本節主要介紹SpringBoot Application類相關源碼的深入學習。
主要包括:
- SpringBoot應用自定義啟動配置
- SpringBoot應用生命周期,以及在生命周期各個階段自定義配置。
本節採用SpringBoot 2.1.10.RELASE,對應示例源碼在:
SpringBoot應用啟動過程:
SpringApplication application = new SpringApplication(DemoApplication.class);
application.run(args);一、Application類自定義啟動配置
創建SpringApplication對象后,在調用run方法之前,我們可以使用SpringApplication對象來添加一些配置,比如禁用banner、設置應用類型、設置配置文件(profile)
舉例:
@SpringBootApplication
public class DemoApplication {
public static void main(String[] args) {
SpringApplication application = new SpringApplication(DemoApplication.class);
// 設置banner禁用
application.setBannerMode(Banner.Mode.OFF);
// 將application-test文件啟用為profile
application.setAdditionalProfiles("test");
// 設置應用類型為NONE,即啟動完成后自動關閉
application.setWebApplicationType(WebApplicationType.NONE);
application.run(args);
}
} 也可以使用SpringApplicationBuilder類來創建SpringApplication對象,builder類提供了鏈式調用的API,更方便調用,增強了可讀性。
new SpringApplicationBuilder(YqManageCenterApplication.class)
.bannerMode(Banner.Mode.OFF)
.profiles("test")
.web(WebApplicationType.NONE)
.run(args);二、application生命周期
SpringApplication的生命周期主要包括:
- 準備階段:主要包括加載配置、設置主bean源、推斷應用類型(三種)、創建和設置SpringBootInitializer、創建和設置Application監聽器、推斷主入口類
- 運行階段:開啟時間監聽、加載運行監聽器、創建Environment、打印banner、創建和裝載context、廣播應用已啟動、廣播應用運行中
我們先來看一下源碼的分析:
SpringBootApplication構造器:
public SpringApplication(ResourceLoader resourceLoader, Class<?>... primarySources) {
// 設置默認配置
this.sources = new LinkedHashSet();
this.bannerMode = Mode.CONSOLE;
this.logStartupInfo = true;
this.addCommandLineProperties = true;
this.addConversionService = true;
this.headless = true;
this.registerShutdownHook = true;
this.additionalProfiles = new HashSet();
this.isCustomEnvironment = false;
this.resourceLoader = resourceLoader;
Assert.notNull(primarySources, "PrimarySources must not be null");
// 設置主bean源
this.primarySources = new LinkedHashSet(Arrays.asList(primarySources));
// 推斷和設置應用類型(三種)
this.webApplicationType = WebApplicationType.deduceFromClasspath();
// 創建和設置SpringBootInitializer
this.setInitializers(this.getSpringFactoriesInstances(ApplicationContextInitializer.class));
// 創建和設置SpringBoot監聽器
this.setListeners(this.getSpringFactoriesInstances(ApplicationListener.class));
// 推斷和設置主入口類
this.mainApplicationClass = this.deduceMainApplicationClass();
}SpringApplication.run方法源碼:
public ConfigurableApplicationContext run(String... args) {
// 開啟時間監聽
StopWatch stopWatch = new StopWatch();
stopWatch.start();
ConfigurableApplicationContext context = null;
Collection<SpringBootExceptionReporter> exceptionReporters = new ArrayList();
this.configureHeadlessProperty();
// 加載Spring應用運行監聽器(SpringApplicationRunListenter)
SpringApplicationRunListeners listeners = this.getRunListeners(args);
listeners.starting();
Collection exceptionReporters;
try {
// 創建environment(包括PropertySources和Profiles)
ApplicationArguments applicationArguments = new DefaultApplicationArguments(args);
ConfigurableEnvironment environment = this.prepareEnvironment(listeners, applicationArguments);
this.configureIgnoreBeanInfo(environment);
// 打印banner
Banner printedBanner = this.printBanner(environment);
// 創建context(不同的應用類型對應不同的上下文)
context = this.createApplicationContext();
exceptionReporters = this.getSpringFactoriesInstances(SpringBootExceptionReporter.class, new Class[]{ConfigurableApplicationContext.class}, context);
// 裝載context(其中還初始化了IOC容器)
this.prepareContext(context, environment, listeners, applicationArguments, printedBanner);
// 調用applicationContext.refresh
this.refreshContext(context);
// 空方法
this.afterRefresh(context, applicationArguments);
stopWatch.stop(); // 關閉時間監聽;這樣可以計算出完整的啟動時間
if (this.logStartupInfo) {
(new StartupInfoLogger(this.mainApplicationClass)).logStarted(this.getApplicationLog(), stopWatch);
}
// 廣播SpringBoot應用已啟動,會調用所有SpringBootApplicationRunListener里的started方法
listeners.started(context);
// 遍歷所有ApplicationRunner和CommadnLineRunner的實現類,執行其run方法
this.callRunners(context, applicationArguments);
} catch (Throwable var10) {
this.handleRunFailure(context, var10, exceptionReporters, listeners);
throw new IllegalStateException(var10);
}
try {
// 廣播SpringBoot應用運行中,會調用所有SpringBootApplicationRunListener里的running方法
listeners.running(context);
return context;
} catch (Throwable var9) {
// run出現異常時,處理異常;會調用報錯的listener里的failed方法,廣播應用啟動失敗,將異常擴散出去
this.handleRunFailure(context, var9, exceptionReporters, (SpringApplicationRunListeners)null);
throw new IllegalStateException(var9);
}
}三、application生命周期自定義配置
在SpringApplication的生命周期中,我們還可以添加一些自定義的配置。
下面的配置,主要是通過實現Spring提供的接口,然後在resources下新建META-INF/spring.factories文件,在裏面添加這個類而實現引入的。
在準備階段,可以添加如下自定義配置:
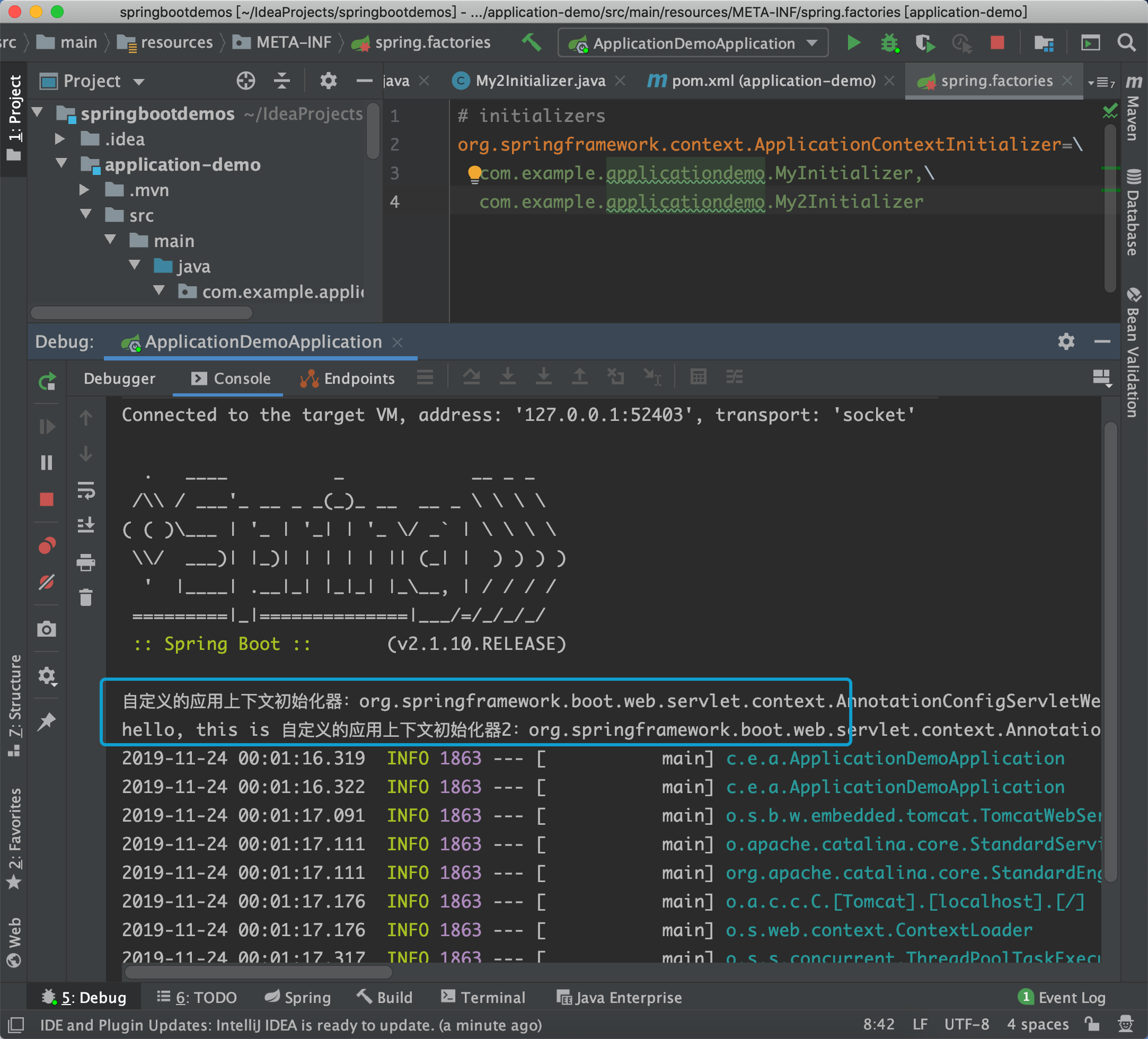
3.1 自定義ApplicationContextInitializer的實現類
@Order(100)
public class MyInitializer implements ApplicationContextInitializer {
@Override
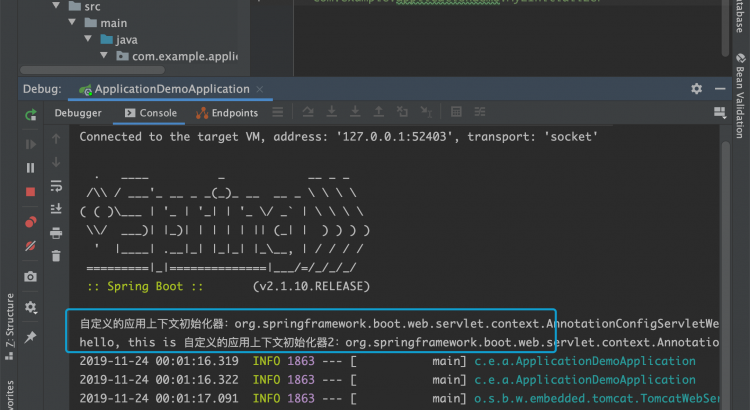
public void initialize(ConfigurableApplicationContext configurableApplicationContext) {
System.out.println("自定義的應用上下文初始化器:" + configurableApplicationContext.toString());
}
}再定義一個My2Initializer,設置@Order(101)
然後在spring.factories文件里如下配置:
# initializers
org.springframework.context.ApplicationContextInitializer=\
com.example.applicationdemo.MyInitializer,\
com.example.applicationdemo.My2Initializer啟動項目:
3.2 自定義ApplicationListener的實現類
@FunctionalInterface
public interface ApplicationListener<E extends ApplicationEvent> extends EventListener {
void onApplicationEvent(E var1);
}即監聽ApplicationEvents類的ApplicationListener接口的實現類。
首先查看有多少種ApplicationEvents:
裏面還可以進行拆分。
我們這裏設置兩個ApplicationListener,都用於監聽ApplicationEnvironmentPreparedEvent
@Order(200)
public class MyApplicationListener implements ApplicationListener<ApplicationEnvironmentPreparedEvent> {
@Override
public void onApplicationEvent(ApplicationEnvironmentPreparedEvent applicationEnvironmentPreparedEvent) {
System.out.println("MyApplicationListener: 應用環境準備完畢" + applicationEnvironmentPreparedEvent.toString());
}
}在spring.factories中加入applicationListener的配置:
# application-listeners
org.springframework.context.ApplicationListener=\
com.example.applicationdemo.MyApplicationListener,\
com.example.applicationdemo.MyApplicationListener2在啟動階段,可以添加如下自定義配置:
3.3 自定義SpringBootRunListener的實現類
監聽整個SpringBoot應用生命周期
public interface SpringApplicationRunListener {
// 應用啟動
void starting();
// 應用ConfigurableEnvironment準備完畢,此刻可以將其調整
void environmentPrepared(ConfigurableEnvironment environment);
// 上下文準備完畢
void contextPrepared(ConfigurableApplicationContext context);
// 上下文裝載完畢
void contextLoaded(ConfigurableApplicationContext context);
// 啟動完成(Beans已經加載到容器中)
void started(ConfigurableApplicationContext context);
// 應用運行中
void running(ConfigurableApplicationContext context);
// 應用運行失敗
void failed(ConfigurableApplicationContext context, Throwable exception);
}我們可以自定義SpringApplicationRunListener的實現類,通過重寫以上方法來定義自己的listener。
比如:
public class MyRunListener implements SpringApplicationRunListener {
// 注意要加上這個構造器,兩個參數都不能少,否則啟動會報錯,報錯的詳情可以看這個類的最下面
public MyRunListener(SpringApplication springApplication, String[] args) {
}
@Override
public void starting() {
System.out.println("MyRunListener: 程序開始啟動");
}
// 其他方法省略,不做修改
}然後在spring.factories文件中添加這個類:
org.springframework.boot.SpringApplicationRunListener=\
com.example.applicationdemo.MyRunListener啟動:
3.4 自定義ApplicationRunner或CommandLineRunner
application的run方法中,有這樣一行:
this.callRunners(context, applicationArguments);仔細分析源碼,發現這一句的作用是:SpringBoot應用啟動過程中,會遍歷所有的ApplicationRunner和CommandLineRunner,執行其run方法。
private void callRunners(ApplicationContext context, ApplicationArguments args) {
List<Object> runners = new ArrayList();
runners.addAll(context.getBeansOfType(ApplicationRunner.class).values());
runners.addAll(context.getBeansOfType(CommandLineRunner.class).values());
AnnotationAwareOrderComparator.sort(runners);
Iterator var4 = (new LinkedHashSet(runners)).iterator();
while(var4.hasNext()) {
Object runner = var4.next();
if (runner instanceof ApplicationRunner) {
this.callRunner((ApplicationRunner)runner, args);
}
if (runner instanceof CommandLineRunner) {
this.callRunner((CommandLineRunner)runner, args);
}
}
}@FunctionalInterface
public interface CommandLineRunner {
void run(String... args) throws Exception;
}@FunctionalInterface
public interface ApplicationRunner {
void run(ApplicationArguments args) throws Exception;
}分別定義一個實現類,添加@Component,這兩個實現類不需要在spring.factories中配置。
好了,關於這些自定義配置的具體使用,後續會繼續進行介紹,請持續關注!感謝!
具體示例代碼請去查看。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想要讓你的商品成為最夯、最多人討論的話題?網頁設計公司讓你強力曝光
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!