[!NOTE]
能熟練掌握每種繼承方式的手寫實現,並知道該繼承實現方式的優缺點。
原型鏈繼承
function Parent() {
this.name = 'zhangsan';
this.children = ['A', 'B', 'C'];
}
Parent.prototype.getName = function() {
console.log(this.name);
}
function Child() {
}
Child.prototype = new Parent();
var child = new Child();
console.log(child.getName());
[!NOTE]
主要問題:
1. 引用類型的屬性被所有實例共享(this.children.push(‘name’))
2. 在創建Child的實例的時候,不能向Parent傳參
借用構造函數(經典繼承)
function Parent(age) {
this.names = ['zhangsan', 'lisi'];
this.age = age;
this.getName = function() {
return this.names;
}
this.getAge = function() {
return this.age;
}
}
function Child(age) {
Parent.call(this, age);
}
var child = new Child(18);
child.names.push('haha');
console.log(child.names);
var child2 = new Child(20);
child2.names.push('yaya');
console.log(child2.names);
[!NOTE]
優點:
1. 避免了引用類型的屬性被所有實例共享
2. 可以直接在Child中向Parent傳參
缺點:
方法都在構造函數中定義了,每次創建實例都會創建一遍方法
組合繼承(原型鏈繼承和經典繼承雙劍合璧)
/**
* 父類構造函數
* @param name
* @constructor
*/
function Parent(name) {
this.name = name;
this.colors = ['red', 'green', 'blue'];
}
Parent.prototype.getName = function() {
console.log(this.name);
}
// child
function Child(name, age) {
Parent.call(this, name);
this.age = age;
}
Child.prototype = new Parent();
// 校正child的構造函數
Child.prototype.constructor = Child;
// 創建實例
var child1 = new Child('zhangsan', 18);
child1.colors.push('orange');
console.log(child1.name, child1.age, child1.colors); // zhangsan 18 (4) ["red", "green", "blue", "orange"]
var child2 = new Child('lisi', 28);
console.log(child2.name, child2.age, child2.colors); // lisi 28 (3) ["red", "green", "blue"]
[!NOTE]
優點: 融合了原型鏈繼承和構造函數的優點,是Javascript中最常用的繼承模式
—— 高級繼承的實現
原型式繼承
function createObj(o) {
function F(){};
// 關鍵:將傳入的對象作為創建對象的原型
F.prototype = o;
return new F();
}
// test
var person = {
name: 'zhangsan',
friends: ['lisi', 'wangwu']
}
var person1 = createObj(person);
var person2 = createObj(person);
person1.name = 'wangdachui';
console.log(person1.name, person2.name); // wangdachui, zhangsan
person1.friends.push('songxiaobao');
console.log(person2.friends); // lisi wangwu songxiaobao
[!WARNING]
缺點:
對於引用類型的屬性值始終都會共享相應的值,和原型鏈繼承一樣
寄生式繼承
// 創建一個用於封裝繼承過程的函數,這個函數在內部以某種形式來增強對象
function createObj(o) {
var clone = Object.create(o);
clone.sayName = function() {
console.log('say HelloWorld');
}
return clone;
}
[!WARNING]
缺點:與借用構造函數模式一樣,每次創建對象都會創建一遍方法
寄生組合式繼承
基礎版本
function Parent(name) {
this.name = name;
this.colors = ['red', 'green', 'blue'];
}
Parent.prototype.getName = function() {
console.log(this, name);
}
function Child(name, age) {
Parent.call(this, name);
this.age = age;
}
// test1:
// 1. 設置子類實例的時候會調用父類的構造函數
Child.prototype = new Parent();
// 2. 創建子類實例的時候也會調用父類的構造函數
var child1 = new Child('zhangsan', 18); // Parent.call(this, name);
// 思考:如何減少父類構造函數的調用次數呢?
var F = function(){};
F.prototype = Parent.prototype;
Child.prototype = new F();
// 思考:下面的這一句話可以嗎?
/* 分析:因為此時Child.prototype和Parent.prototype此時指向的是同一個對象,
因此部分數據相當於此時是共享的(引用)。
比如此時增加 Child.prototype.testProp = 1;
同時會影響 Parent.prototype 的屬性的。
如果不模擬,直接上 es5 的話應該是下面這樣吧
Child.prototype = Object.create(Parent.prototype);*/
Child.prototype = Parent.prototype;
// 上面的三句話可以簡化為下面的一句話
Child.prototype = Object.create(Parent.prototype);
// test2:
var child2 = new Child('lisi', 24);
優化版本
// 自封裝一個繼承的方法
function object(o) {
// 下面的三句話實際上就是類似於:var o = Object.create(o.prototype)
function F(){};
F.prototype = o.prototype;
return new F();
}
function prototype(child, parent) {
var prototype = object(parent.prototype);
// 維護原型對象prototype裏面的constructor屬性
prototype.constructor = child;
child.prototype = prototype;
}
// 調用的時候
prototype(Child, Parent)
創建對象的方法
- 字面量創建
- 構造函數創建
- Object.create()
var o1 = {name: 'value'};
var o2 = new Object({name: 'value'});
var M = function() {this.name = 'o3'};
var o3 = new M();
var P = {name: 'o4'};
var o4 = Object.create(P)
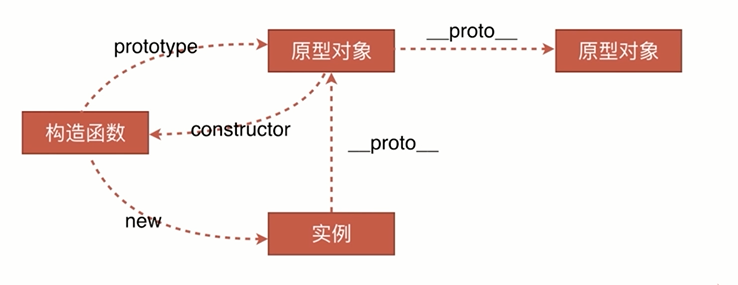
原型
- JavaScript 的所有對象中都包含了一個
__proto__ 內部屬性,這個屬性所對應的就是該對象的原型
- JavaScript 的函數對象,除了原型
__proto__ 之外,還預置了 prototype 屬性
- 當函數對象作為構造函數創建實例時,該 prototype 屬性值將被作為實例對象的原型
__proto__。
原型鏈
任何一個實例對象通過原型鏈可以找到它對應的原型對象,原型對象上面!
的實例和方法都是實例所共享的。
一個對象在查找以一個方法或屬性時,他會先在自己的對象上去找,找不到時,他會沿着原型鏈依次向上查找。
注意: 函數才有prototype,實例對象只有有__proto__, 而函數有的__proto__是因為函數是Function的實例對象
instanceof原理
判斷實例對象的__proto__屬性與構造函數的prototype是不是用一個引用。如果不是,他會沿着對象的__proto__向上查找的,直到頂端Object。
判斷對象是哪個類的直接實例
使用對象.construcor直接可判斷
構造函數,new時發生了什麼?
var obj = {};
obj.__proto__ = Base.prototype;
Base.call(obj);
- 創建一個新的對象 obj;
- 將這個空對象的__proto__成員指向了Base函數對象prototype成員對象
- Base函數對象的this指針替換成obj, 相當於執行了Base.call(obj);
- 如果構造函數显示的返回一個對象,那麼則這個實例為這個返回的對象。 否則返回這個新創建的對象
類
類的聲明
// 普通寫法
function Animal() {
this.name = 'name'
}
// ES6
class Animal2 {
constructor () {
this.name = 'name';
}
}
繼承
借用構造函數法
在構造函數中 使用Parent.call(this)的方法繼承父類屬性。
原理: 將子類的this使用父類的構造函數跑一遍
缺點: Parent原型鏈上的屬性和方法並不會被子類繼承
function Parent() {
this.name = 'parent'
}
function Child() {
Parent.call(this);
this.type = 'child'
}
原型鏈實現繼承
原理:把子類的prototype(原型對象)直接設置為父類的實例
缺點:因為子類只進行一次原型更改,所以子類的所有實例保存的是同一個父類的值。
當子類對象上進行值修改時,如果是修改的原始類型的值,那麼會在實例上新建這樣一個值;
但如果是引用類型的話,他就會去修改子類上唯一一個父類實例裏面的這個引用類型,這會影響所有子類實例
function Parent() {
this.name = 'parent'
this.arr = [1,2,3]
}
function Child() {
this.type = 'child'
}
Child.prototype = new Parent();
var c1 = new Child();
var c2 = new Child();
c1.__proto__ === c2.__proto__
組合繼承方式
組合構造函數中使用call繼承和原型鏈繼承。
原理: 子類構造函數中使用Parent.call(this);的方式可以繼承寫在父類構造函數中this上綁定的各屬性和方法;
使用Child.prototype = new Parent()的方式可以繼承掛在在父類原型上的各屬性和方法
缺點: 父類構造函數在子類構造函數中執行了一次,在子類綁定原型時又執行了一次
function Parent() {
this.name = 'parent'
this.arr = [1,2,3]
}
function Child() {
Parent.call(this);
this.type = 'child'
}
Child.prototype = new Parent();
組合繼承方式 優化1:
因為這時父類構造函數的方法已經被執行過了,只需要關心原型鏈上的屬性和方法了
Child.prototype = Parent.prototype;
缺點:
- 因為原型上有一個屬性為
constructor,此時直接使用父類的prototype的話那麼會導致 實例的constructor為Parent,即不能區分這個實例對象是Child的實例還是父類的實例對象。
- 子類不可直接在prototype上添加屬性和方法,因為會影響父類的原型
注意:這個時候instanseof是可以判斷出實例為Child的實例的,因為instanceof的原理是沿着對象的__proto__判斷是否有一個原型是等於該構造函數的原型的。這裏把Child的原型直接設置為了父類的原型,那麼: 實例.__proto__ === Child.prototype === Child.prototype
組合繼承方式 優化2 – 添加中間對象【最通用版本】:
function Parent() {
this.name = 'parent'
this.arr = [1,2,3]
}
function Child() {
Parent.call(this);
this.type = 'child'
}
Child.prototype = Object.create(Parent.prototype); //提供__proto__
Child.prototype.constrctor = Child;
Object.create()方法創建一個新對象,使用現有的對象來提供新創建的對象的__proto__
創建JS對象的多種方式總結
工廠模式
/**
* 工廠模式創建對象
* @param name
* @return {Object}
*/
function createPerson(name){
var o = new Object();
o.name = name;
o.getName = function() {
console.log(this.name);
}
return o;
}
var person = createPerson('zhangsan');
console.log(person.__proto__ === Object.prototype); // true
缺點:無法識別當前的對象,因為創建的所有對象實例都指向的是同一個原型
構造函數模式
構造函數創建對象基礎版本
/**
* 使用構造函數的方式來創建對象
* @param name
* @constructor
*/
function Person(name) {
this.name = name;
this.getName = function() {
console.log(this.name)
}
}
var person = new Person('lisi');
console.log(person.__proto__ === Person.prototype)
優點:實例剋識別偽一個特定的類型
缺點:每次創建實例對象的時候,每個方法都會被創建一次
構造函數模式優化
function Person(name) {
this.name = name;
this.getName = getName;
}
function getName() {
console.log(this.name);
}
var person = new Person('zhangsan');
console.log(person.__proto__ === Person.prototype);
優點:解決了每個方法都要被重新創建的問題
缺點:不合乎代碼規範……
原型模式
原型模式基礎版
function Person(name) {
}
Person.prototype.name = 'lisi';
Person.prototype.getName = function() {
console.log(this.name);
}
var person = new Person();
console.log(Person.prototype.constructor) // Person
優點:方法不會被重新創建
缺點:1. 所有的屬性和方法所有的實例上面都是共享的;2. 不能初始化參數
原型模式優化版本一
function Person(name) {
}
Person.prototype = {
name: 'lisi',
getName: function() {
console.log(this.name);
}
}
var person = new Person();
console.log(Person.prototype.constructor) // Object
console.log(person.constructor == person.__proto__.constructor) // true
優點:封裝性好了一些
缺點:重寫了Person的原型prototype屬性,丟失了原始的prototype上的constructor屬性
原型模式優化版本二
function Person(name) {
}
Person.prototype = {
constructor: Person,
name: 'lisi',
getName: function() {
console.log(this.name)
}
}
var person = new Person();
優點:實例可以通過constructor屬性找到所屬的構造函數
缺點:所有的屬性和方法都共享,而且不能初始化參數
組合模式
function Person(name) {
this.name = name;
}
Person.prototype = {
constructor: Person,
getName: function() {
console.log(this.name)
}
}
var person = new Person('zhangsan');
優點:基本符合預期,屬性私有,方法共享,是目前使用最廣泛的方式
缺點:方法和屬性沒有寫在一起,封裝性不是太好
動態原型模式
// 第一種創建思路:
function Person(name) {
this.name = name;
if (typeof this.getName !== 'function') {
Person.prototype.getName = function() {
console.log(this.name);
}
}
}
var person = new Person();
// 第二種創建的思路:使用對象字面量重寫原型上的方法
function Person(name) {
this.name = name;
if (typeof this.getName !== 'function') {
Person.prototype = {
constructor: Person,
getName: function() {
console.log(this.name)
}
}
return new Person(name);
}
}
var person1 = new Person('zhangsan');
var person2 = new Person('lisi');
console.log(person1.getName());
console.log(person2.getName());
寄生構造函數模式
/**
* 寄生構造函數模式
* @param name
* @return {Object}
* @constructor
*/
function Person(name){
var o = new Object();
o.name = name;
o.getName = function() {
console.log(this.name)
}
return o;
}
var person = new Person('zhangsan');
console.log(person instanceof Person); // false
console.log(person instanceof Object); // true
// 使用寄生-構造函數-模式來創建一個自定義的數組
/**
* 特殊數組的構造器
* @constructor
*/
function SpecialArray() {
var values = new Array();
/*for (var i = 0, len = arguments.length; i < len; i++) {
values.push(arguments[i]);
}*/
// 開始添加數據(可以直接使用apply的方式來優化代碼)
values.push.apply(values, arguments);
// 新增的方法
values.toPipedString = function(){
return this.join('|');
}
return values;
}
// 使用new來創建對象
var colors1 = new SpecialArray('red1', 'green1', 'blue1');
// 不使用new來創建對象
var colors2 = SpecialArray('red2', 'green2', 'blue2');
console.log(colors1, colors1.toPipedString());
console.log(colors2, colors2.toPipedString());
穩妥構造函數模式
/**
* 穩妥的創建對象的方式
* @param name
* @return {number}
* @constructor
*/
function Person(name){
var o = new Object();
o.sayName = function() {
// 這裡有點類似於在一個函數裏面使用外部的變量
// 這裏直接輸出的是name
console.log(name);
}
return o;
}
var person = Person('lisi');
person.sayName();
person.name = 'zhangsan';
person.sayName();
console.log(person instanceof Person); // false
console.log(person instanceof Object); // false
[!NOTE]
與寄生的模式的不同點:1. 新創建的實例方法不引用this 2.不使用new操作符調用構造函數
優點:最適合一些安全的環境中使用
缺點:和工廠模式一樣,是無法識別對象的所屬類型的
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!












 其中,福建新龍馬汽車股份有限公司涉及的2款車型是FJ6410BEVA1純電動多用途乘用車和FJ6411BEVA1純電動多用途乘用車。資料顯示,FJ6410BEVA1純電動多用途乘用車的動力電池由河南鋰想動力科技有限公司生產,該公司並不在動力電池57家白名單之中。而FJ6411BEVA1純電動多用途乘用車的動力電池由廈門華鋰能源有限公司提供,廈門華鋰也不在動力電池57家白名單之中。 鄭州日產汽車有限公司生產的ZN6440V1Y純電動乘用車也被勒令停止生產銷售。資料顯示,該車型的動力電池由河南環宇賽爾新能源科技有限公司提供,而環宇賽爾在57家電池白名單之中。對於該款車型為何被停止生產銷售,目前不得而知。 文章來源:蓋世汽車
其中,福建新龍馬汽車股份有限公司涉及的2款車型是FJ6410BEVA1純電動多用途乘用車和FJ6411BEVA1純電動多用途乘用車。資料顯示,FJ6410BEVA1純電動多用途乘用車的動力電池由河南鋰想動力科技有限公司生產,該公司並不在動力電池57家白名單之中。而FJ6411BEVA1純電動多用途乘用車的動力電池由廈門華鋰能源有限公司提供,廈門華鋰也不在動力電池57家白名單之中。 鄭州日產汽車有限公司生產的ZN6440V1Y純電動乘用車也被勒令停止生產銷售。資料顯示,該車型的動力電池由河南環宇賽爾新能源科技有限公司提供,而環宇賽爾在57家電池白名單之中。對於該款車型為何被停止生產銷售,目前不得而知。 文章來源:蓋世汽車
 有知情人士透露,特斯拉的“國民車”是一款A級車,售價將比Model 3還低1萬美元,僅2.5萬美元,約合人民幣16.65萬元。不過雖然價格有所下降,但因電池技術不斷提高,成本不斷下降,該款車型的續航里程將仍在300km以上。 該人士還介紹,此款“國民車”應該在2018年左右向全球公佈,2020年交付。屆時,特斯拉將在中國完成國產化,所以中國消費者未來購買該款車型可享受與美國相同的售價。 文章來源:EV世紀
有知情人士透露,特斯拉的“國民車”是一款A級車,售價將比Model 3還低1萬美元,僅2.5萬美元,約合人民幣16.65萬元。不過雖然價格有所下降,但因電池技術不斷提高,成本不斷下降,該款車型的續航里程將仍在300km以上。 該人士還介紹,此款“國民車”應該在2018年左右向全球公佈,2020年交付。屆時,特斯拉將在中國完成國產化,所以中國消費者未來購買該款車型可享受與美國相同的售價。 文章來源:EV世紀