一、實驗目的
1. 了解離散相似法的基本原理
2. 掌握離散相似法仿真的基本過程
3. 應用離散相似法仿真非線性系統
4. MATLAB實現離散相似法的非線性系統仿真
5. 掌握SIMULINK仿真方法,應用於非線性系統的仿真,並對實驗結果進行分析比較
二、實驗原理
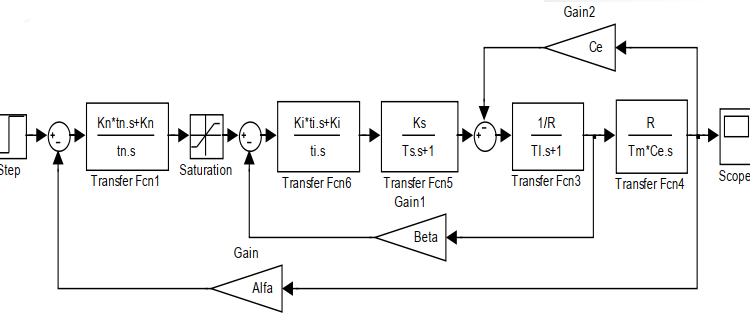
在ASR的輸出增加限幅裝置(飽和非線性,飽和界為c=8 )。 Ce=0.031,其它參數不變。輸入為單位階躍,用離散相似法求系統各環節的輸出。
要求:採用零階保持器和一階保持器離散化系統,分別完成本實驗。
1、各環節的參數:
由5個典型環節組成:
A=[0 0 1 1 0];
B=[tn ti Ts Tl Tm*Ce];
C=[Kn Ki Ks 1/R R];
D=[Kn*tn Ki*ti 0 0 0];
還有一飽和非線性環節:c=8;
2、各環節的離散化係數矩陣
3、各環節的輸入作用
(1)、u(n)可通過聯接矩陣直接求得:
u(n)=[u1(n), u2(n),…,un(n)]為各環節的輸入量, n為環節數。 Y(n)=[Y1(n), Y2(n),…,Yn(n)]為各環節的輸出量, r為外中參考輸入量。
(2)、U(n)由近似表達式求得:
(3)、u(n+1)用折線法近似求得:
4、狀態和輸出計算
(1)、一階保持器
X=FI’.*X+FIM’.*Uk+FIJ’.*Udot;
Y=FIC’.*X+FID’.*Uf;
(2)、零階保持器
X=FI’.*X+FIM’.*Uk;
Y=FIC’.*X+FID’.*Uf;
5、飽和非線性環節
看作環節1(ASR)的一部分。建立satur.m文件:
function [uo]=satur(ui,c)
if (abs(ui)<=c)
uo=ui;
elseif ( ui > c )
uo = c;
else
uo=-c;
end
end
三、實驗過程
1、新建腳本文件,命名為satur.m
function [uo]=satur(ui,c) if (abs(ui)<=c) uo=ui; elseif ( ui > c ) uo = c; else uo=-c; end end
2、新建腳本文件,命名為test3.m
完整代碼:
clc; clear; % ****** 各環節參數 ****** % Kn=26.7; tn=0.03; Ki=0.269; ti=0.067; Ks=76; Ts=0.00167; R=6.58; T1=0.018; Tm=0.25; Ce=0.031; Alpha=0.00337; Beta=0.4; A=[0 0 1 1 0]; B=[tn ti Ts T1 Tm*Ce]; C=[Kn Ki Ks 1/R R]; D=[Kn*tn Ki*ti 0 0 0]; c=8; r=1; W=[0 0 0 0 -Alpha; 1 0 0 -Beta 0; 0 1 0 0 0; 0 0 1 0 -Ce; 0 0 0 1 0]; W0=[1 0 0 0 0]'; h=0.001; t_end=0.5; t=0:h:t_end; n=length(t); % ****** 各環節離散化係數 ****** % block_num=5; for k=1:block_num if(A(k)==0) FI(k)=1; FIM(k)=h*C(k)/B(k); FIJ(k)=h*h*C(k)/B(k)/2; FIC(k)=1; FID(k)=0; if(D(k)~=0) FID(k)=D(k)/B(k); end else FI(k)=exp(-h*A(k)/B(k)); FIM(k)=(1-FI(k))*C(k)/A(k); FIJ(k)=h*C(k)/A(k)-FIM(k)*B(k)/A(k); FIC(k)=1; FID(k)=0; if(D(k)~=0) FIC(k)=C(k)/D(k)-A(k)/B(k); FID(k)=D(k)/B(k); end end end Y0=[0 0 0 0 0]'; Y=Y0; X=zeros(block_num,1); result1=Y; Uk=zeros(block_num,1); Ub=Uk; for m=1:(n-1) Ub=Uk; Uk=W*Y+W0*r; Uf=2*Uk-Ub; Udot=(Uk-Ub)/h; %****** 零階保持器 ******% X=FI'.*X+FIM'.*Uk; Y=FIC'.*X+FID'.*Uf; Y(1)=satur(Y(1),c); result1=[result1,Y]; end Y0=[0 0 0 0 0]'; Y=Y0; X=zeros(block_num,1); result2=Y; Uk=zeros(block_num,1); Ub=Uk; for m=1:(n-1) Ub=Uk; Uk=W*Y+W0*r; Uf=2*Uk-Ub; Udot=(Uk-Ub)/h; %****** 一階保持器 ******% X=FI'.*X+FIM'.*Uk + FIJ'.*Udot; Y=FIC'.*X + FID'.*Uf; Y(1)=satur(Y(1),c); result2=[result2,Y]; end
plot(t,result1(5,:),’-.’,t,result2(5,:),’–‘,t,ScopeData.signals.values,’k’);
legend(‘零階保持器’,’一階保持器’,’Simulink’);
3、在Simulink中繪製仿真圖
注意:Simulink中的變量名和工作區變量關聯方法請點擊:https://www.cnblogs.com/KaifengGuan/p/11942615.html
四、實驗結果
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※收購3c,收購IPHONE,收購蘋果電腦-詳細收購流程一覽表
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想要讓你的商品在網路上成為最夯、最多人討論的話題?
※高價收購3C產品,價格不怕你比較
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!
【其他文章推薦】
※USB CONNECTOR 掌控什麼技術要點? 帶您認識其相關發展及效能
※高價3c回收,收購空拍機,收購鏡頭,收購 MACBOOK-更多收購平台討論專區
※評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
※收購3c瘋!各款手機、筆電、相機、平板,歡迎來詢價!
※智慧手機時代的來臨,RWD網頁設計已成為網頁設計推薦首選