作者:凹凸曼 – 暖暖
SVG 即 Scalable Vector Graphics 可縮放矢量圖形,使用XML格式定義圖形。
一、SVG印象
SVG 的應用十分廣泛,得益於 SVG 強大的各種特性。
1.1、 矢量
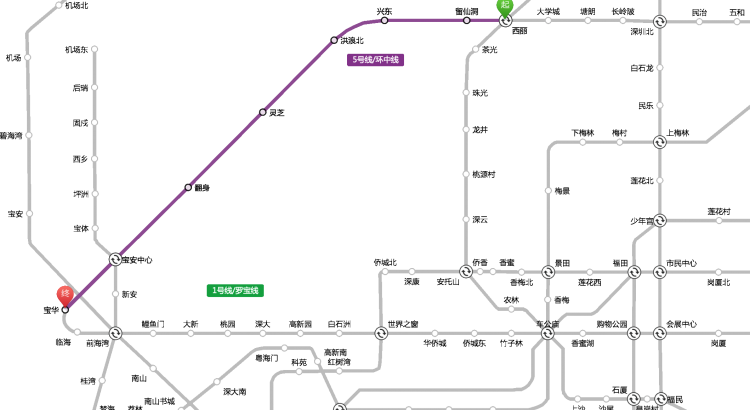
可利用 SVG 矢量的特點,描出深圳地鐵的輪廓:
1.2、iconfont
SVG 可依據一定的規則,轉成 iconfont 使用:
1.3、 foreignObject
利用 SVG 的 foreignObject 標籤實現截圖功能,原理:foreignObject 內部嵌入 HTML 元素:
<svg xmlns="http://www.w3.org/2000/svg">
<foreignObject width="120" height="60">
<p style="font-size:20px;margin:0;">凹凸實驗室 歡迎您</p>
</foreignObject>
</svg>
截圖實現流程:
- 首先聲明一個基礎的 svg 模版,這個模版需要一些基礎的描述信息,最重要的,它要有
<foreignObject></foreignObject>這對標籤; - 將要渲染的 DOM 模版模版嵌入
foreignObject即可; - 利用
Blob構建 svg 對象; - 利用
URL.createObjectURL(svg)取出 URL。
1.4、SVG SMIL
由於微信編輯器不允許嵌入 <style><script><a> 標籤,利用SVG SMIL 可進行微信公眾號極具創意的圖文排版設計,包括動畫與交互。
但是也要注意,標籤里不允許有id,否則會被過濾或替換掉。
點擊 “凹凸實驗室” 后,圍繞 “凹凸實驗室” 中心旋轉 360度,點擊0.5秒后 出現 https://aotu.io/ ,動畫只運行一次。
下圖為 GIF循環演示:
代碼如下:
<svg width="360" height="300" xmlns="http://www.w3.org/2000/svg">
<g>
<!-- 點擊后 運行transform旋轉動畫,restart="never"表示只運行一次 -->
<animateTransform attributeName="transform" type="rotate" begin="click" dur="0.5s" from="0 100 80" to="360 100 80" fill="freeze" restart="never" />
<g>
<text font-family="microsoft yahei" font-size="20" x="50" y="80">
凹凸實驗室
</text>
</g>
<g style="opacity: 0;">
<!-- 同一個初始位置以及大致的寬高,觸發點擊事件 -->
<text font-family="microsoft yahei" font-size="20" x="50" y="80">https://aotu.io/</text>
<!-- 點擊后 運行transform移動動畫,改變文本的位置 -->
<animateTransform attributeName="transform" type="translate" begin="click" dur="0.1s" to="0 40" fill="freeze" restart="never" />
<!-- 點擊0.5秒后 運行opacity显示動畫 -->
<animate attributeName="opacity" begin="click+0.5s" from="0" to="1" dur="0.5s" fill="freeze" restart="never" />
</g>
</g>
</svg>
以上是鄙人對SVG的大致印象,最近的需求開發再次刷新了我的認知,那就是 SVG實現非比例縮放 以及 小程序不支持SVG標籤的處理,下面容我來講述一番。
二、SVG 實現非比例縮放
我們熟知的 iconfont,可通過改變字體大小縮放,但是這是 比例縮放,那如何實現 SVG 的非比例縮放呢?
如下圖所示,如何將 一隻兔子 非比例縮放?
划重點:實現非比例縮放主要涉及三個知識點:viewport、viewBox和preserveAspectRatio,viewport 與viewBox 結合可實現縮放的功能,viewBox 與 preserveAspectRatio 結合可實現非比例的功能。
2.1、viewport
viewport 表示SVG可見區域的大小。
viewport 就像是我們的显示器屏幕大小,超出區域則隱藏,原點位於左上角,x 軸水平向右,y 軸垂直向下。
通過類似CSS的屬性 width、height 指定視圖大小:
<svg width="400" height="200"></svg>
2.2、viewBox
viewBox值有4個数字:x, y, width, height 。
其中 x:左上角橫坐標,y:左上角縱坐標,width:寬度,height:高度。
原點默認位於左上角,x 軸水平向右,y 軸垂直向下。
<svg width="400" height="200" viewBox="0 0 200 100"></svg>
显示器屏幕的畫面,可以特寫,可以全景,這就是 viewBox。
viewBox 可以想象成截屏工具選中的那個框框,和 viewport 作用的結果就是 把框框中的截屏內容再次在 显示器 中全屏显示。
(圖片來源:SVG 研究之路 (23) – 理解 viewport 與 viewbox)
2.3、preserveAspectRatio
上圖的紅色框框和藍色框框,恰好和显示器的比例相同,如果是下圖的綠色框框,怎樣在显示器屏幕中显示呢?
2.3.1、 定義
preserveAspectRatio 作用的對象是 viewBox,使用方法如下:
preserveAspectRatio="[defer] <align> [<meetOrSlice>]"
// 例如 preserveAspectRatio="xMidYMid meet"
其中 defer 此時不是重點,暫且忽略,主要了解 align 和 meetOrSlice 的 用法:
align:由兩個名詞組成,分別代表 viewbox 與 viewport 的 x 方向、y方向的對齊方式。
| 值 | 含義 |
|---|---|
xMin |
viewport 和 viewBox 左邊對齊 |
xMid |
viewport 和 viewBox x軸中心對齊 |
xMax |
viewport 和 viewBox 右邊對齊 |
YMin |
viewport 和 viewBox 上邊緣對齊。注意Y是大寫。 |
YMid |
viewport 和 viewBox y軸中心點對齊。注意Y是大寫。 |
YMax |
viewport 和 viewBox 下邊緣對齊。注意Y是大寫。 |
meetOrSlice:表示如何維持高寬的比例,有三個值 meet、slice、none。meet– 默認值,保持縱橫比縮放 viewBox 適應 viewport,可能會有餘留的空白。slice– 保持縱橫比同時比例小的方向放大填滿 viewport,超出的部分被剪裁掉。none– 扭曲縱橫比以充分適應 viewport。
2.3.2、 例子
例子1:preserveAspectRatio="xMidYMid meet" 表示 綠色框框 與 显示器的 x 方向、y方向的 中心點 對齊;
例子2:preserveAspectRatio="xMidYMin slice" 表示 綠色框框 與 显示器的 x 方向 中心點 對齊,Y 方向 上邊緣對齊,保持比例放大填滿 显示屏 后超出部分隱藏;
例子3:preserveAspectRatio="xMidYMid slice" 表示 綠色框框 與 显示器的 x 方向、y方向的 中心點 對齊,保持比例放大填滿显示屏 后超出部分隱藏;
例子4:preserveAspectRatio="none" 不管三七二十一,隨意縮放綠色框框,填滿 显示屏即可;這就是非比例縮放的答案了。
三、小程序不支持svg標籤怎麼辦
微信小程序官方不支持 SVG 標籤的,但是決定曲線救國,相當於自己實現了一個SVG標籤:使用小程序內置的 Canvas 渲染器, 在 Cax 中實現 SVG 標準的子集,使用 JSX 或者 HTM(Hyperscript Tagged Markup) 描述 SVG 結構行為表現。
但是今天我想講講其他的。
我們知道,小程序雖然不支持 SVG 標籤,但是支持 svg 轉成 base64 後作為 background-image 的 url,如 background-image: url("data:image/svg+xml.......) 。
但是我這邊還有個需求,隨時更改 SVG 每個路徑的顏色,即 顏色可配置:
來迴轉 Base64 肯定是比較麻煩的,有沒有更好的方式呢?
直接貼答案:對於SVG圖形,還有更好的實現方式,就是直接使用SVG XML格式代碼,無需進行base64轉換。
3.1、URL 編碼
直接使用 SVG XML 格式代碼,首先要了解 Data URI的格式。
划重點:base64非必選項,不指定的時候,後面的 <data> 將使用 URL編碼。
3.1.1、入門
百分號編碼(Percent-encoding), 也稱作URL編碼(URL encoding),是特定上下文的統一資源定位符 (URL)的編碼機制。
原理:ASCII 字符 = % + 兩位 ASCII 碼(十六進制)。
例如,字符 a 對應的 ASCII 碼為 0x61,那麼 URL 編碼后得到 %61 。
3.1.2、URL 編碼壓縮
前言:
Data URI 的格式中的 <data> 完全使用URL 編碼也是可以的,如 encodeURIComponent('<svg version="1.1" viewBox= …</svg>')。
但是和轉義前原始SVG相比,可讀性差了很多,而且佔用體積也變大了。
如果深入了解URL 編碼的話,<data> 沒必要全部編碼的。
正文:
RFC3986文檔規定,URL中只允許包含 未保留字符 以及 所有保留字符。
- 未保留字符:包含英文字母(a-zA-Z)、数字(0-9)、-_.~ 4個特殊字符。對於未保留字符,不需要百分號編碼。
- 保留字符:具有特殊含義的字符
:/?#[]@(分隔Url的協議、主機、路徑等組件) 和!$&'()*+,;=(用於在每個組件中起到分隔作用的,如&符號用於分隔查詢多個鍵值對)。 - 受限字符或不安全字符:直接放在Url中的時候,可能會引起解析程序的歧義,因此這部分需要百分號編碼,如
%、空格、雙引號"、尖號 <>等等。
綜上所述,只需要對 受限字符或不安全字符 進行編碼即可。
- JS 處理比較簡單,利用 replace 將 需要編碼的字符 替換掉 即可,基本替換 以下的符號 就夠用了:
svgToUrl (svgData) {
encoded = encoded
.replace(/<!--(.*)-->/g, '') // 親測必須去掉註釋
.replace(/[\r\n]/g, ' ') // 親測最好去掉換行
.replace(/"/g, `'`) // 單引號是保留字符,雙引號改成單引號減少編碼
.replace(/%/g, '%25')
.replace(/&/g, '%26')
.replace(/#/g, '%23')
.replace(/{/g, '%7B')
.replace(/}/g, '%7D')
.replace(/</g, '%3C')
.replace(/>/g, '%3E')
return `data:image/svg+xml,${encoded}`
}
-
如果使用在 CSS 中,可利用 SASS版本3.3以上 的 三個API 對 SVG字符串做替換處理。
str_insert(string, insert, index): 從$string第$index插入字符$insert;str_index(string, substring): 返回$substring在$string中第一個位置;str_slice(string, start_at, end_at = nil): 返回從字符$string中第$start_at開始到$end_at結束的一個新字符串。
前人已有總結,可前往
https://github.com/leeenx/sass-svg/blob/master/sass-encodeuri.scss查看完整代碼。
3.2、SVG 壓縮
一般從 Sketch 導出 SVG ,冗餘代碼比較多,有條件的話建議使用 SVGO 壓縮SVG的原本體積,比如清除換行、重複空格;刪除文檔聲明;刪除註釋;刪除desc描述等等。
四、總結
SVG強大的地方在於,出其不意,炫酷,與眾不同。
無論是微信公眾號花式排版,foreignObject 標籤實現截圖,實現非比例縮放,或者 背景圖直接使用 SVG XML 格式代碼,還是上文沒有提及的路徑動畫、描邊動畫、圖形裁剪、濾鏡等等,都可以玩出新的花樣。
SVG 一個屬性可成就一篇文章,學習 SVG 可以說是在挑戰自己,歡迎加入 SVG 的學習隊列。
五、參考內容 · 推薦閱讀
三看 SVG Web 動效
URL編碼的奧秘
學習了,CSS中內聯SVG圖片有比Base64更好的形式
超級強大的SVG SMIL animation動畫詳解
詳細教你微信公眾號正文頁SVG交互開發
SVG 簡介與截圖等應用
歡迎關注凹凸實驗室博客:aotu.io
或者關注凹凸實驗室公眾號(AOTULabs),不定時推送文章:
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※南投搬家公司費用需注意的眉眉角角,別等搬了再說!
※新北清潔公司,居家、辦公、裝潢細清專業服務
※教你寫出一流的銷售文案?