">
<value>chen</value>
<value>zhao</value>
</util:list>
<util:set id="mySet" value-type="java.lang.String" scope="singleton">
<value>chen</value>
<value>zhao</value>
</util:set>
<util:properties id="myProp" location="classpath:xx.properties"/>
<bean class="...HelloImpl4">
<property name="message"><null/></property> //null值
<property name="index" value=""/> //空字符串
</bean>
depends-on屬性用來指定bean的初始化順序。這個屬性只對scope是單列的bean生效。
<!--在實例化beanOne之前先實例化manager和accountDao這兩個bean-->
<bean id="beanOne" class="ExampleBean" depends-on="manager,accountDao">
<property name="manager" ref="manager" />
</bean>
<bean id="manager" class="ManagerBean" />
<bean id="accountDao" class="x.y.jdbc.JdbcAccountDao" />
bean的定義中有一個lazy-init這個屬性,用來設置單列bean在容器初始化后是否實例化這個bean。默認情況下容器是會實例化所有單例bean的,我們也建議這麼做,因為這樣能在容器初始化階段就發現bean配置是否正確。如果一個Bean按照下面的設置,lazy-init被設置為true那麼它不會被容器預初始化,只有在被使用的時候才被初始化。但是如果有一個單列類依賴了這個Bean,那麼這個被設置成懶加載的Bean還是會被預初始化。
<bean id="lazy" class="com.something.ExpensiveToCreateBean" lazy-init="true"/>
如果想設置全局的單例Bean都不要預先初始化,那麼可以在xml中做如下設置:
<beans default-lazy-init="true">
<!-- no beans will be pre-instantiated... -->
</beans>
當我們要往一個bean的某個屬性里注入另外一個bean,我們會使用property +ref標籤的形式。但是對於大型項目,假設有一個bean A被多個bean引用注入,如果A的id因為某種原因修改了,那麼所有引用了A的bean的ref標籤內容都得修改,這時候如果使用autowire=”byType”,那麼引用了A的bean就完全不用修改了。
<!--autowire的用法如下,對某個Bean配置autowire模式 -->
<!--和給Bean的屬性添加@AutoWired註解的效果一致-->
<bean id="auto" class="example.autoBean" autowire="byType"/>
autowire的幾種模式:
需要注意的是上面這5中方式注入都需要我們提供相應的setter方法,通過@Autowired的方式不需要提供相應的setter方法。
如果按照下面的方式配置了Bean,那麼這個Bean將不會作為自動裝配的候選Bean。但是autowire-candidate自會對byType形式的自動注入生效,如果我們是通過byName的形式進行自動注入,那麼還是能注入這個Bean。
<bean id="auto" class="example.autoBean" autowire="byType" autowire-candidate="false"/>
如果我們只想讓某些Bean作為自動裝配的候選Bean,那麼可以進行全局設置。如果做了下面的配置,那麼只有id為bean1和bean2的Bean才會成為自動裝配的候選Bean。同時default-autowire-candidates的值支持正則表達式形式。但是強烈建議不要配置這個選項的值,使用默認的配置就行。
<beans default-autowire-candidates="bean1,bean2">
</beans>
我們在配置bean的時候首先要考慮這個bean是要配置成單例模式還是其他模式。 在我們的應用中,絕大多數類都是單例類。當單例類引用單例類,或者原型類引用原型類、單例類時,我們只要像普通的配置方式就行了。但是當一個單例類引用原型類時,就會出現問題。這種情況可以使用下面的方式進行注入。
@Service
@Scope("prototype")
public class MyService1 {
public void service() {
System.out.println(this.toString() + ":id");
}
}
@Service
public abstract class MyService {
private MyService1 service1;
public void useService(){
service1 = createService1();
service1.service();
}
@Lookup("myService1")
public abstract MyService1 createService1();
}
//也可以這樣配置bean
<bean id="serviceC" class="com.csx.demo.springdemo.service.ServiceC">
<lookup-method bean="serviceD" name="createService"/>
</bean>
<bean id="serviceD" class="com.csx.demo.springdemo.service.ServiceD" scope="prototype"/>
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計最專業,超強功能平台可客製化