一、應用場景
一般情況下我們對springboot應用打包時使用springboot的maven插件spring-boot-maven-plugin的maven進行打包,打包完成得到一個fatjar,fatjar的優點是可以直接運行,缺點是體積太大,不利於傳輸,springboot應用打出來的fatjar體積少則幾十M,多則上百M,在往服務器部署傳輸時十分不便,可能只改了某個類文件,都需要重新將整個fatjar重新傳輸一次,特別是走公網傳輸的時候,可能上傳速度只有幾百甚至幾十KB,而整個fatjar中真正我們項目的代碼文件可能也就幾百KB或幾兆的大小,所以有必要將fatjar中的依賴庫與我們項目的class進行分離打包,這樣每次更換項目class就方便很多,而將配置文件也分離出來的原因在於我們可能經常需要更改配置文件的內容,如果放在fatjar中這樣修改是非常不方便的,所以也需要將配置文件也分離出來。
> fatjar 即將項目需要的所有依賴庫及配置文件等打進一個jar或war,該文件可直接運行
二、配置
2.1 POM配置
下面對pom.xml進行配置,來實現分離打包,配置如下
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>chenyb</groupId> <artifactId>demo</artifactId> <version>v1.2-release</version> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.1.6.RELEASE</version> </parent> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> </dependencies> <build> <plugins> <!-- springboot 打包插件 --> <!-- <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <configuration> <mainClass>com.xx.xx</mainClass> </configuration> <executions> <execution> <goals> <goal>repackage</goal> </goals> </execution> </executions> </plugin> --> <!-- maven 打包插件 --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-jar-plugin</artifactId> <configuration> <archive> <manifest> <addClasspath>true</addClasspath> <!-- MANIFEST.MF 中 Class-Path 加入前綴 --> <classpathPrefix>lib/</classpathPrefix> <!-- jar包不包含唯一版本標識 --> <useUniqueVersions>false</useUniqueVersions> <!-- 指定入口類 --> <mainClass>cn.test.DemoApplication</mainClass> </manifest> </archive> <outputDirectory>${project.build.directory}</outputDirectory> </configuration> </plugin> <!-- 拷貝依賴 --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-dependency-plugin</artifactId> <executions> <execution> <id>copy-dependencies</id> <phase>package</phase> <goals> <goal>copy-dependencies</goal> </goals> <configuration> <outputDirectory>${project.build.directory}/lib</outputDirectory> <overWriteReleases>true</overWriteReleases> <overWriteSnapshots>true</overWriteSnapshots> <overWriteIfNewer>true</overWriteIfNewer> </configuration> </execution> </executions> </plugin> </plugins> </build> </project>
關鍵配置說明:
(1) 去掉了spring-boot-maven-plugin打包插件
(2) 添加 maven-jar-plugin (maven標準打包插件)
(3) maven-dependency-plugin(依賴拷貝插件,主要用於將maven依賴庫拷貝出來)
插件具體的配置,pom.xml中已添加備註說明
2.2 打包
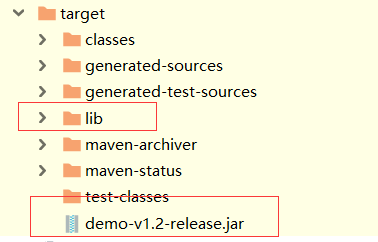
執行maven package 命令進行打包,得到的結果如下
將 lib目錄 及 項目jar 文件拷貝到同一目錄下,我為了測試方便,先全部拷貝到桌面上,(放置服務器上時也需保證在同一目錄下)
打開demo-v1.2-release可以看到,並沒有將依賴jar打進來,大小隻有不到4KB
2.3 config目錄創建
以上做完還還需要將項目配置文件拷貝出來,在與jar包平級目錄建立config目錄,將項目中的application.properties或yaml文件拷貝進來
config 下的文件
經過以上步驟,全部配置完畢,下面進行一下簡單的測試
三、測試
為了保證加載的是外部config目錄的配置文件,我將application-test.yaml中的server.port改為8085, 打開命令行輸入
C:\Users\Administrator\Desktop>java -jar -Dspring.profiles.active=dev -Dspring.location.config=config/ C:\Users\Administrator\Desktop\demo-v1.2-release.jar
回車運行,能正常啟動說明外部依賴可以正常加載進來
可以看到啟動完成后tomcat監聽端口為8085,說明外部配置加載成功。
PS : 如果外部配置文件加載失敗,會使用項目jar中的配置文件,如下圖,也就是啟動後會是8080端口
application-dev.yaml中配置的端口是8080
而我已將外部config目錄下application-dev.yaml中端口做了修改,使用外部配置文件啟動後會是8085端口
四、一點小坑
默認情況下window命令行打開后,是在當前用戶目錄下,像這樣
而我的config、lib、項目jar拷貝在桌面上,實際路徑是
一開始我在 C:\Users\Administrator> 直接執行下方命令,一直加載不到配置文件
java -jar -Dspring.profiles.active=dev -Dspring.location.config=config/ C:\Users\Administrator\Desktop\demo-v1.2-release.jar
原因就在於程序與配置文件不在同一目錄下,我在C:\Users\Administrator>運行啟動命令,而程序實際目錄在 C:\Users\Administrator\Desktop> 下,因為程序使用了絕對路徑,可以找到文件,所以程序的實際運行路徑為C:\Users\Administrator\Desktop,而我使用的配置 spring.location.config=config/ 使用的是相對路徑,,這個相對路徑又是相對 C:\Users\Administrator> 目錄,所以就會出現找不到配置文件的情況。
解決辦法一:
命令行切換到 C:\Users\Administrator\Desktop 目錄,即項目jar所在目錄,運行 java -jar 命令
解決辦法二:
將config拷貝到C:/Users/Administrator下,保證C:/Users/Administrator相對路徑下存在config目錄及配置文件(該方法可解決問題,但是不建議)
解決方法三:
spring.location.config=config/ 處使用絕對路徑,即C:/Users/Administrator/Desktop/config/
所以很重要一點,一定保證 執行命令 的目錄 與項目jar、lib、config都在同一目錄下。
五、完整demo地址
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象