前言
- Android View 的 事件處理在我們的編程中,可謂是無處不在了。但對於大多數人而言,一直都是簡單的使用,對其原理缺乏深入地認識。
- 學 Android 有一段時間了,最近發現,很多基礎知識開始有些遺忘了,所以從新複習了 View 的事件分發。特地整理成了這篇文章分享給大家。
- 本文不難,可以作為大家茶餘飯後的休閑。
祝大家閱讀愉快!
方便大家學習,我在 GitHub 上建立個 倉庫
-
倉庫內容與博客同步更新。由於我在
稀土掘金簡書CSDN博客園等站點,都有新內容發布。所以大家可以直接關注該倉庫,即使獲得精彩內容 -
倉庫地址:
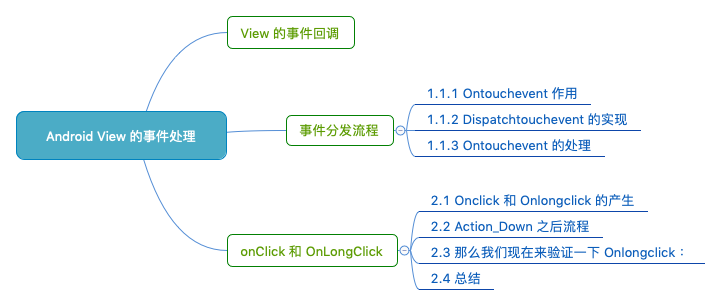
一、View 的事件回調
- 我們結合源碼看看
View的事件分發是個怎樣的過程,首先我們建立一個類MyButton類繼承AppCompatButton用於測試:
public class MyButton extends AppCompatButton {
private final String TAG = "DeBugMyButton";
public MyButton(Context context) {
super(context);
}
public MyButton(Context context, AttributeSet attrs) {
super(context, attrs);
}
public MyButton(Context context, AttributeSet attrs, int defStyleAttr) {
super(context, attrs, defStyleAttr);
}
}1.1 事件分發流程
- 我們都知道有一個方法叫做
public boolean dispatchTouchEvent(MotionEvent event)。首先我們要知道,對於我們這個自定義控件,他的觸摸事件都是從我們dispatchTouchEvent這個方法開始往下去分發的。所以可以說:這個方法是一個入口方法。
1.1.1 onTouchEvent 作用
- 現在我們重寫該方法和另一個方法:
onTouchEvent,並且打印一行日誌:
@Override
public boolean dispatchTouchEvent(MotionEvent event) {
Log.d(TAG, "----on dispatch Touch Event----");
return super.dispatchTouchEvent(event);
}
@Override
public boolean onTouchEvent(MotionEvent event) {
switch (event.getAction()) {
case MotionEvent.ACTION_DOWN:
Log.d(TAG, "----on touch event----");
}
return super.onTouchEvent(event);
}- 然後我們在
MainActivity中,設置一個實例化一個MyButton控件對象用於測試,並且給他添加一個onClickListenter和setOnTouchListener
public class MainActivity extends AppCompatActivity {
private final String TAG = "DeBugMainActivity";
/**
* 自定義控件 MyButton
*/
private MyButton mMyButton;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
iniView();
}
/**
* 實例化控件
*/
private void iniView() {
mMyButton = findViewById(R.id.my_button);
mMyButton.setOnTouchListener(new View.OnTouchListener() {
@Override
public boolean onTouch(View v, MotionEvent event) {
switch (event.getAction()) {
case MotionEvent.ACTION_DOWN:
Log.d(TAG, "----on touch----");
break;
default:
break;
}
return false;
}
});
mMyButton.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
Log.d(TAG, "----on click----");
}
});
}
}- 然後我們運行這個
Demo,點擊MyButton按鈕,會的到如下日誌:
-
我們可以看到首先回調了這個
dispatchTouchEvent,然後是它的監聽器OnTouch,接着是它的onTouchEvent,最後又執行了dispatchTouchEvent,那麼這是為什麼呢? -
這是因為我們這兒只監聽了
ACTION_DOWN而當手指抬起時它同樣還回去回調dispatchTouchEvent,最後我們打印OnClick的回調。 -
總結一下就是:
dispatchTouchEvent->setOnTouchListener->onTouchEvent->setOnClickListener -
說明我們
setOnClickListener是通過onTouchEvent處理,產生了OnClick。一會我們再來看看其中的原理。 -
既然說
dispatchTouchEvent像一個入口,就先讓我們來看下它是怎麼處理和操作的: 首先,既然我們調用了super.dispatchTouchEvent(event),那麼我們就來看看它父類中是怎麼實現該方法的。不信的是,它的父類AppCompatButton也沒有實現該方法 ,最後經過層層搜尋,我們發現這個方法是屬於View的方法。
1.1.2 dispatchTouchEvent 的實現
- 那麼現在我們來看看
View的dispatchTouchEvent怎麼實現的:
public boolean dispatchTouchEvent(MotionEvent event) {
......
//noinspection SimplifiableIfStatement
ListenerInfo li = mListenerInfo;
if (li != null && li.mOnTouchListener != null
&& (mViewFlags & ENABLED_MASK) == ENABLED
&& li.mOnTouchListener.onTouch(this, event)) {
result = true;
}
if (!result && onTouchEvent(event)) {
result = true;
}
}
if (!result && mInputEventConsistencyVerifier != null) {
mInputEventConsistencyVerifier.onUnhandledEvent(event, 0);
}
// Clean up after nested scrolls if this is the end of a gesture;
// also cancel it if we tried an ACTION_DOWN but we didn't want the rest
// of the gesture.
if (actionMasked == MotionEvent.ACTION_UP ||
actionMasked == MotionEvent.ACTION_CANCEL ||
(actionMasked == MotionEvent.ACTION_DOWN && !result)) {
stopNestedScroll();
}
return result;
}- 在
dispatchTouchEvent中,我們可以發現下面這樣一個代碼塊
if (li != null && li.mOnTouchListener != null
&& (mViewFlags & ENABLED_MASK) == ENABLED
&& li.mOnTouchListener.onTouch(this, event)) {
result = true;
}-
不難看出:如果執行了這個代碼段,那麼後面的方法就不會執行了,並且
dispatchTouchEvent會返回true。我們再仔細觀察下其中的條件:在if條件中我們發現:只有當其滿足li.mOnTouchListener != null && (mViewFlags & ENABLED_MASK) == ENABLED && li.mOnTouchListener.onTouch(this, event))時才會執行if內的操作 -
經過上面分析,我們可以知道:
onTouch事件必須返回true時,才會執行該方法塊。那麼我們就回到MainActivity中。我們發現setOnTouchListener的onTouch默認返回值是false( 不滿足返回值為true), 這就表明他會繼續去執行下一個代碼塊:
if (!result && onTouchEvent(event)) {
result = true;
}-
執行這個
if語句的過程中。首先調用了onTouchEvent方法。這就解釋了,為什麼它先執行了mOnTouchListener,然後再執行onTouchEvent。 -
現在我們就可以總結一下:首先我們回調了
dispatchTouchEvent,然後回調OnTouchListener。這個時候,如果TouchListener沒有return true,那麼就會接着去運行onTouchEvent( 當然,如果return true後面的層級就不會執行了 。一句話說就是:到那個層級return true那麼哪個層級就消費掉了這個事件 )。
1.1.3 onTouchEvent 的處理
- 同時我們還有一個結果:我們
onClick( 包括我們的onLongClick) 是來自於我們onTouchEvent這個方法的處理。那麼下面我們就來看看View中是怎麼處理onTouchEvent的:
public boolean onTouchEvent(MotionEvent event) {
。。。
if (clickable || (viewFlags & TOOLTIP) == TOOLTIP) {
switch (action) {
case MotionEvent.ACTION_UP:
。。。
break;
case MotionEvent.ACTION_DOWN:
if (event.getSource() == InputDevice.SOURCE_TOUCHSCREEN) {
mPrivateFlags3 |= PFLAG3_FINGER_DOWN;
}
mHasPerformedLongPress = false;
if (!clickable) {
checkForLongClick(0, x, y);
break;
}
if (performButtonActionOnTouchDown(event)) {
break;
}
// Walk up the hierarchy to determine if we're inside a scrolling container.
boolean isInScrollingContainer = isInScrollingContainer();
// For views inside a scrolling container, delay the pressed feedback for
// a short period in case this is a scroll.
if (isInScrollingContainer) {
mPrivateFlags |= PFLAG_PREPRESSED;
if (mPendingCheckForTap == null) {
mPendingCheckForTap = new CheckForTap();
}
mPendingCheckForTap.x = event.getX();
mPendingCheckForTap.y = event.getY();
postDelayed(mPendingCheckForTap, ViewConfiguration.getTapTimeout());
} else {
// Not inside a scrolling container, so show the feedback right away
setPressed(true, x, y);
checkForLongClick(0, x, y);
}
break;
case MotionEvent.ACTION_CANCEL:
。。。
break;
case MotionEvent.ACTION_MOVE:
if (clickable) {
drawableHotspotChanged(x, y);
}
// Be lenient about moving outside of buttons
if (!pointInView(x, y, mTouchSlop)) {
// Outside button
// Remove any future long press/tap checks
removeTapCallback();
removeLongPressCallback();
if ((mPrivateFlags & PFLAG_PRESSED) != 0) {
setPressed(false);
}
mPrivateFlags3 &= ~PFLAG3_FINGER_DOWN;
}
break;
}
return true;
}
return false;
}二、onClick 和 OnLongClick
- 因為我們是拿
ACTION_DOWN作為舉例的。那麼我們先來分析一下case MotionEvent.ACTION_DOWN: 中onTouchEvent是怎麼執行的,以及onClick和OnLongClick是如何產生的:
2.1 onClick 和 OnLongClick 的產生
-
首先,當我們手指按下時,有一個
mHasPerformedLongPress標識會先被設為false。再往下會執行一行postDelayed(mPendingCheckForTap和ViewConfiguration.getTapTimeout()); 我們來看看這一行的作用: -
首先,從名字我們就可以猜測,這是個延時執行的方法。我們進一步閱讀發現
mPendingCheckForTap是一個Runnable動作;ViewConfiguration.getTapTimeout()是一個100mm的延時。也就是說延時100mm後去執行mPendingCheckForTap中的動作。那麼我們就來看看mPendingCheckForTap中做了什麼:
private final class CheckForTap implements Runnable {
public float x;
public float y;
@Override
public void run() {
mPrivateFlags &= ~PFLAG_PREPRESSED;
setPressed(true, x, y);
checkForLongClick(ViewConfiguration.getTapTimeout(), x, y);
}
}- 也就是說,停一百秒后就開始檢查,用戶的手指是否離開了屏幕。( 就是當前
ACTION_DOWN之後,有沒有觸發了ACTION_UP這個環節 ),但是ACTION_DOWN后,我們還有一個ACTION_MOVE過程。在這個ACTION_MOVE中,如果100mm內離開了屏幕、或者離開了這個控件就會觸發ACTION_UP,那麼就認為這是一個點擊事件onClick。如果沒有觸發ACTION_UP的話,就會再延時400mm。
2.2 ACTION_DOWN 之後流程
- 在
ACTION_DOWN之後,會先等100mm - 如果沒有離開屏幕或者離開控件,就是沒有觸發
ACTION_UP的話,就會再延時 400mm。 - 這
500mm后就會觸發onLongClick事件。
2.3 那麼我們現在來驗證一下 onLongClick :
- 首先再
MainActivity中加上:
mMyButton.setOnLongClickListener(new View.OnLongClickListener() {
@Override
public boolean onLongClick(View v) {
return true;
}
});- 接着,我們發現
OnLongClick是有返回值的,如果返回值是false還會接着去觸發onClick事件,如果返回true的話,那麼這個長按事件就直接被消費掉了( 也就是這個點擊事件就不會完後傳遞到OnClickListener中去了 )。
2.4 總結
100mm時為點擊,500mm時為長按,接着觸髮長按事件。- 再看長按事件的返回值,如果時
true就結束。 - 如果時
false那麼OnClickListener就同樣也被執行。 - 這就是由
obTouchEvent產生出來的onClick/onLongClick的來龍去脈。
總結
- 我們
View的事件方法,基本上就是這麼一個思路,從dispatchTouchEvent到OnTouchListener監聽器,再到onTouchEvent,接着onTouchEvent由產生了onClick/onLongClick。 - 如果大家感興趣的話可以更深入的去閱讀源碼。
重點:學Android有一段時間了,我打算好好的梳理一下所學知識,包括Activity、Service、BroadcastRecevier事件分發、滑動衝突、新能優化等所有重要模塊,歡迎大家關注 ,方便及時接收更新- 如果有可以補充的知識點,歡迎大家在評論區指出。
碼字不易,你的點贊是我總結的最大動力!
-
由於我在「稀土掘金」「簡書」「
CSDN」「博客園」等站點,都有新內容發布。所以大家可以直接關注我的GitHub倉庫,以免錯過精彩內容! -
倉庫地址:
-
一萬多字長文,加上精美思維導圖,記得點贊哦,歡迎關注 ,我們下篇文章見!
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想要讓你的商品成為最夯、最多人討論的話題?網頁設計公司讓你強力曝光
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!