作者:
劉洋(炎尋) EDAS-OAM 架構與開發負責人
鄧洪超 OAM spec maintainer
孫健波(天元) OAM spec maintainer
隨着以 K8s 為主的雲原生基礎架構遍地生根,越來越多的團隊開始基於 K8s 搭建持續部署、自助式發布體驗的應用管理平台。然而,在 K8s 交付和管理應用方面,目前還缺乏一個統一的標準,這最終促使我們與微軟聯合推出了首個雲原生應用標準定義與架構模型 – OAM。本文作者將從基本概念以及各個模塊的封裝設計與用法等角度出發來詳細解讀 OAM。
OAM 主要有三個特點:
- 開發和運維關注點分離:開發者關注業務邏輯,運維人員關注運維能力,讓不同角色更專註於領域知識和能力;
- 平台無關與高可擴展:應用定義與平台實現解耦,應用描述支持跨平台實現和可擴展性;
- 模塊化應用部署和運維特徵:應用部署和運維能力可以描述成高層抽象模塊,開發和運維可以自由組合和支持模塊化實現。
OAM 綜合考慮了在公有雲、私有雲以及邊緣雲上應用交付的解決方案,提出了通用的模型,讓各平台可以在統一的高層抽象上透出應用部署和運維能力,解決跨平台的應用交付問題。同時,OAM 以標準化的方式溝通和連接應用開發者、運維人員、應用基礎設施,讓雲原生應用交付和管理流程更加連貫、一致。
角色分類
OAM 將應用相關的人員劃分為 3 個角色:
-
應用開發:關注應用代碼開發和運行配置,是應用代碼的領域專家,應用開發完成后打包(比如鏡像)交給應用運維;
-
應用運維:關注配置和運行應用實例的生命周期,比如灰度發布、監控、報警等操作,是應用運維專家;
-
平台運維:關注應用運行平台的能力和穩定性,是底層(比如 Kubernetes 運維/優化,OS 等)的領域專家。
核心概念
OAM 包含以下核心概念:
服務組件(Component Schematics)
應用開發使用服務組件來聲明應用的屬性(配置項),運維人員定義這些屬性之後就能按照組件聲明得到運行的組件實例,組件聲明包含以下信息:
- 工作負載類型(Workload type):表明該組件運行時的工作負載依賴;
- 元數據(Metadata):面向組件用戶的一些描述性信息;
- 資源需求(Resource requirements):組件運行的最小資源需求,比如最小內存,CPU 和文件掛載需求;
- 參數(Parameters):可以被運維人員配置的參數;
- 工作負載定義(Workload definition):工作負載運行的一些定義,比如可運行包定義(ICO images, Function等)。
應用邊界(Application Scopes)
運維人員使用應用邊界將組件組成松耦合的應用,可以賦予這組組件一些共用的屬性和依賴,應用邊界聲明包含以下信息:
- 元數據(Metadata):面嚮應用邊界用戶的一些描述性信息。
- 類型(Type):邊界類型,不同類型提供不同的能力;
- 參數(Parameters):可以被運維人員配置的參數。
運維特徵(Traits)
運維人員使用運維特徵賦予組件實例特定的運維能力,比如自動擴縮容,一個 Trait 可能僅限特定的工作負載類型,它們代表了系統運維方面的特性,而不是開發的特性,比如開發者知道自己的組件是否可以擴縮容,但是運維可以決定是手動擴縮容還是自動擴縮容,特徵聲明包含以下信息:
- 元數據(Metadata):面向特徵用戶的一些描述性信息;
- 適用工作負載列表(Applies-to list):該特徵可以應用的工作負載列表;
- 屬性(Properties):可以被運維人員配置的屬性。
工作負載類型和配置(Workload types and configurations)
描述特定工作負載的底層運行時,平台需要能夠提供對應工作負載的運行時,工作負載聲明包含以下信息:
- 元數據(Metadata):面向工作負載用戶的一些描述性信息;
- 工作負載設置(Workload Setting):可以被運維人員配置的設置。
應用配置(Application configuration)
運維人員使用應用配置將組件、特徵和應用邊界的組合在一起實例化部署,應用配置聲明包含以下信息:
- 元數據(Metadata):面嚮應用配置用戶的一些描述性信息;
- 參數覆蓋(Parameter overrides):可以理解為變量定義,可以被組件、特徵、應用邊界的參數引用;
- 組件設置(Component):構成應用的全部組件都在這裏設置;
- 綁定組件的運維特徵配置(Trait Configuration):綁定的特徵列表及其參數。
OAM 認為:
一個雲原生應用由一組相互關聯但又離散獨立的組件構成,這些組件實例化在合適的運行時上,由配置來控制行為並共同協作提供統一的功能。
更加具體的說:
一個 Application 由一組 Components 構成,每個 Component 的運行時由 Workload 描述,每個 Component 可以施加 Traits 來獲取額外的運維能力,同時我們可以使用 Application scopes 將 Components 劃分到 1 或者多個應用邊界中,便於統一做配置、限制、管理。
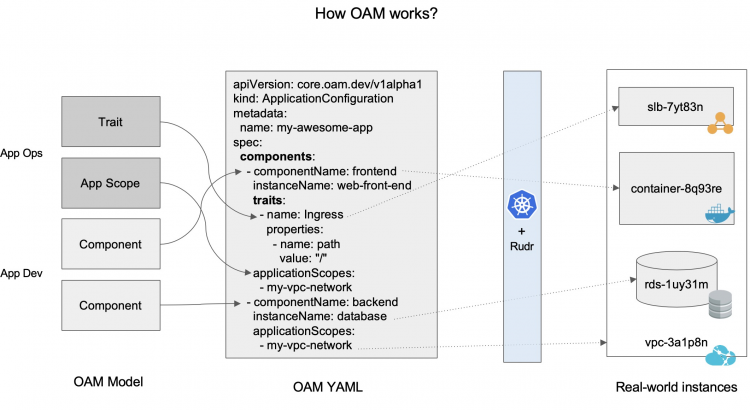
整體的運行模式如下所示:
組件、運維特徵、應用邊界通過應用配置(Application Configuration)實例化,然後再通過 OAM 的實現層翻譯為真實的資源。
怎麼用?
使用 OAM 來管理雲原生應用,其核心主要是圍繞着“四個概念,一個動作”。
四個概念
- 應用組件(包含對工作負載的依賴聲明);【開發人員關心】
- 工作負載;【平台關心】
- 運維特徵;【平台關心】
- 應用邊界;【平台關心】
一個動作
下發應用配置之後 OAM 平台將會實例化四個概念得到運行的應用。
一個 OAM 平台在對外提供 OAM 應用管理界面時,一定是預先已經準備好了“運維特徵,應用邊界”供運維人員使用,準備好了“工作負載”供開發者使用,同時開發者準備“組件”供運維人員使用。因此角色劃分就很明了:
- 開發者提供組件,使用平台的工作負載;
- 運維人員關注一個動作實例化四個概念;
- 平台方需要提供工作負載,運維特徵,應用邊界,並且託管用戶的應用組件;
例子
如何使用上面“四個概念,一個動作”來部署一個 OAM 應用呢?
我們假想一個場景,用戶的應用有兩個組件:frontend 和 backend,其中 frontend 組件需要域名訪問、自動擴縮容能力,並且 frontend 要訪問 backend,兩者應該在同一個 vpc 內,基於這個場景我們需要有:
frontend 的 workload 類型是 Server 容器服務(OAM 平台提供該工作負載):
apiVersion: core.oam.dev/v1alpha1
kind: ComponentSchematic
metadata:
name: frontend
annotations:
version: v1.0.0
description: "A simple webserver"
spec:
workloadType: core.oam.dev/v1.Server
parameters:
- name: message
description: The message to display in the web app.
type: string
value: "Hello from my app, too"
containers:
- name: web
env:
- name: MESSAGE
fromParam: message
image:
name: example/charybdis-single:latest
backend 的 workload 是 Cassandra(OAM 平台提供該工作負載):
apiVersion: core.oam.dev/v1alpha1
kind: ComponentSchematic
metadata:
name: backend
annotations:
version: v1.0.0
description: "Cassandra database"
spec:
workloadType: data.oam.dev/v1.Cassandra
parameters:
- name: maxStalenessPrefix
description: Max stale requests.
type: int
value: 100000
- name: defaultConsistencyLevel
description: The default consistency level
type: string
value: "Eventual"
workloadSettings:
- name: maxStalenessPrefix
fromParam: maxStalenessPrefix
- name: defaultConsistencyLevel
fromParam: defaultConsistencyLevel
apiVersion: core.oam.dev/v1alpha1
kind: Trait
metadata:
name: Ingress
spec:
type: core.oam.dev/v1beta1.Ingress
appliesTo:
- core.oam.dev/v1alpha1.Server
parameters:
properties: |
{
"$schema": "http://json-schema.org/draft-07/schema#",
"type": "object",
"properties": {
"host": {
"type": "string",
"description": "ingress hosts",
},
"path": {
"type": "string",
"description": "ingress path",
}
}
}
apiVersion: core.oam.dev/v1alpha1
kind: ApplicationScope
metadata:
name: network
annotations:
version: v1.0.0
description: "network boundary that a group components reside in"
spec:
type: core.oam.dev/v1.NetworkScope
allowComponentOverlap: false
parameters:
- name: network-id
description: The id of the network, e.g. vpc-id, VNet name.
type: string
required: Y
- name: subnet-ids
description: >
A comma separated list of IDs of the subnets within the network. For example, "vsw-123" or ""vsw-123,vsw-456".
There could be more than one subnet because there is a limit in the number of IPs in a subnet.
If IPs are taken up, operators need to add another subnet into this network.
type: string
required: Y
- name: internet-gateway-type
description: The type of the gateway, options are 'public', 'nat'. Empty string means no gateway.
type: string
required: N
apiVersion: core.oam.dev/v1alpha1
kind: ApplicationConfiguration
metadata:
name: my-vpc-network
spec:
variables:
- name: networkName
value: "my-vpc"
scopes:
- name: network
type: core.oam.dev/v1alpha1.Network
properties:
- name: network-id
value: "[fromVariable(networkName)]"
- name: subnet-ids
value: "my-subnet1, my-subnet2"
使用應用配置將上面的組件、邊界、特徵組合起來即可部署一個應用,這個由應用的運維人員提供:
apiVersion: core.oam.dev/v1alpha1
kind: ApplicationConfiguration
metadata:
name: custom-single-app
annotations:
version: v1.0.0
description: "Customized version of single-app"
spec:
variables:
- name: message
value: "Well hello there"
- name: domainName
value: "www.example.com"
components:
- componentName: frontend
instanceName: web-front-end
parameterValues:
- name: message
value: "[fromVariable(message)]"
traits:
- name: Ingress
properties:
- name: host
value: "[fromVaraible(domainName)]"
- name: path
value: "/"
applicationScopes:
- my-vpc-network
- componentName: backend
instanceName: database
applicationScopes:
- my-vpc-network
通過以上完整的使用流程我們可以看到:應用配置是真正部署應用的起點,在使用該配置的時候,對應的組件、應用邊界、特徵都要提前部署好,運維人員只需做一個組合即可。
服務組件(Component Schematic)
服務組件的意義是讓開發者聲明離散執行單元的運行時特性,可以用 JSON/YAML 格式來表示,其聲明遵循 Kubernetes API 規範,區別在於:
- 定義字段是 Kubernetes 的子集,因為 OAM 是更高的抽象;
- OAM Spec 的底層運行時可以不是 Kubernetes
下面我們來看看具體的組件聲明如何定義。
定義
頂層屬性
| 屬性 |
類型 |
必填 |
默認值 |
描述 |
| apiVersion |
string |
Y |
|
特定oam spec版本,比如core.oam.dev/v1 |
| kind |
string |
Y |
|
類型,對於組件來說就是
ComponentSchematic |
| metadata |
Metadata |
Y |
|
組件元數據 |
| spec |
Spec |
Y |
|
組件特定的定義屬性 |
Metadata
| 屬性 |
類型 |
必填 |
默認值 |
描述 |
| name |
string |
Y |
|
|
| labels |
map[string]string |
N |
|
k/v對作為組件的lebels |
| annotations |
map[string]string |
N |
|
k/v對作為組件的描述信息 |
Spec
| 屬性 |
類型 |
必填 |
默認值 |
描述 |
| parameters |
[]Parameter |
N |
|
組件的可配置項 |
| workloadType |
string |
Y |
|
簡明語義化的組件運行時描述,以K8s為例就是指定底層使用StatefulSet還是Deployment這樣 |
| osType |
string |
N |
linux |
組件容器運行時依賴的操作系統類型,可選值:
– linux
– windows |
| arch |
string |
N |
amd64 |
組件容器運行時依賴的CPU架構,可選值:
– i386
– amd64
– arm
– arm64 |
| containers |
[]Container |
N |
|
實現組件的OCI容器們 |
| workloadSettings |
[]WorkloadSettings |
N |
|
需要傳給工作負載運行時的非容器配置聲明 |
上面的 workloadType 後面會有詳細說明,這裏簡要來說就是開發者可以指定該 field 告訴運行時該組件如何被執行。工作負載命名的規範是 GROUP/VERSION.KIND,和 K8s 資源類型坐標一致,比如:
- core.oam.dev/v1alpha1.Singleton
core.oam.dev 表示是 oam 內置的分組,oam 內置的表示任何 OAM 實現都支持該類型的工作負載,v1alpha1 表示依舊是 alpha 狀態,類型是 Singleton,這表示運行時應該只運行一個組件實例,無論誰提供。
- alibabacloud.com/v1.Function
alibabacloud.com 表示該對象是一個運營商特定的實現,不一定所有平台都實現,版本 v1 表示實現已經穩定,類型是 Function 表示運行時是 Alibaba Functions 提供的。
- streams.oam.io/v1beta2.Kafka
表示該對象是一個第三方組織實現,不一定所有平台都實現,版本 v1beta2 表示實現已經趨於穩定,類型是 Kafka 表示運行時是開源組件 Kafka 提供的。
工作負載主要分為兩類:
屬於 core.oam.dev 分組,所有對象都需要 oam 平台實現,都是容器運行時,該 Spec 目前定義了如下核心工作負載類型:
| 名字 |
類型 |
是否對外提供服務 |
是否可以多副本運行 |
是否常駐 |
| Server |
core.oam.dev/v1alpha1.Server |
Y |
Y |
Y |
| Singleton Server |
core.oam.dev/v1alpha1.SingletonServer |
Y |
N |
Y |
| Worker |
core.oam.dev/v1alpha1.Worker |
N |
Y |
Y |
Singleton
Worker |
core.oam.dev/v1alpha1.SingletonWorker |
N |
N |
Y |
| Task |
core.oam.dev/v1alpha1.Task |
N |
Y |
N |
| Singleton Task |
core.oam.dev/v1alpha1.SingletonTask |
N |
N |
N |
-
Server:定義了容器運行時可以運行 0 或多個容器實例,該工作負載提供了冗餘的可擴縮容的多副本常駐服務,在 K8s 平台可以使用 Deployment 或者 Statefulset 加上 Service 來實現;
-
Singleton Server:定義了容器運行時只能運行一個容器實例,該工作負載提供了無法冗餘的單副本常駐服務,在 K8s 平台可以使用副本為 1 的 Statefulset 加上 Service 來實現;
-
Worker:定義了容器運行時可以運行 0 或多個容器實例,該工作負載提供了冗餘的可擴縮容的多副本常駐實例但是不提供服務,在 K8s 平台可以使用 Deployment 或者 Statefulset 來實現;
-
Singleton Worker:定義了容器運行時只能運行一個容器實例,該工作負載提供了無法冗餘的單副本常駐實例但是不提供服務,在 K8s 平台可以使用副本為 1 的 Statefulset 來實現;
-
Task:定義了非常駐可冗餘的容器運行時,運行完就退出,可以賦予擴縮容特性,在 K8s 平台可以使用 Job 來實現;
-
Singleton Task:定義了非常駐非冗餘的容器運行時,運行完就退出,在 K8s 平台可以使用 completions=1 的 Job 來實現。
核心工作負載必須給定 container 部分,實現核心工作負載的 OAM 平台必須不依賴 workloadSettings。
擴展工作負載類型是平台運行時特定的,由各個 OAM 平台自定提供,當前版本的 Spec 不支持用戶自定義工作負載類型,只能是平台方提供,擴展工作負載可以使用非容器運行時,workloadSettings 的目的就是為了擴展工作負載類型的配置。
工作負載的定義是包羅萬象的,他允許任何部署的服務作為工作負載,無論是容器化還是虛擬機,基於此,我們可以將緩存,數據庫,消息隊列都作為工作負載,如果組件指定的工作負載在平台沒有提供,應該快速失敗將信息返回給用戶。
除了 WorkloadType,可以看到組件 Spec 內嵌了 3 種結構體,下面來看看它們的定義:
1.Parameter
定義了該組件的所有可配置項,其定義如下:
| 屬性 |
類型 |
必填 |
默認值 |
描述 |
| name |
string |
Y |
|
|
| description |
string |
N |
|
組件的簡短描述 |
| type |
string |
Y |
|
參數類型,JSON定義的boolean, number, … |
| required |
boolean |
N |
false |
參數值是否必須提供 |
| default |
同上面的type |
N |
|
參數的默認值 |
2.Container
| 屬性 |
類型 |
必填 |
默認值 |
描述 |
| name |
string |
Y |
|
容器名字,在組件內必須唯一 |
| iamge |
string |
Y |
|
鏡像地址 |
| resources |
Resources |
Y |
|
鏡像運行最小資源需求 |
| env |
[]Env |
N |
|
環境變量 |
| ports |
[]Port |
N |
|
暴露端口 |
| livenessProde |
HealthProbe |
N |
|
健康狀態檢查指令 |
| readinessProbe |
HealthProbe |
N |
|
流量可服務狀態檢查指令 |
| cmd |
[]string |
N |
|
容器運行入口 |
| args |
[]string |
N |
|
容器運行參數 |
| config |
[]ConfigFile |
N |
|
容器內可以訪問的配置文件 |
| imagePullSecrets |
string |
N |
|
拉取容器的憑證 |
其中 Resources 的定義如下:
| 屬性 |
類型 |
必填 |
默認值 |
描述 |
| cpu |
CPU |
Y |
|
容器運行所需的cpu資源 |
| memory |
Memory |
Y |
|
容器運行所需的memory資源 |
| gpu |
GPU |
N |
|
容器運行所需的gpu資源 |
| volumes |
[]Volume |
N |
|
容器運行所需的存儲資源 |
| extended |
[]ExtendedResource |
N |
|
容器運行所需的外部資源 |
其中 CPU/Memory/GPU 都是數值型,不贅述,Volume 的定義如下:
| 屬性 |
類型 |
必填 |
默認值 |
描述 |
| name |
string |
Y |
|
數據卷的名字,引用的時候使用 |
| mountPath |
string |
Y |
|
實際在文件系統的掛載路徑 |
| accessMode |
string |
N |
RW |
訪問模式,RW或RO |
| sharingPolicy |
string |
N |
Exclusive |
掛載共享策略,Exclusive或者Shared |
| disk |
Disk |
N |
|
該數據卷使用底層磁盤資源的屬性 |
Disk 指定存儲是否需要持久化,最小的空間需求,定義如下:
| 屬性 |
類型 |
必填 |
默認值 |
描述 |
| required |
string |
Y |
|
最小磁盤大小需求 |
| ephemeral |
boolean |
N |
|
是否需要掛載外部磁盤 |
ExtendedResource 描述特定實現的資源需求,比如 OAM 運行時平台可能提供特殊的硬件,這個字段允許容器聲明需要這個特定的 offering:
| 屬性 |
類型 |
必填 |
默認值 |
描述 |
| required |
string |
Y |
|
需要的條件 |
| name |
string |
Y |
|
資源名字,比如GV.K |
Env,Port,HealthProbe 和 K8s 類似,這裏不再贅述。
3.WorkloadSetting
工作負載的附加配置,用於非容器運行時(當然,也可以用於容器運行時工作負載的附加字段)。
| 屬性 |
類型 |
必填 |
默認值 |
描述 |
| name |
string |
Y |
|
參數名 |
| type |
string |
N |
string |
參數類型,用於實現的hint |
| value |
any |
N |
|
參數值,如果沒有fromParam則用該值 |
| fromParam |
string |
N |
|
參數引用,覆蓋value |
這組配置會傳給運行時,一個運行時可以返回錯誤,如果特定的限制沒有滿足,比如:
- 丟失了期望的 k/v 對;
- 不認識的 k/v 對;
例子
使用核心工作負載 Server 的組件聲明
apiVersion: core.oam.dev/v1alpha1
kind: ComponentSchematic
metadata:
name: frontend
annotations:
version: v1.0.0
description: >
Sample component schematic that describes the administrative interface for our Twitter bot.
spec:
workloadType: core.oam.dev/v1alpha1.Server
osType: linux
parameters:
- name: username
description: Basic auth username for accessing the administrative interface
type: string
required: true
- name: password
description: Basic auth password for accessing the administrative interface
type: string
required: true
- name: backend-address
description: Host name or IP of the backend
type: string
required: true
containers:
- name: my-twitter-bot-frontend
image:
name: example/my-twitter-bot-frontend:1.0.0
digest: sha256:6c3c624b58dbbcd3c0dd82b4c53f04194d1247c6eebdaab7c610cf7d66709b3b
resources:
cpu:
required: 1.0
memory:
required: 100MB
ports:
- name: http
value: 8080
env:
- name: USERNAME
fromParam: 'username'
- name: PASSWORD
fromParam: 'password'
- name: BACKEND_ADDRESS
fromParam: 'backend-address'
livenessProbe:
httpGet:
port: 8080
path: /healthz
readinessProbe:
httpGet:
port: 8080
path: /healthz
使用擴展工作負載的組件聲明
apiVersion: core.oam.dev/v1alpha1
kind: ComponentSchematic
metadata:
name: alibabacloudFunctions
annotations:
version: v1.0.0
description: "Extended workflow example"
spec:
workloadType: alibabacloud.com/v1.Function
parameters:
- name: github-token
description: GitHub API session key
type: string
required: true
workloadSettings:
- name: source
value: git://git.example.com/function/myfunction.git
- name: github_token
fromParam: github-token
總結
組件聲明是由開發者或者 OAM 平台給出,透出應用運行的可配置項、依賴的平台和工作負載,可以看成是一個聲明了運行環境的函數定義,運維人員填寫函數參數之後,組件就會按照聲明的功能運行起來。
應用邊界(Application scopes)
應用邊界通過提供不同形式的應用邊界以及共有的分組行為來將組件組成邏輯的應用,應用邊界具備以下通用的特徵:
- 應用邊界應該描述該組組件實例的共有行為和元數據;
- 一個組件可以同時部署到多個不同類型的應用邊界中;
- 應用邊界類型可以決定組件是否可以部署到多個相同的應用邊界類型實例;
- 應用邊界可以用於不同組件分組以及不同 infra 能力之間的連接機制,比如 networking 或者外部能力(如驗證服務);
下圖說明了組件可以屬於多個重疊的應用分組,最終創建出不同的應用邊界。
上圖有兩種應用邊界類型:Network 與 Health,有四個組件分佈在不同的應用邊界實例中:
- A、B、C 三個組件部署到了相同的 Health scope,該 scope 會收集所有屬於這個邊界的組件狀態和信息,可以給 Traits 或者其他組件使用;
- 組件 A 和 B、C、D 的網絡邊界是隔離的,這允許 infra 運維提供不同的 SDN 設置,控制不同分組的流量流入/流出規則;
類型
主要是有兩種應用邊界類型:
核心應用邊界類型
定義基本運行時行為的分組結構,它們擁有如下特徵:
- 必須是 core.oam.dev 命名空間;
- 必須被全部實現;
- 核心工作負載類型實例必須部署到所有核心應用邊界類型實例中;
- 運行時必須為每種應用邊界類型提供默認的應用邊界實例;
- 運行時如果組件實例沒有指定特定的應用邊界,必須將該組件實例部署到默認應用邊界實例上;
當前 Spec 定義的應用邊界類型有:
| Name |
Type |
Description |
| Network |
core.oam.dev/v1alpha1.Network |
該邊界將組件組織到一個子網邊界並且定義統一的運行時網絡模型,以及infra網絡描述的定義和規則 |
| Health |
core.oam.dev/v1alpha1.Health |
該邊界將組件組織到一個聚合的健康組中,信息可以用於回滾和升級 |
擴展應用邊界類型
對於運行時來說是 optional 的,可以自定義。
定義
apiVersion,kind,metadata 和前面組件一致,不贅述,主要描述 Spec:
| 屬性 |
類型 |
必填 |
默認值 |
描述 |
| type |
string |
Y |
|
應用邊界類型 |
| allowComponentOverlap |
bool |
Y |
|
決定是否允許一個組件同時出現在多個該類型應用邊界實例中 |
| parameters |
[]Parameter |
N |
|
邊界的可配置參數 |
例子
Network scope(core)
用於將組件劃分到一個網絡或者 SDN 中,網絡本身必須被 infra 定義和運維,也可以被流量管理 Traits 查詢,用於發現 service mesh 的可發現邊界或者 API 網關的 API 邊界:
apiVersion: core.oam.dev/v1alpha1
kind: ApplicationScope
metadata:
name: network
annotations:
version: v1.0.0
description: "network boundary that a group components reside in"
spec:
type: core.oam.dev/v1.NetworkScope
allowComponentOverlap: false
parameters:
- name: network-id
description: The id of the network, e.g. vpc-id, VNet name.
type: string
required: Y
- name: subnet-id
description: The id of the subnet within the network.
type: string
required: Y
- name: internet-gateway-type
description: The type of the gateway, options are 'public', 'nat'. Empty string means no gateway.
type: string
required: N
Health scope(core)
用於聚合組件的健康狀態,可以設計的參數有健康閾值(超過該閾值的組件不健康則認為整個邊界不健康),健康邊界實例本身不會用健康狀態做任何操作,它只是分組健康聚合器,其信息可以被查詢並用於其他地方,比如:
- 應用的變更 Traits 可以監控健康狀態來決定何時回滾;
- 監控 Traits 可以監控健康狀態來觸發報警。
apiVersion: core.oam.dev/v1alpha1
kind: ApplicationScope
metadata:
name: health
annotations:
version: v1.0.0
description: "aggregated health state for a group of components."
spec:
type: core.oam.dev/v1alpha1.HealthScope
allowComponentOverlap: true
parameters:
- name: probe-method
description: The method to probe the components, e.g. 'httpGet'.
type: string
required: true
- name: probe-endpoint
description: The endpoint to probe from the components, e.g. '/v1/health'.
type: string
required: true
- name: probe-timeout
description: The amount of time in seconds to wait when receiving a response before marked failure.
type: integer
required: false
- name: probe-interval
description: The amount of time in seconds between probing tries.
type: integer
required: false
- name: failure-rate-threshold
description: If the rate of failure of total probe results is above this threshold, declared 'failed'.
type: double
required: false
- name: healthy-rate-threshold
description: If the rate of healthy of total probe results is above this threshold, declared 'healthy'.
type: double
required: false
- name: health-threshold-percentage
description: The % of healthy components required to upgrade scope
type: double
required: false
- name: required-healthy-components
description: Comma-separated list of names of the components required to be healthy for the scope to be health.
type: []string
required: false
resource quota scope(extended)
限制分組內所有組件的資源使用總量上限。
apiVersion: core.oam.dev/v1alpha1
kind: ApplicationScope
metadata:
name: myResourceQuotas
annotations:
version: v1.0.0
description: "The production configuration for Corp CMS"
spec:
type: resources.oam.dev/v1.ResourceQuotaScope
allowComponentOverlap: false
parameters:
- name: CPU
description: maximum CPU to be consumed by this scope
type: double
required: Y
- name: Memory
description: maximum memory to be consumed by this scope
type: double
required: Y
總結
應用邊界聲明由 OAM 平台提供,透出應用邊界實例運行的可配置項,可以看成是一個函數定義,運維人員或者平台填寫函數參數之後,應用邊界就會按照聲明的功能運行起來,對該邊界內的組件們起作用。
應用特徵(Traits)
OAM Spec 的實現平台應該提供 Traits 給組件工作負載增強運維操作,一個 Trait 是一種自由的運行時,增強工作負載提供額外的功能,比如流量路由規則、自動擴縮容規則、升級策略等,這讓應用運維具備根據需求配置組件,不需要開發者參与的能力。一個獨立的 Trait 可以綁定 1 或多個工作負載類型,它可以聲明哪些工作負載類型才能使用該Trait。
規則
- 目前並沒有機制來显示約定組件的多個 Traits 組合,也就是一個組件應用了 Trait A 無法要求 Trait B 必須應用於該組件,如果在運行時發生存在 Trait A 但是 Trait B 不存在,應該標記 Trait A 失敗;
- Traits 應該按照定義的順序施加到組件上;
- 應用部署只有當所有組件和其 Traits 都正常運行起來才能標記為部署成功;
- OAM 平台應該支持組件施加多個 Traits,這些 Traits 可能是相同的類型;
- OAM 對 Trait 的實現沒有任何限制,Trait 一般作用於應用的安裝和升級時;
分類
目前 Traits 主要分為三類:
- Core Traits: core Traits 屬於 core.oam.dev 分組,是一些必要的運維特徵,所有 OAM 平台必須實現;
- Standard Traits: standard Traits 屬於 standard.oam.dev 分組裡面,是一些常用的運維特徵,推薦 OAM 平台實現;
- Extensions Traits: extension Traits 是自定義 Traits,其分組也是自定義,是平台特定的運維特徵(通常是特定 OAM 平台差異性)的體現。
定義
apiVersion,kind,metadata 和前面組件一致,不贅述,主要描述 Spec:
| 屬性 |
類型 |
必填 |
默認值 |
描述 |
| appliesTo |
[]string |
N |
[“*”] |
該Trait可以應用的工作負載類型 |
| properties |
[]Properties |
N |
|
Trait的可配置參數,使用JSON Schema來表達。 |
例子
Manual Scaler(core)
apiVersion: core.oam.dev/v1alpha1
kind: Trait
metadata:
name: ManualScaler
annotations:
version: v1.0.0
description: "Allow operators to manually scale a workloads that allow multiple replicas."
spec:
appliesTo:
- core.oam.dev/v1alpha1.Server
- core.oam.dev/v1alpha1.Worker
- core.oam.dev/v1alpha1.Task
properties: |
{
"$schema": "http://json-schema.org/draft-07/schema#",
"type": "object",
"required": ["replicaCount],
"properties": {
"replicaCount": {
"type": "integer",
"description": "the target number of replicas to scale a component to.",
"minimum": 0
}
}
}
上面是一個手動擴縮容服務的 Trait,只有一個參數就是 replicaCount。
總結
應用特徵聲明由 OAM 平台提供,透出應用特徵的可配置項,標明了可作用於的工作負載,可以看成函數定義,運維人員或者平台填寫實參之後,應用特徵就會按照聲明的功能運行起來,對綁定的組件起作用。
應用配置(Application Configuration)
應用配置主要是描述應用如何被部署的,一個組件可以部署到任意的運行時,我們稱一個組件的一次部署為實例,每次組件部署的時候必須有應用配置。
應用配置由應用運維管理,提供當前組件實例的信息:
- 特定組件的基本信息:名字、版本、描述;
- 組件及其相關組件定義 parameters 的賦值;
- 組件要施加的 Trait 以及 Trait 的配置。
概念
實例與升級(Instances and upgrades)
一個實例是組件的可追溯部署,當組件部署時創建,後續該組件的升級都是修改該實例,回滾/重新部署都屬於升級,實例都會有名字方便引用。當一個實例首次創建時,處於初始發行 (release) 狀態,每次升級操作之後,一個新的發行就會創建。
發行(Releases)
任何對組件本身或者其配置的變更都會創建一個新的發行,一個發行就是應用配置以及它對組件、應用特徵、應用邊界的定義,當一個發行被部署,對應的組件、應用特徵和應用邊界也會被部署。
基於該定義,平台需要保證以下變更語義:
- 如果新的發行包含了舊發行不存在的組件,平台需要創建該組件;
- 如果新的發行不包含舊發行存在的組件,平台需要刪除該組件;
- 應用特徵和應用邊界與組件的變更語義一致。
運行時與應用配置(Runtime and Application Configuration)
一個組件可以部署到多個不同的運行時,在每個運行時中應用配置的實例與應用配置之間是 1:1 的關係,應用配置由應用運維管理,包含 3 個主要部分:
定義
apiVersion,kind,metadata 和前面組件一致,不贅述,主要描述 Spec:
| 屬性 |
類型 |
必填 |
默認值 |
描述 |
| variables |
[]Variable |
N |
|
可以在參數值和屬性中引用的變量 |
| scopes |
[]Scope |
N |
|
應用邊界定義 |
| components |
[]Component |
N |
|
組件實例定義 |
variables 就是一個 k/v 對,一個集中的地方定義運維的變量,在運維配置的其他地方都可以用 fromVariable(VARNAME) 引用:
| 屬性 |
類型 |
必填 |
默認值 |
描述 |
| name |
string |
Y |
|
變量名字 |
| value |
string |
Y |
|
標量值 |
scopes 定義該運維配置將要創建的應用邊界,其定義為:
| 屬性 |
類型 |
必填 |
默認值 |
描述 |
| name |
string |
Y |
|
應用邊界名字 |
| type |
string |
Y |
|
應用邊界的GROUP/VERSION.KIND |
| properties |
Properties |
N |
|
覆蓋邊界的參數 |
components 是組件實例定義,而不是組件定義:
| 屬性 |
類型 |
必填 |
默認值 |
描述 |
| componentName |
string |
Y |
|
組件名 |
| instanceName |
string |
Y |
|
組件實例名 |
| parameterValues |
[]ParameterValue |
N |
|
覆蓋組件的參數 |
| Traits |
[]Trait |
N |
|
指定組件實例綁定的Traits |
| applicationScopes |
[]string |
N |
|
指定組件運行的應用邊界 |
Trait 在這裏的定義是:
| 屬性 |
類型 |
必填 |
默認值 |
描述 |
| name |
string |
Y |
|
Trait實例名 |
| properties |
Properties |
N |
|
覆蓋Trait的參數 |
例子
apiVersion: core.oam.dev/v1alpha1
kind: ApplicationConfiguration
metadata:
name: my-app-deployment
annotations:
version: v1.0.0
description: "Description of this deployment"
spec:
variables:
- name: VAR_NAME
value: SUPPLIED_VALUE
scopes:
- name: core.oam.dev/v1alpha1.Network
parameterValues:
- name: PARAM_NAME
value: SUPPLIED_VALUE
components:
- componentName: my-web-app-component
instanceName: my-app-frontent
parameterValues:
- name: PARAMETER_NAME
value: SUPPLIED_VALUE
- name: ANOTHER_PARAMETER
value: "[fromVariable(VAR_NAME)]"
traits:
- name: Ingress
properties:
CUSTOM_OBJECT:
DATA: "[fromVariable(VAR_NAME)]"
總結
應用配置定義由運維人員或者 OAM 平台提供,描述應用的部署,可以看成是一個函數調用,運維人員或者 OAM 平台填寫實參之後,調用之前定義的組件、應用特徵、應用邊界等函數,這些實例一起作用對外提供應用服務。
工作負載類型(Workload Types)
Workload 類型和 Trait 一樣由平台提供,所以用戶可以查看平台提供哪些工作負載,對於平台用戶來說工作負載類型無法擴展,只能由平台開發者擴展提供,因此平台一定不允許用戶創建自定義的工作負載類型。
定義
apiVersion,kind,metadata 和前面組件類似,不贅述,這裏主要描述 Spec,定義組件如何使用工作負載類型,除此之外暴露了底層工作負載運行時的可配置參數:
| 屬性 |
類型 |
必填 |
默認值 |
描述 |
| group |
string |
Y |
|
該工作負載類型所屬的group |
| names |
Names |
Y |
|
該工作負載類型的關聯名字信息 |
| settings |
[]Setting |
N |
|
該工作負載的設置選項 |
Names 就是描述了對應類型的不同形式名字引用:
| 屬性 |
類型 |
必填 |
默認值 |
描述 |
| kind |
string |
Y |
|
工作負載類型的正確引用名字,比如Singleton |
| singular |
string |
N |
|
單數形式的可讀名字,比如singleton |
| plural |
string |
N |
|
複數形式的可讀名字,比如singletons |
Setting 描述工作負載可配置部分,類似前面組件的 Parameters,都是 schema:
| 屬性 |
類型 |
必填 |
默認值 |
描述 |
| name |
string |
Y |
|
配置名,每個workload類型必須唯一 |
| description |
string |
N |
|
配置說明 |
| type |
string |
Y |
|
配置類型 |
| required |
bool |
N |
false |
是否必須提供 |
| default |
indicated by type |
N |
|
默認值 |
價值
通過上面的介紹,我們了解了 OAM Spec 裏面的基本概念和定義,以及如何使用它們來描述應用交付和運維流程。然而,OAM 能給我們帶來什麼樣的價值呢?我們評判一個好的架構體系,不僅是因為它在技術上更先進,更主要的是它能夠解決一些實際問題,為用戶帶來價值。所以,接下來我們將總結一下這方面的內容。
OAM 的價值要從下往上三個層面來說起。
1. 從基礎設施層面
基礎設施,指的是像 K8s 這類的提供基礎服務能力與抽象的一層服務體系。拿 K8s 來說,它提供了許多種類的基礎服務和強大的擴展能力來靈活擴展其他基礎服務。
但是,使用基礎設施的運維人員很快就發現 K8s 存在一個問題:缺乏統一的機制來註冊和管理自定義擴展能力。這些擴展能力的表達方式不夠統一,有些是 CRD、有些是 annotation、有些是 Config…
這種亂象使得基礎設施用戶不知道平台上都提供了哪些能力,不知道怎麼使用這些能力,更不知道這些能力互相之間的兼容組合關係。
OAM 提供了抽象(如 Workload/Trait 等)來統一定義和管理這些能力。有了 OAM,各平台實現就有了統一的標準規範去透出公共的或差異化的能力:公共的基礎服務像容器部署、監控、日誌、灰度發布;差異化的、高級複雜的能力像 CronHPA(周期性定時變化的強化版 HPA)。
2. 從應用運維者層面
應用運維,指的是像給應用加上網絡接入、複雜均衡、彈性伸縮、甚至是建站等運維操作。但是,運維的一個痛點就是原來這些能力並不是跨平台的:這導致在不同平台、不同環境下去部署和運維應用的操作,是不互通和不兼容的。
上面這個問題,是客戶應用、尤其是傳統 ERP 應用上雲的一大阻礙。我們做 OAM 的一個初衷,就是通過一套標準定義,讓不同的平台實現也通過統一的方式透出。我們希望:哪怕一個應用不是生在雲上、長在雲上,也能夠趕上這趟通往雲原生未來的列車,擁抱雲帶來的變化和紅利!
OAM 提供的抽象和模型,是我們通往統一、標準的應用架構的強有力工具。這些標準能力以後都會通過 OAM 輸出,讓運維人員輕易去實現跨平台部署。
3. 從應用開發者層面
應用開發,指的就是業務邏輯開發,這是業務產生價值的核心位置。
也正因如此,我們希望,應用開發者能夠專註於業務開發,而不需要關心運維細節。但是,K8s 提供的 API,並沒有很好地分離開發和運維的關注點,開發和運維之間需要來回溝通以避免產生誤解和衝突。
OAM 分離了開發和運維的關注點,很好地解決了以上問題,讓整個發布流程更加連貫、高效。
下一步
目前,OAM 已經在阿里雲 EDAS 等多個項目中進行了數月的內部落地嘗試。我們希望通過一套統一、標準的應用定義體系,承載雲應用管理項目產品與外部資源關係的高效管理體驗,並將這種體驗統一帶給了基於 Function、ECS、Kubernetes 等不同運行時的應用管理流程;通過應用特徵系統,將多個阿里雲獨有的能力進行了模塊化,大大提高了阿里雲基礎設施能力的交付效率。
經過了前一段努力的鋪墊,我們也慢慢明確了接下來的工作方向:
- 將接入更多的雲產品服務,為用戶將跨平台應用交付的能力最大化;
- 提供 OAM framework 等工具和框架,幫助新的 OAM 平台開發者去快速、簡單地搭建 OAM 服務,接入 OAM 標準;
- 推動開源生態建設,以標準化的方式幫助“應用”高效和高質量地交付到任何平台上去。
社區共建
為了能夠讓社區更加高效、健康的運轉下去,我們非常期待得到您的反饋,並與大家密切協作,針對 Kubernetes 和任意雲環境打造一個簡單、可移植、可復用的應用模型。參与方式:
- 通過 Gitter 直接參与討論:;
- 選擇釘釘掃碼進入 OAM 項目中文討論群。
(****釘釘掃碼加入交流群****)
歡迎你與我們一起共建這個全新的應用管理生態!
“ 阿里巴巴雲原生微信公眾號(ID:Alicloudnative)關注微服務、Serverless、容器、Service Mesh等技術領域、聚焦雲原生流行技術趨勢、雲原生大規模的落地實踐,做最懂雲原生開發者的技術公眾號。”
更多相關信息,請關注。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※USB CONNECTOR 掌控什麼技術要點? 帶您認識其相關發展及效能
※高價3c回收,收購空拍機,收購鏡頭,收購 MACBOOK-更多收購平台討論專區
※評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
※收購3c瘋!各款手機、筆電、相機、平板,歡迎來詢價!
※智慧手機時代的來臨,RWD網頁設計已成為網頁設計推薦首選