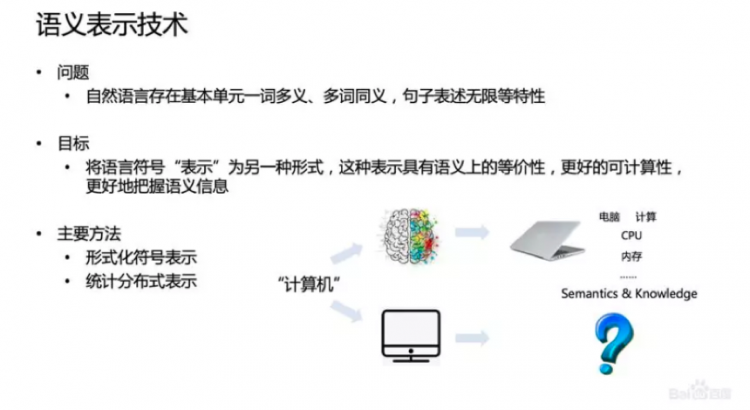
Java鎖-Synchronized深層剖析
前言
Java鎖的問題,可以說是每個JavaCoder繞不開的一道坎。如果只是粗淺地了解Synchronized等鎖的簡單應用,那麼就沒什麼談的了,也不建議繼續閱讀下去。如果希望非常詳細地了解非常底層的信息,如monitor源碼剖析,SpinLock,TicketLock,CLHLock等自旋鎖的實現,也不建議看下去,因為本文也沒有說得那麼深入。本文只是按照synchronized這條主線,探討一下Java的鎖實現,如對象頭部,markdown,monitor的主要組成,以及不同鎖之間的轉換。至於常用的ReentrantLock,ReadWriteLock等,我將在之後專門寫一篇AQS主線的Java鎖分析。
不是我不想解釋得更為詳細,更為底層,而是因為兩個方面。一方面正常開發中真的用不到那麼深入的原理。另一方面,而是那些非常深入的資料,比較難以收集,整理。當然啦,等到我的Java積累更加深厚了,也許可以試試。囧
由於Java鎖的內容比較雜,劃分的維度也是十分多樣,所以很是糾結文章的結構。經過一番考慮,還是採用類似正常學習,推演的一種邏輯來寫(涉及到一些複雜的新概念時,再詳細描述)。希望大家喜歡。
Java鎖的相關概念
如果讓我談一下對程序中鎖的最原始認識,那我就得說說PV操作(詳見我在系統架構師中系統內部原理的筆記)了。通過PV操作可以實現同步效果,以及互斥鎖等。
如果讓我談一下對Java程序中最常見的鎖的認識,那無疑就是Synchronized了。
Java鎖的定義
那麼Java鎖是什麼?網上許多博客都談到了偏向鎖,自旋鎖等定義,唯獨就是沒人去談Java鎖的定義。我也不能很好定義它,因為Java鎖隨着近些年的不斷擴展,其概念早就比原來膨脹了許多。硬要我說,Java鎖就是在多線程情況下,通過特定機制(如CAS),特定對象(如Monitor),配合LockRecord等,實現線程間資源獨佔,流程同步等效果。
當然這個定義並不完美,但也算差不多說出了我目前對鎖的認識(貌似這不叫定義,不要計較)。
Java鎖的分類標準
- 自旋鎖:是指當一個線程在獲取鎖的時候,如果鎖已經被其他線程獲取,那麼該線程將循環等待,然後不斷的判斷鎖是否能夠被成功獲取,直到獲取到鎖才會退出循環(之前文章提到的CAS就是自旋鎖)
- 樂觀鎖:假定沒有衝突,再修改數據時如果發現數據和之前獲取的不一致,則讀最新數據,修改后重試修改(之前文章提到的CAS就是樂觀鎖)
- 悲觀所:假定一定會發生併發衝突,同步所有對數據的相關操作,從讀數據就開始上鎖(Synchronized就是悲觀鎖)
- 獨享鎖:給資源加上獨享鎖,該資源同一時刻只能被一個線程持有(如JUC中的寫鎖)
- 共享鎖:給資源加上共享鎖,該資源可同時被多個線程持有(如JUC中的讀鎖)
- 可重入鎖:線程拿到某資源的鎖后,可自由進入同一把鎖同步的其他代碼(即獲得鎖的線程,可多次進入持有的鎖的代碼中,如Synchronized就是可重入鎖)
- 不可重入鎖:線程拿到某資源的鎖后,不可進入同一把鎖同步的其他代碼
- 公平鎖:爭奪鎖的順序,獲得鎖的順序是按照先來後到的(如ReentrantLock(true))
- 非公平所:爭奪鎖的順序,獲得鎖的順序並非按照先來後到的(如Synchronized)
其實這裏面有很多有意思的東西,如自旋鎖的特性,大家都可以根據CAS的實現了解到了。Java的自選鎖在JDK4的時候就引入了(但當時需要手動開啟),並在JDK1.6變為默認開啟,更重要的是,在JDK1.6中Java引入了自適應自旋鎖(簡單說就是自旋鎖的自旋次數不再固定)。又比如自旋鎖一般都是樂觀鎖,獨享鎖是悲觀所的子集等等。
** Java鎖還可以按照底層實現分為兩種。一種是由JVM提供支持的Synchronized鎖,另一種是JDK提供的以AQS為實現基礎的JUC工具,如ReentrantLock,ReadWriteLock,以及CountDownLatch,Semaphore,CyclicBarrier等。**
Java鎖-Synchronized
Synchronized應該是大家最早接觸到的Java鎖,也是大家一開始用得最多的鎖。畢竟它功能多樣,能力又強,又能滿足常規開發的需求。
有了上面的概念鋪墊,就很好定義Synchronized了。Synchronized是悲觀鎖,獨享鎖,可重入鎖。
當然Synchronized有多種使用方式,如同步代碼塊(類鎖),同步代碼塊(對象鎖),同步非靜態方法,同步靜態方法四種。後面有機會,我會掛上我筆記的相關頁面。但是總結一下,其實很簡單,注意區分鎖的持有者與鎖的目標就可以了。static就是針對類(即所有對該類的實例對象)。
其次,Synchronized不僅實現同步,並且JMM中規定,Synchronized要保證可見性(詳細參照筆記中對volatile可見性的剖析)。
然後Synchronized有鎖優化:鎖消除,鎖粗化(JDK做了鎖粗化的優化,但可以通過代碼層面優化,可提高代碼的可讀性與優雅性)
另外,Synchronized確實很方便,很簡單,但是也希望大家不要濫用,看起來很糟糕,而且也讓後來者很難下叉。
Java鎖的實現原理
終於到了重頭戲,也到了最消耗腦力的部分了。這裏要說明一點,這裏提及的只是常見的鎖的原理,並不是所有鎖原理展示(如Synchronized展示的是對象鎖,而不是類鎖,網上也基本沒有博客詳細寫類鎖的實現原理,但不代表沒有)。如Synchronized方法是通過ACC_SYNCHRONIZED進行隱式同步的。
對象在內存中的結構(重點)
首先,我們需要正常對象在內存中的結構,才可以繼續深入研究。
JVM運行時數據區分為線程共享部分(MetaSpace,堆),線程私有部分(程序計數器,虛擬機棧,本地方法棧)。這部分不清楚的,自行百度或查看我之前有關JVM的筆記。那麼堆空間存放的就是數組與類對象。而MetaSpace(原方法區/持久代)主要用於存儲類的信息,方法數據,方法代碼等。
我知道,沒有圖,你們是不會看的。
PS:為了偷懶,我放的都是網絡圖片,如果掛了。嗯,你們就自己百度吧
PS2:如果使用的網絡圖片存在侵權問題,請聯繫我,抱歉。
第一張圖,簡單地表述了在JVM中堆,棧,方法區三者之間的關係
我來說明一下,我們代碼中類的信息是保存在方法區中,方法區保存了類信息,如類型信息,字段信息,方法信息,方法表等。簡單說,方法區是用來保存類的相關信息的。詳見下圖:
而堆,用於保存類實例出來的對象。
以hotspot的JVM實現為例,對象在對內存中的數據分為三個部分:
- 對象頭(Header):保存對象信息與狀態(重點,後面詳細說明)
- 實例數據(Instance Data):對象真正存儲的有效數據(代碼定義字段,即對象中的實際數據)
- 對齊填充(Padding):VM的自動內存管理要求對象起始地址必須是8字節的整數倍(說白了,就是拋棄的內存空間)
簡單說明一下,對齊填充的問題,可以理解為系統內存管理中頁式內存管理的內存碎片。畢竟內存都是要求整整齊齊,便於管理的。如果還不能理解,舉個栗子,正常人規劃自己一天的活動,往往是以小時,乃至分鐘劃分的時間塊,而不會劃分到秒,乃至微妙。所以為了便於內存管理,那些零頭內存就直接填充好了,就像你制定一天的計劃, 晚上睡眠的時間可能總是差幾分鐘那樣。如果你還是不能理解,你可以查閱操作系統的內存管理相關知識(各類內存管理的概念,如頁式,段式,段頁式等)。
如果你原先對JVM有一定認識,卻理解不深的話,可能就有點迷糊了。
Java對象中的實例數據部分存儲對象的實際數據,什麼是對象的實際數據?這些數據與虛擬機棧中的局部變量表中的數據又有什麼區別?
且聽我給你編,啊呸,我給你說明。為了便於理解,插入圖片
Java對象中所謂的實際數據就是屬於對象中的各個變量(屬於對象的各個變量不包括函數方法中的變量,具體後面會談到)。這裡有兩點需要注意:
- 代碼中是由實際變量與引用變量的概念之分的。實際變量就是實際保存值的變量,而引用變量是一個類似C語言指針的存在,它不保存目標值,而是保存實際變量的引用地址。如果你還是沒法理解,你可以通過數組實驗,或認識Netty零拷貝,原型模式等方法去了解相關概念,增強積累。
- 內存中對象存儲的變量多為引用變量。
- 那麼對象除了各種實際數據外,就是各種函數方法了(函數方法的內存表示,網上很多博客都描述的語焉不詳,甚至錯誤)。函數方法可以分為兩個部分來看:一方面是整體邏輯流程,這個是所有實例對象所共有的,故保存在方法區(而不是某些博客所說的,不是具體實現,所以內存中不存在。代碼都壓入內存了,你和我說執行邏輯不存在?)。另一方面是數據(屬性,變量這種),這個即使是同一個實例對象不同調用時也是不一樣的,故運行時保存在棧(具體保存在虛擬機棧,還是本地方法棧,取決於方法是否為本地方法,即native方法。這部分網上說明較多)。
針對第二點,我舉個實際例子。
如StudentManager對象中有Student stu = new Student(“ming”);,那麼在內存中是存在兩個對象的:StudentManger實例對象,Student實例對象(其傳入構造方法的參數為”ming”)。而在StudentManager實例對象中有一個Student類型的stu引用變量,其值指向了剛才說的Student實例對象(其傳入構造方法的參數為”ming”)。那麼再深入一些,為什麼StudentManager實例對象中的stu引用變量要強調是Student類型的,因為JVM要在堆中為StudentManager實例對象分配明確大小的內存啊,所以JVM要知道實例對象中各個引用變量需要分配的內存大小。那麼stu引用變量是如何指向Student實例對象(其傳入構造方法的參數為”ming”)的?這個問題的答案涉及到句柄的概念,這裏簡單立即為指針指向即可。
數組是如何確定內存大小的。
那麼數組在內存中的表現是怎樣的呢?其實和之前的思路還是一樣的。引用變量指向實際值。
二維數組的話,第一層數組中保存的是一維數組的引用變量。其實如果學習過C語言,並且學得還行的話,這些概念都很好理解的。
關於對象中的變量與函數方法中的變量區別及緣由:眾所周知,Java有對內存與棧內存,兩者都有着保存數據的職責。堆的優勢可以動態分配內存大小,也正由於動態性,所以速度較慢。而棧由於其特殊的數據結構-棧,所以速度較快。一般而言,對象中的變量的生命周期比對象中函數方法的變量的生命周期更長(至少前者不少於後者)。當然還有一些別的原因,最終對象中的變量保存在堆中,而函數方法的變量放在棧中。
補充一下,Java的內存分配策略分為靜態存儲,棧式存儲,堆式存儲。后兩者本文都有提到,說一下靜態存儲。靜態存儲就是編譯時確定每個數據目標在運行時的存儲需求,保存在堆內對應對象中。
針對虛擬機棧(本地方法不在此討論),簡單說明一下(因為後面用得到)。
先上個圖
虛擬機棧屬於JVM中線程私有的部分,即每個線程都有屬於自己的虛擬機棧(Stack)。而虛擬機棧是由一個個虛擬機棧幀組成的,虛擬機棧幀(Stack Frame)可以理解為一次方法調用的整體邏輯流程(Java方法執行的內存模型)。而虛擬機棧是由局部變量表(Local Variable Table),操作棧(Operand Stack),動態連接(Dynamic Linking),返回地址(Reture Address)等組成。簡單說明一下,局部變量表就是用於保存方法的局部變量(生命周期與方法一致。注意基本數據類型與對象的不同,如果是對象,則該局部變量為一個引用變量,指向堆內存中對應對象),操作棧用於實現各種加減乘除的操作等(如iadd,iload等),動態鏈接(這個解釋比較麻煩,詳見《深入理解Java虛擬機》p243),返回地址(用於在退出棧幀時,恢復上層棧幀的執行狀態。說白了就是A方法中調用B方法,B方法執行結束后,如何確保回到A方法調用B方法的位置與狀態,畢竟一個線程就一個虛擬機棧)。
到了這一步,就滿足了接下來學習的基本要求了。如果希望有更為深入的理解,可以坐等我之後有關JVM的博客,或者查看我的相關筆記,或者查詢相關資料(如百度,《深入理解Java虛擬機》等。
Java對象頭的組成(不同狀態下的不同組成)
說了這麼多,JVM是如何支持Java鎖呢?
前面Java對象的部分,我們提到了對象是由對象頭,實例數據,對齊填充三個部分組成。其中后兩者已經進行了較為充分的說明,而對象頭還沒有進行任何解釋,而鎖的實現就要靠對象頭完成。
對象頭由兩到三個部分組成:
- Mark Word:存儲對象hashCode,分代年齡,鎖類型,鎖標誌位等信息(長度為JVM的一個字大小);
- Class Metadata Address:類型指針,指向對象的類元數據(JVM通過這個指針確定該對象是哪個類的實例,指針的長度為JVM的一個字大小);
- Array Length:[只有數組對象有該部分] 數組對象的對象頭必須有一塊記錄數組長度的數據(因為JVM可通過對象的元數據信息確定Java對象大小,但從數組的元數據中無法確定數組大小)(長度為JVM的一個字大小)。
后兩者不是重點,也與本次主題無關,不再贅述。讓我們來細究一下Mark Word的具體數據結構,及其在內存中的表現。
來,上圖。
一般第一次看看這個圖,都有點蒙,什麼玩意兒啊,到底怎麼理解啊。
所以這個時候需要我來給你舉個簡單例子。
如一個對象頭是這樣的:AAA..(一共23個A)..AAA BB CCCC D EE 。其中23個A表示線程ID,2位B表示Epoch,4位C表示對象的分代年齡,1位D表示該對象的鎖是否為偏向鎖,2位E表示鎖標誌位。
至於其它可能嘛。看到大佬已經寫了一個,情況說明得挺好的,就拿來主義了。
圖中展現了對象在無鎖,偏向鎖,輕量級鎖,重量級鎖,GC標記五種狀態下的Mark Word的不同。
| biased_lock |
lock |
狀態 |
| 0 |
01 |
無鎖 |
| 1 |
01 |
偏向鎖 |
| 0 |
00 |
輕量級鎖 |
| 0 |
10 |
重量級鎖 |
| 0 |
11 |
GC標記 |
引用一下這位大佬的哈(畢竟大佬解釋得蠻全面的,我就不手打了,只做補充)。
- thread:持有偏向鎖的線程ID。
- epoch:偏向時間戳。
- age:4位的Java對象年齡。在GC中,如果對象在Survivor區複製一次,年齡增加1。當對象達到設定的閾值時,將會晉陞到老年代。默認情況下,并行GC的年齡閾值為15,併發GC的年齡閾值為6。由於age只有4位,所以最大值為15,這就是-XX:MaxTenuringThreshold選項最大值為15的原因。
- biased_lock:對象是否啟用偏向鎖標記,只佔1個二進制位。為1時表示對象啟用偏向鎖,為0時表示對象沒有偏向鎖。
- identity_hashcode:25位的對象標識Hash碼,採用延遲加載技術。調用方法System.identityHashCode()計算,並會將結果寫到該對象頭中。當對象被鎖定時,該值會移動到管程Monitor中。
- ptr_to_lock_record:指向棧中鎖記錄的指針。
- ptr_to_heavyweight_monitor:指向管程Monitor的指針。
可能你看到這裏,會對上面的解釋產生一定的疑惑,什麼是棧中鎖記錄,什麼是Monitor。別急,接下來的Synchronized鎖的實現就會應用到這些東西。
Java鎖的內存實現
現在就讓我們來看看我們平時使用的Java鎖在JVM中到底是怎樣的情況。
Synchronized鎖一共有四種狀態:無鎖,偏向鎖,輕量級鎖,重量級鎖。其中偏向鎖與輕量級鎖是由Java6提出,以優化Synchronized性能的(具體實現方式,後續可以看一下,有區別的)。
在此之前,我要簡單申明一個定義,首先鎖競爭的資源,我們稱為“臨界資源”(如:Synchronized(this)中指向的this對象)。而競爭鎖的線程,我們稱為鎖的競爭者,獲得鎖的線程,我們稱為鎖的持有者。
無鎖狀態
就是對象不持有任何鎖。其對象頭中的mark word是
| 含義 |
identity_hashcode |
age |
biased_lock |
lock |
|
| 示例 |
aaa…(25位bit) |
xxxx(4位bit) |
0(1位bit ,具體值:0) |
01(2位bit ,具體值:01) |
|
無鎖狀態沒什麼太多說的。
這裏簡單說一下identity_hashcode的含義,25bit位的對象hash標識碼,用於標識這是堆中哪個對象的對象頭。具體會在後面的鎖中應用到。
那麼這個時候一個線程嘗試獲取該對象鎖,會怎樣呢?
偏向鎖狀態
如果一個線程獲得了鎖,即鎖直接成為了鎖的持有者,那麼鎖(其實就是臨界資源對象)就進入了偏向模式,此時Mark Word的結果就會進入之前展示的偏向鎖結構。
那麼當該線程進再次請求該鎖時,無需再做任何同步操作(不需要再像第一次獲得該鎖那樣,進行較為複雜的操作),即獲取鎖的過程只需要檢查Mark Word的鎖標記位位偏向鎖並且當前線程ID等於Mark Word的ThreadID即可,從而節省大量有關鎖申請的操作。
看得有點懵,沒關係,我會好好詳細解釋的。此處有關偏向鎖的內存變化過程就兩個,一個是第一次獲得鎖的過程,一個是後續獲得該鎖的過程。
接下來,我會結合圖片,來詳細闡述這兩個過程的。
當一個線程通過Synchronized鎖,出於需求,對共享資源進行獨佔操作時,就得試圖向別的鎖的競爭者宣誓鎖的所有權。但是,此時由於該鎖是第一次被佔用,也不確定是否後面還有別的線程需要佔有它(大多數情況下,鎖不存在多線程競爭情況,總是由同一線程多次獲得該鎖),所以不會立馬進入資源消耗較大的重量鎖,輕量級鎖,而是選擇資源佔用最少的偏向鎖。為了向後面可能存在的鎖競爭者線程證明該共享資源已被佔用,該臨界資源的Mark Word就會做出相應變化,標記該臨界資源已被佔用。具體Mark Word會變成如下形式:
| 含義 |
thread |
epoll |
age |
biased_lock |
lock |
| 示例 |
aaa…(23位bit) |
bb(2位bit) |
xxxx(4位bit) |
1(1位bit ,具體值:1) |
01(2位bit ,具體值:01) |
這裏我來說明一下其中各個字段的具體含義:
- thread用於標識當前持有鎖的線程(即在偏向鎖狀態下,表示當前該臨界資源被哪個線程持有)
- epoll:用於記錄當前對象的mark word變為偏向結果的時間戳(即當前臨界資源被持有的時間戳)
- age:與無鎖狀態作用相同,無變化
- biased_lock:值為1,表示當前mark word為偏向鎖結構
- lock:配合biased_lock共同表示當前mark word為偏向鎖結果(至於為什麼需要兩個字段共同表示,一方面2bit無法表示4種結構,另一方面,最常用的偏向鎖結果,利用1bit表示,既可以快速檢驗,又可以降低檢驗的資源消耗。需要的話,之後細說,或@我)
接下來就是第二個過程:鎖的競爭者線程嘗試獲得鎖,那麼鎖的競爭者線程會檢測臨界資源,或者說鎖對象的mark word。如果是無鎖狀態,參照上一個過程。如果是偏向鎖狀態,就檢測其thread是否為當前線程(鎖的競爭者線程)的線程ID。如果是當前線程的線程ID,就會直接獲得臨界資源,不需要再次進行同步操作(即上一個過程提到的CAS操作)。
還看不懂,再引入一位大佬的:
偏向鎖的加鎖過程:
-
訪問Mark Word中偏向鎖的標識是否設置成1,鎖標誌位是否為01,確認為可偏向狀態。
-
如果為可偏向狀態,則測試線程ID是否指向當前線程,如果是,進入步驟5,否則進入步驟3。
-
如果線程ID並未指向當前線程,則通過CAS操作競爭鎖。如果競爭成功,則將Mark Word中線程ID設置為當前線程ID,然後執行5;如果競爭失敗,執行4。
-
如果CAS獲取偏向鎖失敗,則表示有競爭。當到達全局安全點(safepoint)時獲得偏向鎖的線程被掛起,偏向鎖升級為輕量級鎖,然後被阻塞在安全點的線程繼續往下執行同步代碼。(撤銷偏向鎖的時候會導致stop the word)
-
執行同步代碼。
PS:safepoint(沒有任何字節碼正在執行的時候):詳見JVM GC相關,其會導致stop the world。
偏向鎖的存在,極大降低了Syncronized在多數情況下的性能消耗。另外,偏向鎖的持有線程運行完同步代碼塊后,不會解除偏向鎖(即鎖對象的Mark Word結構不會發生變化,其threadID也不會發生變化)
那麼,如果偏向鎖狀態的mark word中的thread不是當前線程(鎖的競爭者線程)的線程ID呢?
輕量級鎖
輕量級鎖可能是由偏向鎖升級而來的,也可能是由無鎖狀態直接升級而來(如通過JVM參數關閉了偏向鎖)。
偏向鎖運行在一個線程進入同步塊的情況下,而當第二個線程加入鎖競爭時,偏向鎖就會升級輕量級鎖。
如果JVM關閉了偏向鎖,那麼在一個線程進入同步塊時,鎖對象就會直接變為輕量級鎖(即鎖對象的Mark Word為偏向鎖結構)。
上面的解釋非常簡單,或者說粗糙,實際的判定方式更為複雜。我在查閱資料時,發現網上很多博客根本沒有深入說明偏向鎖升級輕量級鎖的深層邏輯,直到看到一篇寫出了以下的說明:
當線程1訪問代碼塊並獲取鎖對象時,會在java對象頭和棧幀中記錄偏向的鎖的threadID,因為偏向鎖不會主動釋放鎖,因此以後線程1再次獲取鎖的時候,需要比較當前線程的threadID和Java對象頭中的threadID是否一致,如果一致(還是線程1獲取鎖對象),則無需使用CAS來加鎖、解鎖;如果不一致(其他線程,如線程2要競爭鎖對象,而偏向鎖不會主動釋放因此還是存儲的線程1的threadID),那麼需要查看Java對象頭中記錄的線程1是否存活,如果沒有存活,那麼鎖對象被重置為無鎖狀態,其它線程(線程2)可以競爭將其設置為偏向鎖;如果存活,那麼立刻查找該線程(線程1)的棧幀信息,如果還是需要繼續持有這個鎖對象,那麼暫停當前線程1,撤銷偏向鎖,升級為輕量級鎖,如果線程1 不再使用該鎖對象,那麼將鎖對象狀態設為無鎖狀態,重新偏向新的線程。
這段說明的前半截,我已經在偏向鎖部分說過了。我來說明一下其後半截有關鎖升級的部分。
如果當前線程(鎖的競爭者線程)的線程ID與鎖對象的mark word的thread不一致(其他線程,如線程2要競爭鎖對象,而偏向鎖不會主動釋放因此還是存儲的線程1的threadID),那麼需要查看Java對象頭中記錄的線程1是否存活(可以直接根據鎖對象的Mark Word(更準確說是Displaced Mark Word)的thread來判斷線程1是否還存活),如果沒有存活,那麼鎖對象被重置為無鎖狀態,從而其它線程(線程2)可以競爭該鎖,並將其設置為偏向鎖(等於無鎖狀態下,重新偏向鎖的競爭);如果存活,那麼立刻查找該線程(線程1)的棧幀信息,如果線程1還是需要繼續持有這個鎖對象,那麼暫停當前線程1,撤銷偏向鎖,升級為輕量級鎖,如果線程1 不再使用該鎖對象,那麼將鎖對象狀態設為無鎖狀態,重新偏向新的線程。(這個地方其實是比較複雜的,如果有不清楚的,可以@我。)
那麼另一個由無鎖狀態升級為輕量級鎖的內存過程,就是:
首先讓我來說明一下上面提到的“如果線程1還是需要繼續持有這個鎖對象,那麼暫停當前線程1,撤銷偏向鎖,升級為輕量級鎖”涉及的三個問題。
- 為什麼需要暫停線程1
- 如何撤銷偏向鎖
- 如何升級輕量級鎖
第一個問題,如果不暫停線程1,即線程1的虛擬機棧還在運行,那麼就有可能影響到相關的Lock Record,從而導致異常發生。
第二個問題與第三個問題其實是一個問題,就是通過修改Mark Word的鎖標誌位(lock)與偏向鎖標誌(biased_lock)。將Mark Word修改為下面形式:
| 含義 |
thread |
epoll |
age |
biased_lock |
lock |
| 示例 |
aaa…(23位bit) |
bb(2位bit) |
xxxx(4位bit) |
1(1位bit ,具體值:1) |
01(2位bit ,具體值:01) |
在代碼進入同步塊的時候,如果鎖對象的mark word狀態為無鎖狀態,JVM首先將在當前線程的棧幀)中建立一個名為鎖記錄(Lock Record)的空間,用於存儲Displaced Mark Word(即鎖對象目前的Mark Word的拷貝)。
有資料稱:Displaced Mark Word並不等於Mark Word的拷貝,而是Mark Word的前30bit(32位系統),即Hashcode+age+biased_lock,不包含lock位。但是目前我只從網易微專業課聽到這點,而其它我看到的任何博客都沒有提到這點。所以如果有誰有確切資料,希望告知我。謝謝。
鎖的競爭者嘗試獲取鎖時,會先拷貝鎖對象的對象頭中的Mark Word複製到Lock Record,作為Displaced Mark Word。然後就是之前加鎖過程中提到到的,JVM會通過CAS操作將鎖對象的Mark Word更新為指向Lock Record的指針(這與之前提到的修改thread的CAS操作毫無關係,就是修改鎖對象的引用變量Mark Word的指向,直接指向鎖的競爭者線程的Lock Record的Displaced Mark Word)。CAS成功后,將Lock Record中的owner指針指向鎖對象的Mark Word。而這就表示鎖的競爭者嘗試獲得鎖成功,成為鎖的持有者。
而這之後,就是修改鎖的持有者線程的Lock Record的Displaced Mark Word。將Displaced Mark Word的前25bit(原identity_hashcode字段)修改為當前線程(鎖的競爭者線程)的線程ID(即Mark word的偏向鎖結構中的thread)與當前epoll時間戳(即獲得偏向鎖的epoll時間戳),修改偏向鎖標誌位(從0變為1)。
聽得有點暈暈乎乎,來,給你展示之前那位大佬的(另外我還增加了一些註釋):
輕量級鎖的加鎖過程(無鎖升級偏向鎖):
-
在代碼進入同步塊的時候,如果同步對象鎖狀態為無鎖狀態(鎖標誌位為“01”狀態,是否為偏向鎖為“0”),虛擬機首先將在當前線程的棧幀(即同步塊進入的地方,這個需要大家理解基於棧的編程的思想)中建立一個名為鎖記錄(Lock Record)的空間,用於存儲 Displaced Mark Word(鎖對象目前的Mark Word的拷貝)。這時候線程堆棧與對象頭的狀態如圖:
(上圖中的Object就是鎖對象。)
-
拷貝對象頭中的Mark Word複製到鎖記錄中,作為Displaced Mark Word;
-
拷貝成功后,JVM會通過CAS操作(舊值為Displaced Mark Word,新值為Lock Record Adderss,即當前線程的鎖對象地址)將鎖對象的Mark Word更新為指向Lock Record的指針(就是修改鎖對象的引用變量Mark Word的指向,直接指向鎖的競爭者線程的Lock Record的Displaced Mark Word),並將Lock record里的owner指針指向鎖對象的Mark Word。如果更新成功,則執行步驟4,否則執行步驟5。
-
如果這個更新動作成功了,那麼這個線程就擁有了該對象的鎖,並且對象Mark Word的鎖標誌位設置為“00”,即表示此對象處於輕量級鎖定狀態,這時候線程堆棧與對象頭的狀態如圖所示。
(上圖中的Object就是鎖對象。)
-
如果這個更新操作失敗了,虛擬機首先會檢查對象的Mark Word是否指向當前線程的棧幀,如果是就說明當前線程已經擁有了這個對象的鎖,那就可以直接進入同步塊繼續執行(這點是Synchronized為可重入鎖的佐證,起碼說明在輕量級鎖狀態下,Synchronized鎖為可重入鎖。)。否則說明多個線程競爭鎖,輕量級鎖就要膨脹為重量級鎖(其實是CAS自旋失敗一定次數后,才進行鎖升級),鎖標誌的狀態值變為“10”,Mark Word中存儲的就是指向重量級鎖(互斥量)的指針,後面等待鎖的線程也要進入阻塞狀態。 而當前線程便嘗試使用自旋來獲取鎖,自旋就是為了不讓線程阻塞,而採用循環去獲取鎖的過程。
適用的場景為線程交替執行同步塊的場景。
那麼輕量級鎖在什麼情況下會升級為重量級鎖呢?
重量級鎖:
重量級鎖是由輕量級鎖升級而來的。那麼升級的方式有兩個。
第一,線程1與線程2拷貝了鎖對象的Mark Word,然後通過CAS搶鎖,其中一個線程(如線程1)搶鎖成功,另一個線程只有不斷自旋,等待線程1釋放鎖。自旋達到一定次數(即等待時間較長)后,輕量級鎖將會升級為重量級鎖。
第二,如果線程1拷貝了鎖對象的Mark Word,並通過CAS將鎖對象的Mark Word修改為了線程1的Lock Record Adderss。這時候線程2過來后,將無法直接進行Mark Word的拷貝工作,那麼輕量級鎖將會升級為重量級鎖。
無論是同步方法,還是同步代碼塊,無論是ACC_SYNCHRONIZED(類的同步指令,可通過javap反彙編查看)還是monitorenter,monitorexit(這兩個用於實現同步代碼塊)都是基於Monitor實現的。
所以,要想繼續在JVM層次學習重量級鎖,我們需要先學習一些概念,如Monitor。
Monitor
- 互斥同步時一種常見的併發保障手段。
- 同步:確保同一時刻共享數據被一個線程(也可以通過信號量實現多個線程)使用。
- 互斥:實現同步的一種手段
- 關係:互斥是因,同步是果。互斥是方法,同步是目的
- 主要的互斥實現手段有臨界區(Critical Section),互斥量(Mutex),信號量(Semaphore)(信號量又可以分為二進制,整型,記錄型。這裏不再深入)。其中后兩者屬於同步原語。
- 在Mutex和Semaphore基礎上,提出更高層次的同步原語Monitor。操作系統不支持Monitor機制,部分語言(如Java)支持Monitor機制。
這裏貼上作者的一頁筆記,幫助大家更好理解(主要圖片展示效果,比文字好)。
(請不要在意字跡問題,以後一定改正)
說白了,Java的Monitor,就是JVM(如Hotspot)為每個對象建立的一個類似對象的實現,用於支持Monitor實現(實現了Monitor同步原語的各種功能)。
上面這張圖的下半部分,揭示了JVM(Hotspot)如何實現Monitor的,通過一個objectMonitor.cpp實現的。該cpp具有count,owner,WaitSet,EntryList等參數,還有monitorenter,monitorexit等方法。
看到這裏,大家應該對Monitor不陌生了。一般說的Monitor,指兩樣東西:Monitor同步原語(類似協議,或者接口,規定了這個同步原語是如何實現同步功能的);Monitor實現(類似接口實現,協議落地代碼等,就是具體實現功能的代碼,如objectMonitor.cpp就是Hotspot的Monitor同步原語的落地實現)。兩者的關係就是Java中接口和接口實現。
Monitor實現重量級鎖
那麼monitor是如何實現重量級鎖的呢?其實JVM通過Monitor實現Synchronized與JDK通過AQS實現ReentrantLock有異曲同工之妙。只不過JDK為了實現更好的功能擴展,從而搞了一個AQS,使得ReentrantLock看起來非常複雜而已,後續會開一個專門的系列,寫AQS的。這裏繼續Monitor的分析。
從之前的objectMonitor.cpp的圖中,可以看出:
- objectMonitor有兩個隊列_EntryList和_WaitSet,兩者都是用於保存objectWaiter對象的,其中**_EntryList用於保存等鎖(線程狀態為Block)的對象,而_WaitSet用於保存處於Wait線程狀態(區別於Sleep線程狀態,Wait線程狀態的對象不僅會讓出CPU,還會釋放已佔用的同步鎖資源)的對象**。
- _owner表示當前持有同步鎖的objectWaiter對象。
- _count則表示作為可重入鎖的Synchronized的重入次數(否則,如何確定持有鎖的線程是否完成了釋放鎖的操作呢)。
- monitorenter與monitorexit主要負責加鎖與釋放鎖的操作,不過由於Synchronized的可重入機制,所以需要對_count進行修改,並根據_count的值,判斷是否釋放鎖,是否進行加鎖等流程。
這個部分的代碼邏輯不需要太過深入理解,只需要清楚明白關鍵參數的意義,以及大致流程即可。
有關具體重量級鎖的底層ObjectMonitor源碼解析,我就不再贅述,因為有一位大佬給出(我覺得挺好的,再深入就該去看源碼了)。
如果真的希望清楚了解代碼運行流程,又覺得看源碼太過麻煩。可以查看我之後寫的有關JUC下AQS對ReentrantLock的簡化實現。看懂了那個,你會發現Monitor實現Synchronized的套路也就那樣了(我自己就是這麼過來的)。
Monitor與持有鎖的線程
看完前面一部分的人,可能對如何實現Monitor,Monitor如何實現Synchronized已經很了解了。但是,Monitor如何與持有鎖的線程產生關係呢?或者進一步問,之前提到的objectWaiter是個什麼東西?
來,上圖片。
從圖中,可以清楚地看到,ObjectWaiter * _next與ObjectWaiter * _prev(volatile就不翻譯,文章前面有),說明ObjectWaiter對象是一個雙向鏈表結構。其中通過Thread* _thread來表示當前線程(即競爭鎖的線程),通過TStates TState表示當前線程狀態。這樣一來,每個等待鎖的線程都會被封裝成OjbectWaiter對象,便於管理線程(這樣一看,就和ReentrantLock更像了。ReentrantLock通過AQS的Node來封裝等待鎖的線程)。
補充
- 由於新到來鎖競爭線程,會先嘗試成為鎖的持有者。在嘗試失敗后,才會切換線程狀態為Block,並進入_EntryList。這就導致新到來的競爭鎖的線程,可能在_EntryList不為空的情況下,直接持有同步鎖,所以Synchronized為不公平鎖。又由於該部分並沒有提供別的加鎖邏輯,所以Synchronized無法通過設置,改為公平鎖。具體代碼邏輯參照ReentrantLock。
- notify()喚醒的是_WaitSet中任意一個線程,而不是根據等待時間確定的。
- 對象的notifyAll()或notify()喚醒的對象,不會從_WaitSet移動到_EntryList中,而是直接參与鎖的競爭。競爭鎖失敗就繼續在_WatiSet中等待,競爭鎖成功就從_WaitSet中移除。這是從JVM性能方面考慮的:如元素在兩個隊列中移動的資源消耗,以及notify()喚醒的對象不一定能競爭鎖成功,那麼就需要再移動回_WaitSet。
- Monitor中線程狀態的切換是通過什麼實現的呢?首先線程狀態從根源來說,也只是一個參數而已。其次,據我所知,Hotspot的Monitor是通過park()/unpark()實現(我看到的兩份資料都是這麼寫的)。然後,Hostpot的Monitor中的park()/unpark()區別於JDK提供的park()/unpark(),兩者完全不是一個東西。但是落地到操作系統層,可能是同一個東西。最後,這方面我了解得還不是很深入,如果有誰了解,歡迎交流。
鎖的變遷
最後就是,無鎖,偏向鎖,輕量級鎖,重量級鎖之間的轉換了。
啥都別說了,上圖。
這個圖,基本就說了七七八八了。我就不再深入闡述了。
注意一點,輕量級鎖降級,不會降級為偏向鎖,而是直接降級為無鎖狀態。
重量級鎖,就不用我說了。要麼上鎖,要麼沒有鎖。
鎖的優化
鎖的優化,包括自旋鎖,自適應自旋鎖,鎖消除,鎖粗化。
自旋鎖(multiple core CPU)
- 許多情況下,共享數據的鎖定狀態持續時間較短,切換線程不值得(也許切換線程的資源消耗就超過了共享數據的鎖定持續時間帶來的資源消耗)。
- 通過線程執行忙循環等待鎖的釋放,不讓出CPU。
- 缺點:若鎖被其它線程長時間佔用,會帶來許多性能上的開銷。
- 自旋的等待時間是有限制的(其中忙循環的循環次數是存在默認值的)。
- Hotspot可通過PreBlockSpin參數,修改默認旋轉次數。
自適應自旋鎖
- 自旋的次數難以把握,難以完美。
- 自旋的次數不再固定(可能為零)。
- 由前一次在同一個鎖上的自旋時間及鎖的擁有者的狀態來決定。
- 舉例:同一個鎖對象上,自旋等待剛剛成功獲取過鎖,並且持有鎖的線程正在運行=》JVM認為該鎖自旋獲得鎖的可能性大。
鎖消除
JIT(Just In Time)編譯時,對運行上下文進行掃描,去除不可能存在競爭的鎖。
JIT(Hotspot Code):
- 運行頻繁的代碼,將會進行編譯,轉換為機器碼。
- JIT編譯是以method為單位的。
鎖粗化
通過擴大加鎖的範圍,避免反覆加鎖和解鎖。
總結
刨除代碼,這篇文章在已發表的文章中,應該是我花的時間最長,手打內容最多的文章了。
從開始編寫,到編寫完成,前前後后,橫跨兩個月。當然主要也是因為這段時間太忙了,沒空進行博客的編寫。
在編寫這篇博客的過程中,我自己也收穫很多,將許多原先自己認為自己懂的內容糾正了出來,也將自己對JVM的認識深度,再推進一層。
最後,願與諸君共進步。
參考資料
《深入理解Java虛擬機》
:
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包"嚨底家"
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家費用,距離,噸數怎麼算?達人教你簡易估價知識!