簡介
說到OSI參考模型,理解網絡與網絡之間的關係,不說太深入難以理解的東西,只求能最大程度上理解與使用。
參考模型是國際標準化組織(ISO)制定的一個用於計算機或通信系統間互聯的標準體系,一般稱為OSI參考模型或七層模型。
概念性的東西,先知道這些就夠了,我們先來聊一聊一個常見的一個模型。
局域網與互聯網
互聯網就是許許多多個局域網組成的,從我們最簡單的一個局域網入手,開始理解
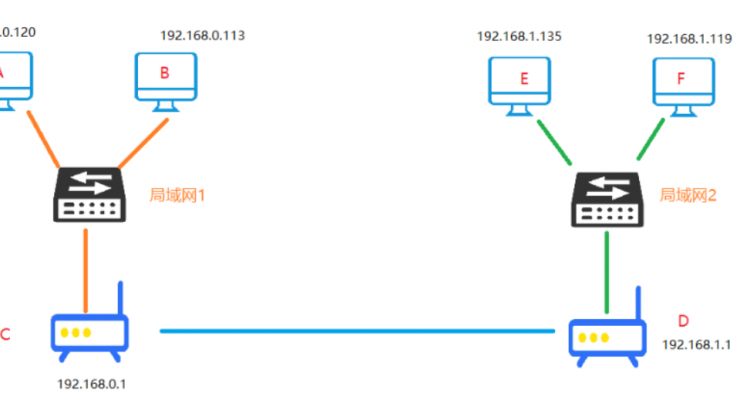
這裏舉例兩個不同的局域網,計算機用網線接入交換機、交換機連接網關路由器,另一處
也是通過相同的方式進行連接。先來了解一下OSI參考模型是如何定義這七層的
OSI 參考模型
參考:
這裏定義的七層只是為了方便我們去理解,實際上是不存在的。
簡單的了解一下這七層是如何定義的,具體的功能還是得舉例子來理解說明。
從最上層的應用層開始說起:如何一步步的封裝數據,到最後進行發送。
應用層
應用層是直接面向用戶的最高層,但它卻不是應用程序,它只是為引用程序提供服務的
就好比,我們用的電腦版微信吧!它就是一個實實在在的應用程序,假設要與一個遠方的小姐姐進行聊天會話,這個時候呢,發送一個Hello給遠方的小姐姐。
當你點擊發送的時候,其實做了很多事情,我們就來梳理一下。
需要發送的數據就是:Hello ,當然,應用層首先給這個數據拼接一個AH,這裏就是應用層的報頭,就好比是微信的一個特有的數據,就這樣先理解。
表示層
當然,我們總不能發送明文吧,將發送的文本數據進行編碼,平常我們計算機使用的萬國碼UTF-8,肯定要進行一下加密吧
表示層更關心的是所傳送數據的語法和語義,主要包括數據格式變化、與解密、與解壓等
會話層
字面意思,就可以理解出這一層表示的意思,建立一個會話,就好比使用Http訪問web的時候,都會存在一個Session 作為標識
讓服務器來區別訪問的計算機。主要功能是負責維護兩個節點之間的傳輸聯接,確保點到點傳輸不中斷,以及管理數據交換等功能。
會話層在應用進程中建立、管理和終止會話。會話層還可以通過對話控制來決定使用何種通信方式,通信或通信。會話層通過自身協議對請求與應答進行協調
傳輸層 端到端
傳輸層作為OSI參考模型中,最重要的一層,這裏主要是以端口到端口來區分。這裏涉及到兩個特別重要的協議TCP 以及UDP
一太計算機上同時運行着QQ、微信、以及瀏覽器等。發送數據報,這個數據包到底是哪個程序發出去的呢?當然要從指定的一個端口發出去
計算機的端口範圍 0-65535
0-1023 就是1024個端口為系統佔用端口
了解到這些,就該先來說說UDP協議
UDP 協議
UDP協議定義了端口,同一個主機上的每個應用程序都需要指定唯一的端口號,並且規定網絡中傳輸的數據包必須加上端口信息,當數據包到達主機以後,就可以根據端口號找到對應的應用程序了。UDP協議比較簡單,實現容易,但它沒有確認機制,數據包一旦發出,無法知道對方是否收到,因此可靠性較差,為了解決這個問題,提高網絡可靠性,TCP協議就誕生了。
參考:
一個UDP報文包含首部與數據部分,UDP首部佔用8個字節,數據部分最長長度為65535B(字節) 即 64KB
UDP協議是無連接,不保證穩定傳輸的協議,但處理速度較快,通常的音頻、視頻在傳送時候使用UDP較多。
我們這裏的例子是微信,微信能保證數據百分百到達,所以我們採用TCP來具體說明數據的封裝
TCP 協議
TCP即傳輸控制協議,是一種面向連接的、可靠的、基於字節流的通信協議。簡單來說TCP就是有確認機制的UDP協議,每發出一個數據包都要求確認,如果有一個數據包丟失,就收不到確認,發送方就必須重發這個數據包。為了保證傳輸的可靠性,TCP協議在UDP基礎之上建立了三次對話的確認機制,即在正式收發數據前,必須和對方建立可靠的連接。TCP數據包和UDP一樣,都是由首部和數據兩部分組成,唯一不同的是,TCP數據包沒有長度限制,理論上可以無限長,但是為了保證網絡的效率,通常TCP數據包的長度不會超過IP數據包的長度,以確保單個TCP數據包不必再分割
參考:
這裏只需要了解的是TCP的基本封裝過程,這裏只涉及到源端口以及目的端口,還未涉及到IP相關的內容。它和UDP協議一樣。就好像是一個改進版的
UDP協議,它能保證數據的可靠傳輸,這個特點記住即可。這裏模擬一下,我們數據的封裝過程。假設微信使用的端口是6666,目標端口就是遠方小姐姐微信
的端口,當然也是一樣的。這裏我為了理解只做簡寫
網絡層
從上面幾層來看,我們已經將微信的數據封裝成來一個TCP數據報,裡面包含來微信的端口 假設是6666,當然,就好比寫信一樣,我的信封
已經準備好勒,裏面要發送的內容我也已經準備好了,接下來就是地址了。肯定要指定這個報文我要發送到哪裡去。所以呢IP 網際協議,就誕生了。
IP 網際協議
網絡層引入了IP協議,制定了一套新地址,使得我們能夠區分兩台主機是否同屬一個網絡,這套地址就是網絡地址,也就是所謂的IP地址。IP協議將這個32位的地址分為兩部分,前面部分代表網絡地址,後面部分表示該主機在局域網中的地址。如果兩個IP地址在同一個子網內,則網絡地址一定相同。為了判斷IP地址中的網絡地址,IP協議還引入了子網掩碼,IP地址和子網掩碼通過按位與運算后就可以得到網絡地址
IP地址在這裏我們就比較好理解了。我們平時的生活中都會涉及到。一個IP指向的就是互聯網當中的一台機器或者就是一台路由器了。
我們來封裝數據。再把上面的圖拿下來,說明一下,我們要給E電腦的小姐姐發送消息。比如我是A電腦,小姐姐在另外一個網關下的E電腦
比較重要的兩個參數:
源地址:192.168.0.120
目標地址:192.168.1.135
進行封裝后的數據,這裏將源地址,告訴路由器(郵局) 發件人 就是源地址,以及收件人 也就是目標地址
ARP 協議
這裏暫時不細說這個ARP協議的內容。我們只需要知道 ARP協議是用來拿IP換MAC地址的,上面的IP協議也已經提過了,通過子網掩碼和IP地址的換算,可以得到
網絡號,網絡號就可以區別這兩個IP是否在同一個局域網內。 參考這個秒懂:
數據鏈路層
到這一層,就已經到網卡、網絡設備(交換機)的範疇了。數據鏈路層最重要的協議是以太網協議,數據鏈路層最重要的一點就是數據成幀。
以太網協議
接入以太網的設備必須包含一塊以太網網卡,也就是我們常用的網卡,一組電信號稱作是一個數據幀 、或者叫做一個數據包
網卡都包含一個全球唯一的MAC地址,發送端的和接收端的地址便是指網卡的地址,即Mac地址。
每塊網卡出廠時都被燒錄上一個實際上唯一的Mac地址,長度為48位2進制,通常由12位16進制數表示,(前六位是廠商編碼,后六位是流水線號)
進行數據鏈路層的封裝,將本機的MAC(源MAC地址) 和目標MAC地址封裝在頭部,在尾部加入DT報尾,這樣 一個數據幀算是封裝完成了!
等等。我們好像還不知道小姐姐那邊的目標MAC地址,這時候就需要用ARP協議了。我們知道ARP協議就是用來用IP來換MAC地址的。
ARP協議
上面已經簡單的了解過了,我們要和在B局域網下的E電腦進行通信,但是我們不知道它的MAC地址,於是我們發送一個ARP請求,來獲取目標的MAC地址
目標MAC 為FF:FF:FF:FF:FF:FF 表示的是廣播地址,這個數據包發出去后,所有的子網機器都會收到,收到的機器判斷目標MAC是否是自己,若不是,則直接丟棄
若是,收到報文的主機會通過單播的形式,將MAC地址回傳給我們。
通過路由協議我們可以得知,若不在一個一個子網內,則會交給路由器
路由器返回的包裏面,目標MAC就會變成路由器的MAC地址,我們拿路由器的MAC地址組裝數據鏈路層報文即可。
物理層
經過以上的每一層的層層包裝,這時候,我們已經包裝好了一個以太網數據幀,包含源MAC,目標MAC,源IP,目標IP等等一系列數據。
物理層就是將這個數據通過電信號、光信號的方式傳遞過去的,物理層一般都是我么所說的光纜以及網線這些硬件設備。
不同子網間的通信
通過上面的知識,我們已經了解到如何封裝成一個數據幀,以及一些協議的相關內容。那麼這裏就會有一個問題,同一子網、
不同子網、以及相隔很遠的兩個子網是如何進行通信的呢?以及我們撥號上網后,公網IP與內網IP是怎麼一回事呢?
同一子網通信
我們先來看一個圖,計算機A要與計算機B進行通信,這時候他們是同處於一個子網內的,這個時候就很簡單了。
按照上面的七層進行封裝數據,這裏的具體參數需要說明一下:
源IP: 0.120(簡寫)
目標IP:0.113
源MAC : A電腦的MAC
目標MAC:B電腦MAC(這裏若不知道就先發送ARP請求)
A將數據報發送出去后,交換機直接查詢目標MAC所轉發的端口,將這個數據報準確的推送到B電腦連接的那個端口即可。
不同子網通信
A電腦需要與E電腦進行通信,這時候發現A與E不在一個子網內,這時候呢,就需要路由器來協助了
源IP: A的IP
目標IP: E的IP
源MAC:A的 MAC
目標MAC: 路由器C的MAC
因為不在一個子網內,需要路由器來進行路由這個數據包,送至D路由器后,D路由器拿出數據報中目標的IP,發送ARP請求,
請求E的MAC地址,知道后,將數據報裏面的目標MAC進行替換,然後發送給E即可。
公網IP與內網IP通信的方式理解
我們在使用路由器上網后,運營商就會給我們分配一個公網IP,按照圖上的指示,C路由器在進行撥號后,就會給C路由器分配一個公網IP
我這裏假設有這樣兩個。這時候需要封裝數據,該如何封裝呢,還是以A電腦與E電腦進行通信,大家肯定會很迷惑。
這裏就需要了解一個協議:網路地址轉換協議:
以下簡稱NAT,NAT 在IPV4 之前起到很大的作用,我們現在也在用,因為IPV4 IP數量的限制,但接入互聯網的電腦又那麼多
該怎麼辦呢。就是給一個路由下分配一個公網IP,路由器下面的IP與公網IP進行一個轉換,這裏面說的轉換就是:NAT
圖中黑色的就是轉換部分,通過端口的轉換,將多個子網IP映射到公網的一個IP上面
網絡地址端口轉換(NAPT)
這種方式支持端口的映射,並允許多台主機共享一個公網IP地址。 支持端口轉換的NAT又可以分為兩類:源地址轉換和目的地址轉換。前一種情形下發起連接的計算機的IP地址將會被重寫,使得內網主機發出的數據包能夠到達外網主機。后一種情況下被連接計算機的IP地址將被重寫,使得外網主機發出的數據包能夠到達內網主機。實際上,以上兩種方式通常會一起被使用以支持雙向通信。 還是舉例,這時候,我們的A電腦需要與E電腦進行通信,E電腦在廣東省,他們撥號后,都會分配一個公網IP,並且已經在路由器裏面完成了NAT映射,
源IP: A電腦IP
目標IP: E電腦映射后的公網IP
源MAC :A電腦MAC
目標MAC : 本地路由器MAC地址 封裝完成后,將數據報送到C路由器,路由器通過映射表,將源IP進行一個替換
替換后,交給互聯網上的路由器進行數據報的轉發,這就好像發快遞時候一樣,經過一系列的中轉站,到達目的路由。
到達D路由后,D路由將數據報中的目標地址也進行一個轉換,這個地址是可以相互轉的。現在就是公網映射轉到本機IP
轉換后就輕鬆了。按照ARP請求到E機器的MAC地址,然後發報即可。
小結
以上內容皆是自己查看一些博主的總結,通過學習后,能夠加深自己對OIS模型、以及TCP、IP、ARP
這些非常重要的協議的一個認識。以及了解到不同層級下面。兩台電腦如何完成一個通行。這裏講的比較淺,
互聯網的奧妙不是那麼容易就可以理解透的。還是那句,不要停止學習的腳步。就好
參考:
- ARP請求
- 不同子網內兩台機器的通信方式
- OSI 參考模型
- 內網端口與外網端口的理解
- 網絡地址轉換協議:
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包"嚨底家"
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整