整理:鄒敏惠(環境資訊中心記者)
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※台北網頁設計公司全省服務真心推薦
※想知道最厲害的網頁設計公司"嚨底家"!
※推薦評價好的iphone維修中心
※網頁設計最專業,超強功能平台可客製化
※別再煩惱如何寫文案,掌握八大原則!
摘錄自2020年4月29日自由時報報導
美國北卡羅萊納州有一隻巴哥犬被檢測出對武漢肺炎病毒呈陽性反應,恐為美國第一隻寵物犬確診案例。
《NBC》報導,該隻名叫溫斯頓(Winston)的巴哥其主人家庭有多人確診,男女主人和兒子均呈陽性反應,女兒、另一隻狗以及寵物貓則呈陰性反應。女主人麥可萊恩(Heather McLean)表示,溫斯頓有輕微症狀,早上沒有食慾。報導指出,該隻巴哥的家庭成員還透露,狗狗會舔遍所有的餐盤,然後跟主人一起睡覺。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準
※網頁設計最專業,超強功能平台可客製化
※別再煩惱如何寫文案,掌握八大原則!
99萬福克斯 2017款 三廂 EcoBoost 180 自動旗艦型 指導價16。58萬配置表現福克斯更勝一籌,雖然差價只在4100元,福克斯和思域相比配置更為豐富,方向盤換擋、SONY索尼揚聲器品牌、后視鏡電動摺疊、感應雨刷,自動泊車入位這些配置思域上並沒有。
前言隨着現在轎車市場越來越家用化,運動型轎車也變的不那麼運動了,更多是兼家用和運動,各佔一半,就變得不倫不類了,舒適性談不上,運動性能也是很一般,正所謂魚與熊掌不可得兼,根本也扯不到平衡,總要有一方更強勢。現在年輕消費者就佔據大半汽車市場,而年輕人更追求快感與操控,所以他們在空間取向並沒有上一輩人這麼注重。
東風本田-思域
指導價:11.59-16.99萬
長安福特-福克斯
指導價:9.98-16.58萬
外觀對比
全新一代思域可謂是改頭換面,無論是在外觀、動力都非常成功,在視覺效果可以說非常驚艷與時尚,車身線條十分運動,雖然延續了本田家族式設計,但整體看起來依然很年輕。
福克斯外觀設計,就談不上驚艷,來的更多是沉穩,就像一位斯斯文文眼鏡男,但衣服里藏里一大塊腹肌,是個有實力的选手。但在細節方面也做的不錯,動感車身線條,現在都流行“套臉”模式而福克斯也不例外,因為有了蒙迪歐這代車型,視覺效果並沒有太大衝擊。
內飾對比
思域內飾上雖然重新設計,但是塑料感依舊強烈,說它就是台飛度用料一點也不誇張,車廂用料方面反而福克斯更加厚道,中控檯面積採用大面積軟質材料包裹,但整體上思域內飾時尚,唯一缺憾用料吝嗇、福克斯個性,做工很厚道。
空間對比
本田,一個最會將空間玩的淋漓盡致的品牌,思域空間表現毋庸置疑,作為A轎車,無論是頭部還是膝部空間,都有很大余量。而福克斯空間依然是它短板,因為中控台較寬大,利用了不少車廂空間,所以在乘坐後排,坐長途不太舒適,但作為年輕人之選,這不影響他們的選擇。
配置對比
思域 2016款 220TURBO 自動尊耀版 指導價:16.99萬
福克斯 2017款 三廂 EcoBoost 180 自動旗艦型 指導價16.58萬
配置表現福克斯更勝一籌,雖然差價只在4100元,福克斯和思域相比配置更為豐富,方向盤換擋、SONY索尼揚聲器品牌、后視鏡電動摺疊、感應雨刷,自動泊車入位這些配置思域上並沒有。作為偏運動車型,連方向盤換擋都沒有,這個必須減分。配置上思域表現也並不差,全液晶儀錶盤、後座出風口、自動駐車、胎壓監測裝置等配置。
動力對比
兩款車型都搭載1.5T渦輪增壓發動機,動力表現兩者都幾乎相差無幾,傳動系統,福克斯配備6擋手自一體、思域則配備CVT無級變速箱。響應性,福克斯會更激進,思域平順性更高,思域雖然搭載CVT變速箱,這款變速箱我想大家也非常了解,但思域用上這套變速箱動力響應能兼顧平順的同時在動力輸出變現也不錯。
福克斯配備6AT變速箱,在急加速時,依然會思考下人生,隨後動力才湧現。行駛質感,福克斯更高級,底盤濾震處理相當不錯,底盤很紮實硬朗;思域,底盤很從容,行駛質感也較為舒服。隔音方面福克斯與思域相比更為高級。
編者總結:
這兩款車型,作為年輕買家來說,都是在考慮範圍內,無論是動力外觀兩者都有不錯的表現,福克斯操控方面略強,但空間是它唯一短板,思域在綜合表現比福克斯更好,空間外觀都比福克斯更好。如果追求操控在空間並沒有太多需求則選福克斯,而追求動力的同時需要較大空間就選思域。本站聲明:網站內容來源於http://www.auto6s.com/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※教你寫出一流的銷售文案?
※超省錢租車方案
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※回頭車貨運收費標準
雪佛蘭 – 探界者預計售價:18萬起預計上市日期:2017年近幾年來,雪佛蘭幾乎只有一款創酷在征戰SUV市場(老舊的科帕奇可以忽略不計),要想進一步提升銷量,推出一款全新的SUV勢在必行,於是就有了這台探界者。福特有探險者和撼路者,雪佛蘭搞出個探界者是什麼鬼。
持續了近10天的2016廣州國際車展終於在上周日謝幕,在不少媒體老濕吐槽本屆車展沒有太多亮點的時候,叫獸卻發現了另一番風景:
好了,說回正題,這屆車展雖然看點不多,甚至除了媒體日那天可憐的日產外(你懂的),都沒有太多可以調侃的段子,但以下這些SUV的登場還是給叫獸帶來不少驚喜。廢話結束,接下來看看在即將到來的2017年有哪些SUV是值得我們期待的。
寶駿 – 510
預計售價:5.5 – 8萬
上市日期:預計2017年1季度
我把寶駿510排在第一位,其預計的親民售價是第一點,最最重要的還是它擁有堪稱驚艷的外觀設計。如果不是親眼所見,真不敢相信這居然是寶駿出品的一款車。
犀利、個性、時尚、前衛···這一些列詞彙悉數冠在510身上也毫不為過,sorry,原諒叫獸任性一回,僅憑外觀就愛上了這款車。不過在感性之餘,咱們回歸到理性部分。
510的內飾同樣令人稱讚,雖談不上有多麼精緻,但看上去毫不雜亂,算得上是簡潔大方,這對一款入門車型來說是難能可貴的。
從前两天有關510文章的評論里可以看出,大家對這款車都很期待。叫獸斷言,只要未來的價格給力,這又將是一款爆款的存在。小道消息稱,510將於2017年1季度上市。
名爵 – ZS
預計售價:暫本站聲明:網站內容來源於http://www.auto6s.com/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※超省錢租車方案
※教你寫出一流的銷售文案?
※網頁設計最專業,超強功能平台可客製化
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※台中搬家遵守搬運三大原則,讓您的家具不再被破壞!
長寬高達到4949/1930/1785mm,軸距也達到2810mm,數據不亞於同級別競爭對手。新車提供5座和7座版本車型,其中7座採用2+3+2的座椅布局。而在長安CS95眾多的產品賣點的重中之重,都放在這台2。0TGDI發動機,最大馬力為233ps,最大扭矩360Nm,官方百公里加速為9。
隨着家庭人口的增多,以及消費層次的升級,7座SUV逐漸成為SUV市場中不可忽視的一股消費主力。特別是傳祺GS8的上市,不只是成功聚焦了眾人的眼光,更是讓消費者重新定義了屬於7座SUV的魅力。於是,在利益和現實因素的推動下,越來越多的車企瞄準了7座SUV市場紛紛出大招。
相比傳統的5座SUV,其實市面上7座SUV的產品線非常單薄,以致於寡頭垄斷的局面曾經持續了很長一段時間。事實上,隨着7座SUV這一細分市場的升溫,除了考慮漢蘭達、銳界、傳祺GS8,你還可以考慮這些即將上市的7座SUV。
金杯蒂阿茲
預售價:8.68萬元
上市時間:2016年12月
大部分對於華晨金杯的印象,還停留在爛大街的商務車上。而近期亮相的金杯蒂阿茲,可謂完全“刷新”了國人對於金杯的認識。一眼望去,如果不仔細加以辨認,還以為是套上金杯logo的謳歌MDX。當然,外觀方面是懂的人自然懂。更何況,不到9萬的預售價已經相當有吸引力了。
內飾方面中規中矩,但好在配置應該比較豐富。新車搭載一台1.5T發動機,最大馬力154ps,峰值扭矩 210Nm。先期預計將推出一款手動擋5座車型,而準備購買自動擋以及7座版車型的消費者,或許還要等到明年才有機會下手。
長安CS95
預售價:未知
上市時間:2017年第一季度
繼哈弗、傳祺推出了7座SUV之後,長安CS95量產版也終於按耐不住選在這個節骨眼亮相。有意思的是,之前飽受吐槽的“回”字前臉,總算是被重新修飾了一番,整體效果看起來不錯。車身形象高大威猛,好一副硬派SUV的作風。這裏也不得不提到長安CS95的戰略意義,目前是被長安用來衝擊高端的首款中型SUV,產品力可想而知。
即然是一台全尺寸旗艦SUV,長安CS95的車身尺寸沒有讓人失望。長寬高達到4949/1930/1785mm,軸距也達到2810mm,數據不亞於同級別競爭對手。新車提供5座和7座版本車型,其中7座採用2+3+2的座椅布局。而在長安CS95眾多的產品賣點的重中之重,都放在這台2.0TGDI發動機,最大馬力為233ps,最大扭矩360Nm,官方百公里加速為9.8秒。
起亞KX7
預售價:未知
上市時間:2017年3月
迫不及待加入7座SUV戰場的,還有來自韓國的起亞。據悉,全新起亞KX7是基於上一代索蘭托平台開發,簡單理解而言又是一台中國特供車。新車繼續沿用家族式設計語言,造型穩重大氣,又不失時尚感。就外觀來講,起亞KX7顯然是非常符合國人的審美觀念的。
但看看起亞KX7整體的車身尺寸,一比較2790mm的漢蘭達和2850mm的銳界,軸距僅為2700mm的起亞KX7的產品短板就非常明顯了,尤其是第三排座椅舒適度會是一個很大障礙。不過,從起亞KX7所公布的配置情況,再結合韓系車一向的低價傳統,上市后的起亞KX7預計仍將通過高性價比的策略,力爭7座SUV市場份額。
大眾Teramont
預售價:未知
上市時間:2017年上半年
國產大眾途觀明年上市的消息,就已經讓多少大眾粉朝思暮想。與此同時,另一款大眾重磅車型的亮相再次引爆人們的話題點,那就是全新中大型SUV-大眾 Teramont。新車延續了大眾CrossBlue概念車的設計,形象霸氣魁梧,視覺上極具震撼力。
更牛逼的是,車身尺寸已經大大超過途銳,幾乎與奧迪Q7旗鼓相當,長寬高為5039/1989/1773mm,軸距也順利達到逆天的2980mm。就180cm大個子的體驗,無論是第二排還是第三排,空間可以用大到沒朋友形容。動力總成也非常給力,大眾Teramont採用2.0T高低功率版以及2.5T V6發動機,匹配7速濕式雙離合變速箱。如果不出意外,配合一個合理厚道的價位,以及大眾的神車光環,大眾Teramont大賣不成問題。本站聲明:網站內容來源於http://www.auto6s.com/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※教你寫出一流的銷售文案?
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※回頭車貨運收費標準
※別再煩惱如何寫文案,掌握八大原則!
※超省錢租車方案
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※推薦台中搬家公司優質服務,可到府估價
東風AX7指導價格:9。97-14。17萬東風風神AX7是基於東風軍工二號平台生產的首款民用SUV車型,在做工品質上還是有着一定的高質量保證,同樣藉助多年與國外知名汽車企業合資的資源性便利,東風AX7在汽車配件供應商方面也是來頭不小。
採用愛信變速箱的自主SUV
最近小編收到不少的網友留言,問題的主要偏重點在於:中國自主品牌當中的SUV有哪些採用愛信變速箱?或者愛信變速箱為什麼那麼多人採用?那麼今天就帶着問題,看看愛信變速箱究竟有什麼優勢讓這麼多人採用。
愛信變速箱可以說是現在汽車市場中的明星產品系列,不少情況下都會聽到“XX車使用了愛信變速箱”的話語,那麼究竟為什麼它的受眾面會這麼廣?
品牌成熟,技術可本站聲明:網站內容來源於http://www.auto6s.com/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※超省錢租車方案
※別再煩惱如何寫文案,掌握八大原則!
※回頭車貨運收費標準
※教你寫出一流的銷售文案?
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※網頁設計最專業,超強功能平台可客製化
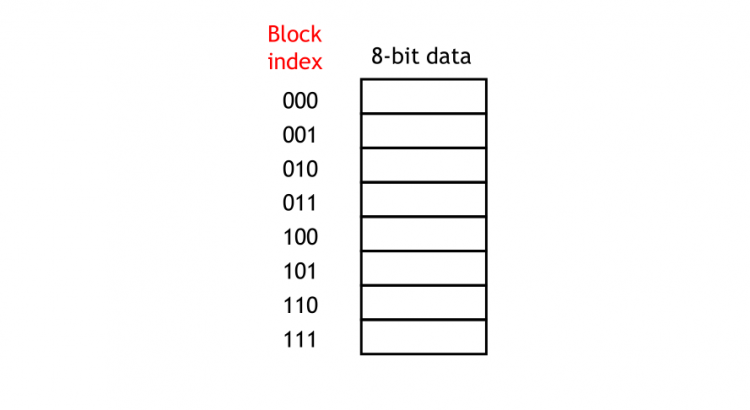
本節內容計劃是講解TLB與高速緩存的關係,但是在涉及高速緩的前提是我們必須要了解操作系統緩存原理,所以提前先詳細了解下緩存原理,我們依然是採取循序漸進的方式來解答緩存原理,若有敘述不當之處,還請批評指正。
高速緩存被劃分為多個塊,其大小可能不同,緩存中的塊數通常為2的冪。如下為一個具有八個塊的高速緩存,每個塊包含一個字節。
通過本節對緩存原理的學習我們能夠學習到四點:
【1】當我們將數據塊從主存儲器複製到緩存,我們到底應該放在哪裡?
【2】如何判斷一個字是否已經在緩存中,或者它是否必須首先從主存儲器中獲取?
【3】較小的緩存最終會填滿, 需要至從主存加載新塊,我們必須替換緩存中現有的哪個塊?
【4】存儲系統如何處理寫操作?
緩存最簡單的數據結構是直接映射: 其中每個存儲器地址僅僅對應到緩存中的一個位置。例如如下,16個字節的主存和4個字節的緩存(每個塊一個字節),內存地址為0、4、8、12分別映射到緩存中為0的塊,而地址1、5、9、13被映射到塊1
等等,我們是不是講解的太快了,上述地址怎麼就劃分到比如塊0或塊1了呢?要找出緩存所在塊採取取模法:(塊地址)mod (緩存中的塊數),如果緩存包含2k塊,則內存地址i處的數據將進入緩存塊索引為i mod 2k。還是不懂?我們來舉個例子,如下緩存有4個塊,那麼地址為14將映射到塊2即(14 mod 4 = 2)。
為便於大家理解如上為10進製表示內存地址,將內存地址映射到緩存塊中實際等效的方式是將內存地址中的最低有效k位(二進制)進行映射。正如下面我們所看到的,內存地址14(1110,二進制)將最低有效位10作為塊中的索引
到目前為止我們知道了將地址利用直接映射的結構映射到緩存中,那麼我們找到數據是否在緩存中呢?如果要讀取內存地址i,則可以使用mod技巧來確定哪個緩存塊將包含i,如上所述,若其他地址也可能映射到相同的緩存塊,那麼我們如何區分它們呢?例如如下內存地址2、6、10、14都在緩存塊2中
為了解決這個問題,我們需要向高速緩存中添加標記(tag),通過內存地址的高位來提供標記位,以使我們能夠區分映射到同一高速緩存塊的不同存儲位置。例如如下。內存地址6即(0110,二進制),將低位10作為索引(index),高位01作為標記(tag)。
我們通過將高速緩存塊標記(tag)與塊索引(index)組合起來,可以準確地知道主存儲器的哪些地址存儲在高速緩存中。
當程序加載到內存中時,緩存為空,不包含有效數據,我們應該通過為每個緩存塊添加一個有效位來解決這個問題,系統初始化時,所有有效位均設置為0,當數據加載到特定的緩存塊中時,相應的有效位設置為1。
當CPU嘗試從內存中讀取數據時,該地址將被發送到緩存控制器,地址的最低k位將在緩存中索引一個塊,如果該塊有效且標籤與m位地址的高(m-k)位匹配,則該數據將被發送到CPU,如下為一個32位內存地址和210字節高速緩存的圖。
到這裏我們會發現一個問題,將每一個字節對應一字節緩存塊並沒有很好的利用空間局部性,要是訪問一個地址后將訪問附近的地址,我們又該怎麼辦?我們要做的是將緩存塊的大小要大於1個字節。如下,我們使用兩個字節的塊,因此我們可以用兩個來加載緩存一次讀取一個字節,如果我們從內存地址12讀取數據,則地址中的數據12和13都將被複制到緩存塊2。
現在,我們又該如何確定數據應放在緩存中的位置?現在演變成塊地址,如果緩存塊大小為2n字節,我們也可以在概念上將主內存也劃分成2n字節塊,要確定字節地址i的塊地址,可以進行整數除法(i / 2n),如下示例中有2個字節的緩存塊,因此我們可以將16個字節的主存儲器視為8塊主存儲器,例如,存儲器地址12和13都對應於塊地址6,因為12 / 2 = 6和13 / 2 = 6。
現在我們知道了塊地址,就可以像上述一樣將其映射到緩存:找到塊地址除以緩存塊數后的餘數。在如下示例中,內存塊6屬於緩存塊2,因為6 mod 4 =2,這對應於將來自存儲器字節地址12和13的數據都放入高速緩存塊2中。
當我們訪問內存中的一個字節數據時,我們會將其整個塊複製到緩存中以達到充分利用空間局部性。在我們的示例中,如果程序從字節地址12讀取,我們會將所有存儲塊6(地址12和13)都加載到緩存塊2中(注意:字節地址13對應於相同的存儲塊地址)因此,對地址13的讀取也會導致將存儲塊6(地址12和13)加載到高速緩存塊2中。為了簡化起見,存儲塊的字節i始終存儲在相應高速緩存塊的字節i中。
假設我們有一個包含2k塊的緩存,每個塊包含2n個字節,我們可以通過查看其在主內存中的地址來確定該緩存中一個字節的數據位置,地址的k位將選擇2k個高速緩存塊之一,最低的n位現在是一個塊偏移量,它決定了高速緩存塊中的2n個字節中的哪個將存儲數據。
我們來舉個例子加深理解,如下示例使用22塊高速緩存,每個塊佔21字節,因此,存儲器地址13(1101)將存儲在高速緩存塊2的字節1中。
到這裏為止,我們才算分析清楚了緩存中有效位、標記位、索引、偏移它們的由來以及實際作用。同時對於緩存採用的直接映射(direct mapped)結構:索引和偏移量可以使用位運算符或簡單的算術運算,因為每個內存地址都恰好屬於一個塊。實際上我們可以將一個塊放置到緩存中的任何一個位置,這種機制稱為全相聯(fully associative)。全相聯的高速緩存允許將數據存儲在任何高速緩存塊中,而不是將每個內存地址強制映射到一個特定的塊中,從內存中獲取數據時,可以將其放置在高速緩存的任何未使用塊中。 這樣,我們將永遠不會在映射到單個緩存塊的兩個或多個內存地址之間發生衝突,在上述示例中,我們可能將內存地址2放在緩存塊2中,並將地址6放在塊3中。然後對2和6的後續重複訪問將全部命中而不是未命中,如果所有塊都已被使用,則使用LRU算法進行替換。但是在全相聯緩存中要查找一個指定的塊,由於該塊存放在緩存中的任何位置,因此需要檢索緩存中的所有項,為了是檢索更加有效,它是由一個與緩存中每個項都相關的比較器并行完成的,這些比較器加大了硬件開銷,因而,全相聯只適合塊數較少的緩存。介於直接映射和全相聯之間的設計是組相聯(set associative)。在組相聯緩存中,每個塊可被放置的位置數固定,每個塊有n個位置可放的緩存被稱作n路組相聯,一個n路組相聯緩存由很多組組成,每個組有n個塊。通過上述對直接映射的講解,最終我們得出指定內存地址所在存儲的塊號為:(塊號) mod (緩存中的塊數),而組相聯對於存儲塊號是:(塊號) mod (緩存中的組數)。如下為8塊高速緩存的組織
組相聯實際上就是將塊進行分組,比如如上第一個圖則是直接映射(我們大可將其看做是每一個塊就是一個組,所以是1路8組相聯),而第二張圖則是每2個塊作為一組,所以是2路4組相聯,同理第三張圖是4路2組相聯。換句話說,若每組有2n塊,那麼就是2n路相聯。通過對組相聯的講解,我們再敘內存地址在組相聯緩存中的位置。如果我們有2s組並且每塊有2n字節,那麼內存地址映射在緩存中的位置則是如下這般
現在我們運算則是計算緩存中的組索引而非再是塊,上述Block offset(在組中塊偏移)= 內存地址 mod 2n,塊地址 = 內存地址 / 2n,set index(組索引) = 塊地址 mod 2s。我們還是通過圖解來進行敘述,假設有一個8塊的高速緩存,然後每個塊是16個字節,那麼內存地址為6195的數據存儲在緩存哪裡呢?首先我們將6195轉換為二進制 = 110000 011 0011,因每個塊是16字節即24,所以塊偏移量為4位即0011,若採用1路8組相聯(直接映射)那麼其組索引就是(6195 mod 8) = 3,取6195轉換而二進制去除偏移量4位,所以為011,同理(根據上述給定計算公式)對於2路4組相聯其組索引為(11),4路2組相聯其組索引為(1),如下:
到這裏我們知道將數據進行緩存我們可以採取直接映射、組相聯、全相聯的機制,通過增加相聯度通常可以降低緩存缺失率,但是增加相聯度也就增加了每組中的塊數,也就是并行查找時同時比較的次數,相聯度每增加兩倍就會使得每組中的塊數加倍而使得組數減半,所以增大了訪問時間的開銷。如何找到一個塊,當然也就依賴於所使用的將塊放置的機制(直接映射、組相聯、全相聯),相較於全相聯而言,它使用複雜的替換策略而降低缺失率且很容易被索引,而不需要額外的硬件,也不需要進行查找。因此虛擬存儲系統通常使用全相聯映射,而組相聯映射通常應用於緩存和TLB。
緩存缺失被分為以下三類(3C模型,three Cs model),因其三類名稱以字母c開頭而得名
強制缺失(compulsory miss):對從沒有在緩存中出現的塊第一次進行訪問引起的缺失,也稱為冷啟動缺失(cold-start miss)
容量缺失:(capacity miss):由於緩存容納不了一個程序執行所需要的所有塊而引起的緩存缺失,當某些塊被替換出去,隨後再被調入時,將發生容量缺失
衝突缺失(conflict miss):在組相聯或者直接映射的緩存中,多個競爭同一個組時而引起的緩存缺失。衝突缺失在直接映射或組相聯緩存中存在,而在同樣大小的全相聯緩存中不存在,這種緩存缺失也稱為碰撞缺失(collision miss)
改變緩存設計的某一方面就能直接影響這些缺失的原因。衝突缺失是因為爭用同一個緩存塊而引起的,因此提高相聯度可以減少衝突缺失,然後提高相聯度會延長訪問時間,導致整個性能的降低,容量缺失可以簡單地通過增大緩存容量來減少,當然緩存容量增大的同時必然導致訪問時間的增加,也將導致整體性能的降低。
在相聯的緩存中發生缺失時,我們必須決定替換哪一塊,如若是全相聯,那麼所有的塊都是被替換的候選者,如若是組相聯,我們必須在某一組的塊中進行選擇,當然,直接映射的緩存替換很簡單,因為只有一個可以替換的候選者。因此在全相聯或組相聯緩存中 ,有兩種主要的替換策略
隨機法:隨機選擇候選塊,可能使用一些硬件來協助實現,例如TLB缺失、MIPS支持隨機替換
LRU(最近最少使用算法):被替換的塊是最久沒有被使用過的塊 (在大多虛擬存儲器中,對於LRU都是通過提供引用位來近似實現(比如TLB))
指令緩存缺失(數據缺失也類似如此)處理步驟如下:
【1】將程序計數器(PC)的原始值送到寄存器
【2】通知主存執行一次讀操作,並等待主存訪問完成
【3】寫緩存項,將從主存取回的數據寫入緩存中存放數據的部分,並將高位(從ALU中得到)寫入標記域,設置有效位
【4】重啟指令執行第一步,重新取指,這次該指令發生在緩存中
數據訪問是對緩存的控制基本相同:發生缺失時,處理器發生阻塞,直到從存儲器中取回數據后才響應。在執行寫操作時,如果有一個存儲指令,我們只將數據寫入緩存而不改變主存中的內容,那麼在寫入緩存后將導致緩存和主存被認為不一致,保持主存和緩存一致性最簡單的方法是將數據同時寫入主存和緩存中,這種方法稱為【寫直達】法。但是這種方法無法提供良好的性能,因為每次寫操作都要把數據寫入主存中,這些寫操作將花費大量的時間,可能至少花費100個處理時鐘周期,並且大大降低了機器速度,解決這個問題的方案之一是採用【寫緩衝:一個保存等待寫入主存數據的緩衝隊列】,當一個數據在等待寫入緩存時,先將其寫入緩衝中,當數據寫入緩存和緩衝后,處理器可以繼續執行,當寫主存操作完成后,寫緩衝里的數據項也得到有效釋放。如果寫緩衝已經滿了,那麼當處理器執行到一個寫操作時就必須停下來直到寫緩衝中有一個空位置,當然,如果存儲器完成寫操作的速度比處理器產生寫操作的速度慢,那麼再多的緩衝器也無用,因為產生寫操作比存儲系統接收它們更快。
除了寫直達方法外,另外一種可選擇的方法是【寫回】,在寫回機制中,當發生寫操作時,新值僅僅被寫入到緩存塊中,只有當修改過的塊被替換時才需要寫到磁盤上,寫回機制可提高系統性能,尤其是當處理器寫操作的速度和主存處理寫操作速度一樣快甚至更快時,但是,寫回機制的實現比寫直達要複雜得多。大部分寫回機制的緩衝也是使用寫緩衝,當在發生缺失替換一個被修改的塊時,寫緩衝可以起到降低缺失代價的作用。在這種情況下,被修改的數據塊移入與緩存相聯的寫回緩衝器,同時從主存中讀出所需要的數據塊。隨後,寫回緩衝器再將數據寫入主存,如果下一次缺失沒有立刻發生,當臟數據塊必須被替換時,這種方法可以減少一半的缺失代價。
一個緩存塊可以放在何處:一個位置(直接映射),一些位置(組相聯),任何位置(全相聯)。
如何找到一個塊:索引(直接映射的緩存中),有限的檢索(組相聯的緩存中),全部檢索(全相聯的緩存中)、專用查找頁表。
緩存缺失時替換哪一塊:隨機選取、LRU
寫操作如何處理:寫直達或寫回策略
本文我們非常詳細的講解了緩存的基本原理,當然對於如何處理緩存一致性並未涉及(大多採用監聽協議),希望通過我對緩存原理的理解能給閱讀的您能有力所能及的幫助,謝謝。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※教你寫出一流的銷售文案?
※別再煩惱如何寫文案,掌握八大原則!
我們使用Spring開發過程中經常會用到Autowired註解注入依賴的bean,這部分也是面試的熱點問題之一。今天咱們一起來深入研究下自動注入的背後實現原理。首先上一個例子,如下所示:
@RestController public class TestController { @Autowired List<ICheckRuleService> checkRuleService; @RequestMapping("/test") public void test(){ checkRuleService.forEach(x->x.valid()); } }
Autowired是怎麼實現自動注入的呢,今天我們來通過源碼分析一下。當Spring創建 TestController Bean時,會調用AbstractBeanFactory#doGetBean(如果對Spring創建Bean流程不熟的讀者,可以給我留言,後面考慮是否寫個IOC系列),doGetBean裏面會調用doCreateBean()方法去創建Bean,創建Bean之後,會對Bean進行填充
try { this.populateBean(beanName, mbd, instanceWrapper); exposedObject = this.initializeBean(beanName, exposedObject, mbd); }
populateBean 里有這樣一段代碼,看起來是處理Autowired的,分別是autowireByName 和 autowireByType
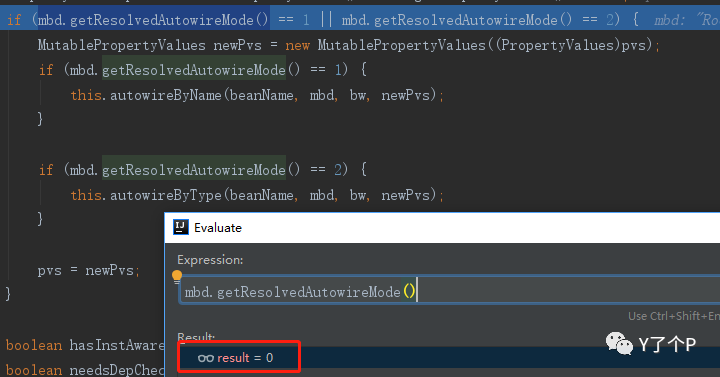
PropertyValues pvs = mbd.hasPropertyValues() ? mbd.getPropertyValues() : null; if (mbd.getResolvedAutowireMode() == 1 || mbd.getResolvedAutowireMode() == 2) { MutablePropertyValues newPvs = new MutablePropertyValues((PropertyValues)pvs); if (mbd.getResolvedAutowireMode() == 1) { this.autowireByName(beanName, mbd, bw, newPvs); } if (mbd.getResolvedAutowireMode() == 2) { this.autowireByType(beanName, mbd, bw, newPvs); } pvs = newPvs; }
我們來驗證一下,通過斷點調試我們發現並不會進入if里,所以自動注入並不是這裏實現的。那這裡有什麼用呢,先放一放,後面再說。
那麼到底是哪裡注入進去的呢?我們繼續往下看,在這段代碼下方有個BeanPostProcessor的邏輯,通過斷點我們發現有個AutowiredAnnotationBeanPostProcessor 的後置處理器,當這個BeanPostProcessor執行完 postProcessPropertyValues方法后,testController的checkRuleService 屬性就有了值了,說明屬性值注入肯定和 AutowiredAnnotationBeanPostProcessor 有關,我們跟進去看一下
進入AutowiredAnnotationBeanPostProcessor的postProcessPropertyValues 方法里,裏面主要有兩部分邏輯
首先看到一段 findAutowiringMetadata 的邏輯,根據方法名稱知道是獲取當前bean的注入元信息
調用 metadata.inject 注入屬性
public PropertyValues postProcessPropertyValues(PropertyValues pvs, PropertyDescriptor[] pds, Object bean, String beanName) throws BeanCreationException { InjectionMetadata metadata = this.findAutowiringMetadata(beanName, bean.getClass(), pvs); try { metadata.inject(bean, beanName, pvs); return pvs; } catch (BeanCreationException var7) { throw var7; } catch (Throwable var8) { throw new BeanCreationException(beanName, "Injection of autowired dependencies failed", var8); } }
我們進入findAutowiringMetadata,看下它的邏輯,先從 injectionMetadataCache 緩存里取,如果取不到值,則調用buildAutowiringMetadata 構建 InjectionMetadata ,構建成功後設置到緩存里。
private InjectionMetadata findAutowiringMetadata(String beanName, Class<?> clazz, @Nullable PropertyValues pvs) { String cacheKey = StringUtils.hasLength(beanName) ? beanName : clazz.getName(); InjectionMetadata metadata = (InjectionMetadata)this.injectionMetadataCache.get(cacheKey); if (InjectionMetadata.needsRefresh(metadata, clazz)) { synchronized(this.injectionMetadataCache) { metadata = (InjectionMetadata)this.injectionMetadataCache.get(cacheKey); if (InjectionMetadata.needsRefresh(metadata, clazz)) { if (metadata != null) { metadata.clear(pvs); } metadata = this.buildAutowiringMetadata(clazz); this.injectionMetadataCache.put(cacheKey, metadata); } } } return metadata; }
我們來看下 buildAutowiringMetadata,繼續跟進去,源碼如下:
裏面是通過當前Bean的Class反射獲取 Field 和 Method ,然後對 Field 和 Method 分別調 findAutowiredAnnotation 方法獲取自動注入的註解,然後根據註解類型是否required構建不同類型的InjectedElement。
AutowiredAnnotationBeanPostProcessor.AutowiredFieldElement:
boolean required = this.determineRequiredStatus(ann); currElements.add(new AutowiredAnnotationBeanPostProcessor.AutowiredFieldElement(field, required));
AutowiredAnnotationBeanPostProcessor.AutowiredMethodElement:
boolean required = this.determineRequiredStatus(ann); PropertyDescriptor pd = BeanUtils.findPropertyForMethod(bridgedMethod, clazz); currElements.add(new AutowiredAnnotationBeanPostProcessor.AutowiredMethodElement(method, required, pd));
補充:通過AutowiredAnnotationBeanPostProcessor 構造函數我們知道,自動注入處理的是被 @Autowired 和 @Value 這兩個註解標註的屬性(Field)或方法(Method):
public AutowiredAnnotationBeanPostProcessor() { this.autowiredAnnotationTypes.add(Autowired.class); this.autowiredAnnotationTypes.add(Value.class); //......
到這裏,需要注入的元數據信息就已經構建完成了,接下來就要到注入部分了。來看下 postProcessPropertyValues 的第二部分。
前面獲取到了需要注入的元數據信息,接下來是元數據 inject 的實現,繼續跟進去,裏面是一個for循環,循環調用了element的inject方法
if (!((Collection)elementsToIterate).isEmpty()) { for(Iterator var6 = ((Collection)elementsToIterate).iterator(); var6.hasNext(); element.inject(target, beanName, pvs)) { element = (InjectionMetadata.InjectedElement)var6.next(); if (logger.isDebugEnabled()) { logger.debug("Processing injected element of bean '" + beanName + "': " + element); } } }
我們斷點調試進去,發現element的真實類型是AutowiredAnnotationBeanPostProcessor.AutowiredFieldElement,而當前element 真實類型是 TestController.checkRuleService 的集合。
我們進入AutowiredFieldElement#inject方法,首先嘗試從緩存里拿當前Field的值,肯定拿不到,所以走的是else分支,else分支里從beanFactory里解析當前Field屬性值
value = AutowiredAnnotationBeanPostProcessor.this.beanFactory.resolveDependency(desc, beanName, autowiredBeanNames, typeConverter);
繼續跟進去,發現其實調用的 doResolveDependency 方法
越來越接近真相了,不要着急,繼續跟進去
發現一個類型為Object的 multipleBeans ,結果返回的也是這個Object,我們大膽猜測這個Object就是我們需要注入的List屬性,繼續跟進去驗證一下:
我們看一下 Collection 分支的源碼
else if (Collection.class.isAssignableFrom(type) && type.isInterface()) { elementType = descriptor.getResolvableType().asCollection().resolveGeneric(new int[0]); if (elementType == null) { return null; } else { Map<String, Object> matchingBeans = this.findAutowireCandidates(beanName, elementType, new DefaultListableBeanFactory.MultiElementDescriptor(descriptor)); if (matchingBeans.isEmpty()) { return null; } else { if (autowiredBeanNames != null) { autowiredBeanNames.addAll(matchingBeans.keySet()); } TypeConverter converter = typeConverter != null ? typeConverter : this.getTypeConverter(); Object result = converter.convertIfNecessary(matchingBeans.values(), type); if (this.getDependencyComparator() != null && result instanceof List) { ((List)result).sort(this.adaptDependencyComparator(matchingBeans)); } return result; } } }
裏面是調用了 findAutowireCandidates 來獲取Bean,findAutowireCandidates 內部會獲取到依賴的BeanNames,然後根據beanName 循環調用beanFactory#getBean 獲取需要注入的bean
this.findAutowireCandidates(beanName,elementType,new DefaultListableBeanFactory.MultiElementDescriptor(descriptor))beanFactory#getBean方法,最終會調用 AbstractBeanFactory#doGetBean,獲取到需要裝配進去的屬性bean。
public Object resolveCandidate(String beanName, Class<?> requiredType, BeanFactory beanFactory) throws BeansException { return beanFactory.getBean(beanName); }
當所有的循環執行完畢,就獲取到了 multipleBeans ,驗證了前面的猜測。真是太不容易,趕緊設置緩存
最終通過field.set 將獲取到的List屬性值value設置到當前bean里,代碼如下:
if (value != null) { ReflectionUtils.makeAccessible(field); field.set(bean, value); }
執行field的set方法后,再來看checkRuleService屬性就有值了
如果是Method注入,對應的就是通過反射調用 method.invoke 將屬性設置到方法參數里,大致流程差不多。到此,Autowired 裝配流程也就結束了。
前面在講到 populateBean 的時候,有個根據 autowireMode 判斷是否執行屬性注入,當時獲取的autowireMode==0,那麼什麼時候autowireMode 會有值並且會根據autowireByName 和 autowireByType來裝配呢?
protected void populateBean(String beanName, RootBeanDefinition mbd, @Nullable BeanWrapper bw)其實也很好理解,通過源碼我們知道,這裏的 mbd 是一個 RootBeanDefinition ,也就是說這裏的 mbd.getResolvedAutowireMode()獲取的值是通過Bean定義或者通過PostProcessor拿到BeanDefinition,然後設置了AutowireMode屬性才會有值。當我們查看這裏的autowireByType源碼(AbstractAutowireCapableBeanFactory#autowireByType)可以發現,其實autowireByType也是會調用resolveDependency,繼續跟進去,發現其實調用的 doResolveDependency 方法,而AutowiredAnnotationBeanPostProcessor 也是通過這個方法實現的自動注入,後面的流程就都一樣了。
1、bean創建完成后,會調用 populateBean() 填充Bean,在populateBean()方法里會獲取所有的BeanPostProcessor,並循環執行 BeanPostProcessor#postProcessPropertyValues() 設置屬性
2、其中有個AutowiredAnnotationBeanPostProcessor,這個處理器里會根據當前Bean的Class,通過反射獲取 Field 和 Method ,分別獲取 Field 和 Method 上的自動注入的註解(@Autowired 和 @Value),構建注入元數據InjectionMetadata
3、調用注入元數據InjectionMetadata的 inject() 方法,裝配屬性(有兩種:AutowiredFieldElement 和AutowiredMethodElement),會調用this.beanFactory.resolveDependency(desc,beanName,autowiredBeanNames, typeConverter) 解析依賴的屬性值
4、resolveDependency 最終會調用到 resolveMultipleBeans ,而 resolveMultipleBeans 會根據當前注入屬性的類型分別按 Array、Collection、Map 走不同的分支,在分支里調用 findAutowireCandidates 獲取注入bean的實例,最終回調到 AbstractBeanFactory#doGetBean
5、獲取到所有需要注入的屬性 bean 實例后,通過反射設置到對應的屬性或方法里去,就完成了自動注入全流程了
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※台北網頁設計公司全省服務真心推薦
※想知道最厲害的網頁設計公司"嚨底家"!
※推薦評價好的iphone維修中心
※網頁設計最專業,超強功能平台可客製化
※別再煩惱如何寫文案,掌握八大原則!
先預先說明,我這邊jdk的代碼版本為1.8.0_11,同時,因為我直接在本地jdk源碼上進行了部分修改、調試,所以,導致大家看到的我這邊貼的代碼,和大家的不太一樣。
不過,我對源碼進行修改、重構時,會保證和原始代碼的功能、邏輯嚴格一致,更多時候,可能只是修改變量名,方便理解。
大家也知道,jdk代碼寫得實在是比較深奧,變量名經常都是單字符,i,j,k啥的,實在是很難理解,所以,我一般會根據自己的理解,去重命名,為了減輕我們的頭腦負擔。
至於怎麼去修改代碼並調試,可以參考我之前的文章:
曹工力薦:調試 jdk 中 rt.jar 包部分的源碼(可自由增加註釋,修改代碼並debug)
文章中,我改過的代碼放在:
https://gitee.com/ckl111/jdk-debug
大家知道,concurrentHashMap底層是數組+鏈表+紅黑樹,數組的長度假設為n,在hashmap初始化的時候,這個n除了作為數組長度,還會作為另一個關鍵field的值。
/**
* Table initialization and resizing control. When negative, the
* table is being initialized or resized: -1 for initialization,
* else -(1 + the number of active resizing threads). Otherwise,
* when table is null, holds the initial table size to use upon
* creation, or 0 for default. After initialization, holds the
* next element count value upon which to resize the table.
*/
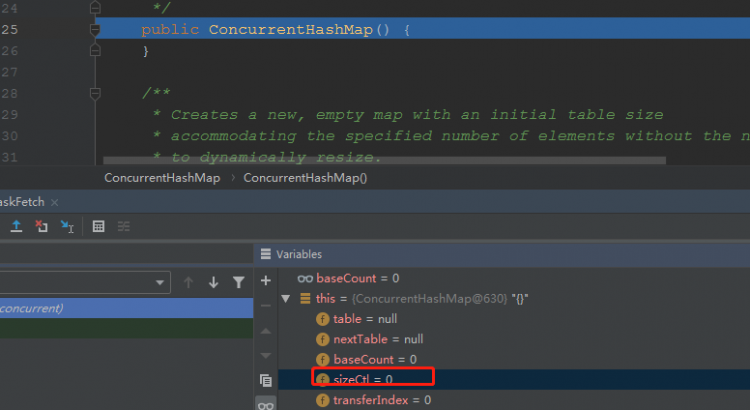
private transient volatile int sizeCtl;
該字段非常關鍵,根據取值不同,有不同的功能。
public ConcurrentHashMap() {
}
此時,sizeCtl被初始化為0.
此時,sizeCtl也是32,和容量一致。
public ConcurrentHashMap(Map<? extends K, ? extends V> m) {
this.sizeCtl = DEFAULT_CAPACITY;
putAll(m);
}
此時,sizeCtl,直接使用了默認值,16.
public ConcurrentHashMap(int initialCapacity, float loadFactor) {
this(initialCapacity, loadFactor, 1);
}
這裏重載了:
這裏,我們傳入的負載因子為0.75,這也是默認的負載因子,傳入的初始容量為14.
這裏面會根據: 1 + 14/0.75 = 19,拿到真正的size,然後根據size,獲取到第一個大於19的2的n次方,即32,來作為數組容量,然後sizeCtl也被設置為32.
實際上,new一個hashmap的時候,我們並沒有創建支撐數組,那,什麼時候創建數組呢?是在真正往裡面放數據的時候,比如put的時候。
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
ConcurrentHashMapPutResultVO vo = new ConcurrentHashMapPutResultVO();
vo.setBinCount(0);
for (Node<K,V>[] tab = table;;) {
int tableLength;
// 1
if (tab == null) {
tab = initTable();
continue;
}
...
}
1處,即會去初始化table。
/**
* Initializes table, using the size recorded in sizeCtl.
* 初始化hashmap,使用sizeCtl作為容量
*/
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
sc = sizeCtl;
if (sc < 0){
Thread.yield(); // lost initialization race; just spin
continue;
}
/**
* 走到這裏,說明sizeCtl大於0,大於0,代表什麼,可以去看下其構造函數,此時,sizeCtl表示
* capacity的大小。
* {@link #ConcurrentHashMap(int)}
*
* cas修改為-1,如果成功修改為-1,則表示搶到了鎖,可以進行初始化
*
*/
// 1
boolean bGotChanceToInit = U.compareAndSwapInt(this, SIZECTL, sc, -1);
if (bGotChanceToInit) {
try {
tab = table;
/**
* 如果當前表為空,尚未初始化,則進行初始化,分配空間
*/
if (tab == null || tab.length == 0) {
/**
* sc大於0,則以sc為準,否則使用默認的容量
*/
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
Node<K, V>[] nt = (Node<K, V>[]) new Node<?, ?>[n];
table = tab = nt;
/**
* n >>> 2,無符號右移2位,則是n的四分之一。
* n- n/4,結果為3/4 * n
* 則,這裏修改sc為 3/4 * n
* 比如,默認容量為16,則修改sc為12
*/
// 2
sc = n - (n >>> 2);
}
} finally {
/**
* 修改sizeCtl到field
*/
// 3
sizeCtl = sc;
}
break;
}
}
return tab;
}
經過上面的分析,initTable時,這個字段可能有兩種取值:
上面說的是,在put的時候去initTable,實際上,這個initTable,也會在以下函數中被調用,其共同點就是,都是往裡面放數據的操作:
上面說了很多,目前,我們知道的是,在initTable后,sizeCtl的值,是舊的數組的長度 * 0.75。
接下來,我們看看擴容時機,在put時,會調用putVal,這個函數的大體步驟:
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
// 1
int hash = spread(key.hashCode());
int binCount = 0;
System.out.println("binCount:" + binCount);
// 2
ConcurrentHashMapPutResultVO vo = new ConcurrentHashMapPutResultVO();
vo.setBinCount(0);
for (Node<K,V>[] tab = table;;) {
int tableLength;
// 3
if (tab == null) {
tab = initTable();
continue;
}
tableLength = tab.length;
if (tableLength == 0) {
tab = initTable();
continue;
}
int entryNodeHashCode;
// 4
int entryNodeIndex = (tableLength - 1) & hash;
Node<K,V> entryNode = tabAt(tab,entryNodeIndex);
/**
* 5 如果我們要放的桶,還是個空的,則直接cas放進去
*/
if (entryNode == null) {
Node<K, V> node = new Node<>(hash, key, value, null);
// no lock when adding to empty bin
boolean bSuccess = casTabAt(tab, entryNodeIndex, null, node);
if (bSuccess) {
break;
} else {
/**
* 如果沒成功,則繼續下一輪循環
*/
continue;
}
}
entryNodeHashCode = entryNode.hash;
/**
* 6 如果要放的這個桶,正在遷移,則幫助遷移
*/
if (entryNodeHashCode == MOVED){
tab = helpTransfer(tab, entryNode);
continue;
}
/**
* 7 對entryNode加鎖
*/
V oldVal = null;
System.out.println("sync");
synchronized (entryNode) {
/**
* 這一行是判斷,在我們執行前面的一堆方法的時候,看看entryNodeIndex處的node是否變化
*/
if (tabAt(tab, entryNodeIndex) != entryNode) {
continue;
}
/**
* 8 hashCode大於0,說明不是處於遷移狀態
*/
if (entryNodeHashCode >= 0) {
/**
* 9 鏈表中找到合適的位置並放入
*/
findPositionAndPut(key, value, onlyIfAbsent, hash, vo, entryNode);
binCount = vo.getBinCount();
oldVal = (V) vo.getOldValue();
}
else if (entryNode instanceof TreeBin) {
...
}
}
System.out.println("binCount:" + binCount);
// 10
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, entryNodeIndex);
if (oldVal != null)
return oldVal;
break;
}
}
// 11
addCount(1L, binCount);
return null;
}
1處,計算key的hashcode
2處,我這邊new了一個對象,裏面兩個字段:
public class ConcurrentHashMapPutResultVO<V> {
int binCount;
V oldValue;
}
其中,oldValue用來存放,如果put進去的key/value,其中key已經存在的話,一般會直接覆蓋之前的舊值,這裏主要存放之前的舊值,因為我們需要返回舊值。
binCount,則存放:在找到對應的hash桶之後,在鏈表中,遍歷了多少個元素,該值後面會使用,作為一個標誌,當該標誌大於0的時候,才去進一步檢查,看看是否擴容。
3處,如果table為null,說明table里沒有任何一個鍵值對,數組也還沒創建,則初始化table
4處,根據hashcode,和(數組長度 – 1)相與,計算出應該存放的哈希桶在數組中的索引
5處,如果要放的哈希桶,還是空的,則直接cas設置進去,成功則跳出循環,否則重試
6處,如果要放的這個桶,該節點的hashcode為MOVED(一個常量,值為-1),說明有其他線程正在擴容該hashmap,則幫助擴容
7處,對要存放的hash桶的頭節點加鎖
8處,如果頭節點的hashcode大於0,說明是拉了一條鏈表,則調用子方法(我這邊自己抽的),去找到合適的位置並插入到鏈表
9處,findPositionAndPut,在鏈表中,找到合適的位置,並插入
10處,在findPositionAndPut函數中,會返回:為了找到合適的位置,遍歷了多少個元素,這個值,就是binCount。
如果這個binCount大於8,則說明遍歷了8個元素,則需要轉紅黑樹了。
11處,因為我們新增了一個元素,總數自然要加1,這裏面會去增加總數,和檢查是否需要擴容。
其中,第9步,因為是自己抽的函數,所以這裏貼出來給大家看下:
/**
* 遍歷鏈表,找到應該放的位置;如果遍歷完了還沒找到,則放到最後
* @param key
* @param value
* @param onlyIfAbsent
* @param hash
* @param vo
* @param entryNode
*/
private void findPositionAndPut(K key, V value, boolean onlyIfAbsent, int hash, ConcurrentHashMapPutResultVO vo, Node<K, V> entryNode) {
vo.setBinCount(1);
for (Node<K,V> currentIterateNode = entryNode;
;
vo.setBinCount(vo.getBinCount() + 1)) {
/**
* 如果當前遍歷指向的節點的hash值,與參數中的key的hash值相等,則,
* 繼續判斷
*/
K currentIterateNodeKey = currentIterateNode.key;
boolean bKeyEqualOrNot = Objects.equals(currentIterateNodeKey, key);
/**
* key的hash值相等,且equals比較也相等,則就是我們要找的
*/
if (currentIterateNode.hash == hash && bKeyEqualOrNot) {
/**
* 獲取舊的值
*/
vo.setOldValue(currentIterateNode.val);
/**
* 覆蓋舊的node的val
*/
if (!onlyIfAbsent)
currentIterateNode.val = value;
// 這裏直接break跳出循環
break;
}
/**
* 把當前節點保存起來
*/
Node<K,V> pred = currentIterateNode;
/**
* 獲取下一個節點
*/
currentIterateNode = currentIterateNode.next;
/**
* 如果下一個節點為null,說明當前已經是鏈表的最後一個node了
*/
if ( currentIterateNode == null) {
/**
* 則在當前節點後面,掛上新的節點
*/
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
第11步,也是我們要看的重點:
private final void addCount(long delta, int check) {
CounterCell[] counterCellsArray = counterCells;
// 1
long b = baseCount;
// 2
long newBaseCount = b + delta;
/**
* 3 直接cas在baseCount上增加
*/
boolean bSuccess = U.compareAndSwapLong(this, BASECOUNT, b, newBaseCount);
if ( counterCellsArray != null || !bSuccess) {
...
newBaseCount = sumCount();
}
// 4
if (check >= 0) {
while (true) {
Node<K,V>[] tab = table;
Node<K,V>[] nt;
int n = 0;
// 5
int sc = sizeCtl;
// 6
boolean bSumExteedSizeControl = newBaseCount >= (long) sc;
// 7
boolean bContinue = bSumExteedSizeControl && tab != null && (n = tab.length) < MAXIMUM_CAPACITY;
if (bContinue) {
int rs = resizeStamp(n);
if (sc < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
} else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
// 8
transfer(tab, null);
newBaseCount = sumCount();
} else {
break;
}
}
}
}
1處,baseCount是一個field,存儲當前hashmap中,有多少個鍵值對,你put一次,就一個;remove一次,就減一個。
2處,b + delta,其中,b就是baseCount,是舊的數量;dalta,我們傳入的是1,就是要增加的元素數量
所以,b + delta,得到的,就是經過這次put后,預期的數量
3處,直接cas,修改baseCount這個field為 新值,也就是第二步拿到的值。
4處,這裏檢查check是否大於0,check,是第二個形參;這個參數,我們外邊怎麼傳的?
addCount(1L, binCount);
不就是bincount嗎,也就是說,這裏檢查:我們在put過程中,在鏈表中遍歷了幾個元素,如果遍歷了至少1個元素,這裏要進入下面的邏輯:檢查是否要擴容,因為,你binCount大於0,說明可能已經開始出現哈希衝突了。
5處,取field:sizeCtl的值,給局部變量sc
6處,判斷當前的新的鍵值對總數,是否大於sc了;比如容量是16,那麼sizeCtl是12,如果此時,hashmap中存放的鍵值對已經大於等於12了,則要檢查是否擴容了
7處,幾個組合條件,查看是否要擴容,其中,主要的條件就是第6步的那個。
8處,調用transfer,進行擴容
總結一下,經過前面的第6處,我們知道,如果存放的鍵值對總數,已經大於等於0.75*哈希桶(也就是底層數組的長度)的數量了,那麼,就基本要擴容了。
擴容也是一個相對複雜的過程,這裏只說大概,詳細的放下講。
假設,現在底層數組長度,128,也就是128個哈希桶,當存放的鍵值對數量,大於等於 128 * 0.75的時候,就會開始擴容,擴容的過程,大概是:
這個過程,昨天的博文,畫了個圖,這裏再貼一下。
擴容后:
可是,如果我們要一個個去遍歷所有哈希桶,然後遍歷對應的鏈表/紅黑樹,會不會太慢了?完全是單線程工作啊。
換個思路,我們能不能加快點呢?比如,線程1可以去處理數組的 0 -15這16個桶,16- 31這16個桶,完全可以讓線程2去做啊,這樣的話,不就多線程了嗎,不是就快了嗎?
沒錯,jdk就是這麼乾的。
jdk維護了一個field,這個field,專門用來存當前可以獲取的任務的索引,舉個例子:
大家看上圖就懂了,一開始,這裏假設我們有128個桶,每次每個線程,去拿16個桶來處理。
剛開始的時候,field:transferIndex就等於127,也就是最後一個桶的位置,然後我們要從后往前取,那麼,127 到112,剛好就是16個桶,所以,申請任務的時候,就會用cas去更新field為112,則表示,自己取到了112 到127這一個區間的hash桶遷移任務。
如果自始至終,只有一個線程呢,它處理完了112 – 127這一批hash桶后,會繼續取下一波任務,96 – 112;以此類推。
如果多線程的話呢,也是類似的,反正都是去嘗試cas更新transferIndex的值為任務區間的開始下標的值,成功了,就算任務認領成功了。
多線程,怎麼知道需要去幫助擴容呢? 發起擴容的線程,在處理完bucket[k]時,會把老的table中的對應的bucket[k]的頭節點,修改為下面這種類型的節點:
static final class ForwardingNode<K,V> extends Node<K,V> {
final Node<K,V>[] nextTable;
ForwardingNode(Node<K,V>[] tab) {
super(MOVED, null, null, null);
this.nextTable = tab;
}
}
其他線程,在put或者其他操作時,發現頭結點變成了這個,就會去協助擴容了。
我個人感覺,差別不大,多線程擴容,就是多線程去獲取自己的那一段任務,然後來完成。我這邊寫了簡單的demo,不過感覺還是很有用的,可以幫助我們理解。
import sun.misc.Unsafe;
import java.lang.reflect.Field;
import java.util.concurrent.*;
import java.util.concurrent.locks.LockSupport;
public class ConcurrentTaskFetch {
/**
* 空閑任務索引,獲取任務時,從該下標開始,往前獲取。
* 比如當前下標為10,表示tasks數組中,0-10這個區間的任務,沒人領取
*/
// 0
private volatile int freeTaskIndexForFetch;
// 1
private static final int TASK_COUNT_PER_FETCH = 16;
// 2
private String[] tasks = new String[128];
public static void main(String[] args) {
ConcurrentTaskFetch fetch = new ConcurrentTaskFetch();
// 3
fetch.init();
ThreadPoolExecutor executor = new ThreadPoolExecutor(10, 10, 60, TimeUnit.SECONDS, new ArrayBlockingQueue<>(100));
executor.prestartAllCoreThreads();
CyclicBarrier cyclicBarrier = new CyclicBarrier(10);
// 4
for (int i = 0; i < 10; i++) {
executor.execute(new Runnable() {
@Override
public void run() {
try {
cyclicBarrier.await();
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
// 5
FetchedTaskInfo fetchedTaskInfo = fetch.fetchTask();
if (fetchedTaskInfo != null) {
System.out.println("thread:" + Thread.currentThread().getName() + ",get task success:" + fetchedTaskInfo);
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("thread:" + Thread.currentThread().getName() + ", process task finished");
}
}
});
}
LockSupport.park();
}
public void init() {
for (int i = 0; i < 128; i++) {
tasks[i] = "task" + i;
}
freeTaskIndexForFetch = tasks.length;
}
// 6
public FetchedTaskInfo fetchTask() {
System.out.println("Thread start fetch task:"+Thread.currentThread().getName()+",time: "+System.currentTimeMillis());
while (true){
// 6.1
if (freeTaskIndexForFetch == 0) {
System.out.println("thread:" + Thread.currentThread().getName() + ",get task failed,there is no task");
return null;
}
/**
* 6.2 獲取當前任務的集合的上界
*/
int subTaskListEndIndex = this.freeTaskIndexForFetch;
/**
* 6.3 獲取當前任務的集合的下界
*/
int subTaskListStartIndex = subTaskListEndIndex > TASK_COUNT_PER_FETCH ?
subTaskListEndIndex - TASK_COUNT_PER_FETCH : 0;
/**
* 6.4
* 現在,我們拿到了集合的上下界,即[subTaskListStartIndex,subTaskListEndIndex)
* 該區間為前開后閉,所以,實際的區間為:
* [subTaskListStartIndex,subTaskListEndIndex - 1]
*/
/**
* 6.5 使用cas,嘗試更新{@link freeTaskIndexForFetch} 為 subTaskListStartIndex
*/
if (U.compareAndSwapInt(this, FREE_TASK_INDEX_FOR_FETCH, subTaskListEndIndex, subTaskListStartIndex)) {
// 6.6
FetchedTaskInfo info = new FetchedTaskInfo();
info.setStartIndex(subTaskListStartIndex);
info.setEndIndex(subTaskListEndIndex - 1);
return info;
}
}
}
// Unsafe mechanics
private static final sun.misc.Unsafe U;
private static final long FREE_TASK_INDEX_FOR_FETCH;
static {
try {
// U = sun.misc.Unsafe.getUnsafe();
Field f = Unsafe.class.getDeclaredField("theUnsafe");
f.setAccessible(true);
U = (Unsafe) f.get(null);
Class<?> k = ConcurrentTaskFetch.class;
FREE_TASK_INDEX_FOR_FETCH = U.objectFieldOffset
(k.getDeclaredField("freeTaskIndexForFetch"));
} catch (Exception e) {
throw new Error(e);
}
}
static class FetchedTaskInfo{
int startIndex;
int endIndex;
public int getStartIndex() {
return startIndex;
}
public void setStartIndex(int startIndex) {
this.startIndex = startIndex;
}
public int getEndIndex() {
return endIndex;
}
public void setEndIndex(int endIndex) {
this.endIndex = endIndex;
}
@Override
public String toString() {
return "FetchedTaskInfo{" +
"startIndex=" + startIndex +
", endIndex=" + endIndex +
'}';
}
}
}
0處,定義了一個field,類似於前面的transferIndex
/**
* 空閑任務索引,獲取任務時,從該下標開始,往前獲取。
* 比如當前下標為10,表示tasks數組中,0-10這個區間的任務,沒人領取
*/
// 0
private volatile int freeTaskIndexForFetch;
1,定義了每次取多少個任務,這裏也是16個
private static final int TASK_COUNT_PER_FETCH = 16;
2,定義任務列表,共128個任務
3,main函數中,進行任務初始化
public void init() {
for (int i = 0; i < 128; i++) {
tasks[i] = "task" + i;
}
freeTaskIndexForFetch = tasks.length;
}
主要初始化任務列表,其次,將freeTaskIndexForFetch 賦值為128,後續取任務,從這個下標開始
4處,啟動10個線程,每個線程去執行取任務,按理說,我們128個任務,每個線程取16個,只能有8個線程取到任務,2個線程取不到
5處,線程邏輯里,去獲取任務
6處,獲取任務的方法定義
6.1 ,如果可獲取的任務索引為0了,說明沒任務了,直接返回
6.2,獲取當前任務的集合的上界
6.3,獲取當前任務的集合的下界,減去16就行了
6.4,拿到了集合的上下界,即[subTaskListStartIndex,subTaskListEndIndex)
6.5, 使用cas,更新field為:6.4中的任務下界。
執行效果演示:
可以看到,8個線程取到任務,2個線程沒取到。
其實jvm內存分配時,也是類似的思路,比如,設置堆內存為200m,那這200m是啟動時立馬從操作系統分配了的。
接下來,就是每次new對象的時候,去這個大內存里,找個小空間,這個過程,也是需要cas去競爭的,比如肯定也有個全局的字段,來表示當前可用內存的索引,比如該索引為100,表示,第100個字節后的空間是可以用的,那我要new個對象,這個對象有3個字段,需要大概30個字節,那我是不是需要把這個索引更新為130。
這中間是多線程的,所以也是要cas操作。
道理都是類似的。
時間倉促,有問題在所難免,歡迎及時指出或加群討論。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準
※網頁設計最專業,超強功能平台可客製化
※別再煩惱如何寫文案,掌握八大原則!

目錄
為什麼需要消息隊列
1.異步 :一個下單流程,你需要扣積分,扣優惠卷,發短信等,有些耗時又不需要立即處理的事,可以丟到隊列里異步處理。
2.削峰 :按平常的流量,服務器剛好可以正常負載。偶爾推出一個優惠活動時,請求量極速上升。由於服務器 Redis,MySQL 承受能力不一樣,如果請求全部接收,服務器負載不了會導致宕機。加機器嘛,需要去調整配置,活動結束後用不到了,即麻煩又浪費。這時可以將請求放到隊列里,按照服務器的能力去消費。
3.解耦 :一個訂單流程,需要扣積分,優惠券,發短信等調用多個接口,出現問題時不好排查。像發短信有很多地方需要用到, 如果哪天修改了短信接口參數,用到的地方都得修改。這時可以將要發送的內容放到隊列里,起一個服務去消費, 統一發送短信。
高吞吐、高可用 MQ 對比分析
看了幾個招聘網站,提到較多的消息隊列有:RabbitMQ、RocketMQ、Kafka 以及 Redis 的消息隊列和發布訂閱模式。
Redis 隊列是用 List 數據結構模擬的,指定一端 Push,另一端 Pop,一條消息只能被一個程序所消費。如果要一對多消費的,可以用 Redis 的發布訂閱模式。Redis 發布訂閱是實時消費的,服務端不會保存生產的消息,也不會記錄客戶端消費到哪一條。在消費的時候如果客戶端宕機了,消息就會丟失。這時就需要用到高級的消息隊列,如 RocketMQ、Kafka 等。
ZeroMQ 只有點對點模式和 Redis 發布訂閱模式差不多,如果不是對性能要求極高,我會用其它隊列代替,畢竟關解決開發環境所需的依賴庫就夠折騰的。
RabbitMQ 多語言支持比較完善,特性的支持也比較齊全,但是吞吐量相對小些,而且基於 Erlang 語言開發,不利於二次開發和維護。
RocketMQ 和 Kafka 性能差不多,基於 Topic 的訂閱模式。RocketMQ 支持分佈式事務,但在集群下主從不能自動切換,導致了一些小問題。RocketMQ 使用的集群是 Master-Slave ,在 Master 沒有宕機時,Slave 作為災備,空閑着機器。而 Kafka 採用的是 Leader-Slave 無狀態集群,每台服務器既是 Master 也是 Slave。
Kafka 相關概念
在高可用環境中,Kafka 需要部署多台,避免 Kafka 宕機后,服務無法訪問。Kafka集群中每一台 Kafka 機器就是一個 Broker。Kafka 主題名稱和 Leader 的選舉等操作需要依賴 ZooKeeper。
同樣地,為了避免 ZooKeeper 宕機導致服務無法訪問,ZooKeeper 也需要部署多台。生產者的數據是寫入到 Kafka 的 Leader 節點,Follower 節點的 Kafka 從 Leader 中拉取數據同步。在寫數據時,需要指定一個 Topic,也就是消息的類型。
一個主題下可以有多個分區,數據存儲在分區下。一個主題下也可以有多個副本,每一個副本都是這個主題的完整數據備份。Producer 生產消息,Consumer 消費消息。在沒給 Consumer 指定 Consumer Group 時會創建一個臨時消費組。Producer 生產的消息只能被同一個 Consumer Group 中的一個 Consumer 消費。
分區、副本、消費組
主題的數據會按分區數分散存到分區下,把這些分區數據加起來才是一個主題的完整的數據。分區數最好是副本數的整數倍,這樣每個副本分配到的分區數比較均勻。同一個分區寫入是有順序的,如果要保證全局有序,可以只設置一個分區。
如果分區數小於消費者數,前面的消費者會配到一個分區,後面超過分區數的消費者將無分區可消費,除非前面的消費者宕機了。如果分區數大於消費者數,每個消費者至少分配到一個分區的數據,一些分配到兩個分區。這時如果有新的消費者加入,會把有兩個分區的調一個分配到新的消費者。
分區數可以設置成 6、12 等數值。比如 6,當消費者只有一個時,這 6 個分區都歸這個消費者,後面再加入一個消費者時,每個消費者都負責 3 個分區,後面又加入一個消費者時,每個消費者就負責 2 個分區。每個消費者分配到的分區數是一樣的,可以均勻地消費。
主題的副本數即數據備份的個數,如果副本數為 1 , 即使 Kafka 機器有多個,當該副本所在的機器宕機后,對應的數據將訪問失敗。
集群模式下創建主題時,如果分區數和副本數都大於 1,主題會將分區 Leader 較均勻的分配在有副本的 Kafka 上。這樣客戶端在消費這個主題時,可以從多台機器上的 Kafka 消息數據,實現分佈式消費。
副本數不是越多越好,從節點需要從主節點拉取數據同步,一般設置成和 Kafka 機器數一樣即可。如果只需要用到高可用的話,可以採用 N+1 策略,副本數設置為 2,專門弄一台 Kafka 來備份數據。然後主題分佈存儲在 “N” 台 Kafka 上,”+1″ 台 Kafka 保存着完整的主題數據,作為備用服務。
Replicas 表示在哪些 Kafka 機器上有主題的副本,Isr 表示當前有副本的 Kafka 機器上還存活着的 Kafka 機器。主題分區中所涉及的 Leader Kafka 宕機時,會將宕機 Kafka 涉及的分區分配到其它可用的 Kafka 節點上。如下:
每一個消費組記錄者各個主題分區的消費偏移量,在消費的時候,如果沒有指定消費組,會默認創建一個臨時消費組。生產者生產的消息只能被同一消費組下某個消費者消費。如果想要一條消息可以被多個消費者消費,可以加入不同的消費組。
偏移量最大值,消息存儲策略
long 類型最大值是(2^63)-1 (為什麼要減一呢?第一位是符號位,正的有262,負的有262,其中+0 和 -0 是相等的 , 只不過有的語言把0算到負裏面,有的語言把0算到正裏面)。 偏移量是一個 long 類型,除去負數,包含0,其最大值為 2^62。
Kafka 配置項提供兩種策略, 一種是基於時間:log.retention.hours=168,另一種是基於大小:log.retention.bytes=1073741824 。符合條件的數據會被標記為待刪除,Kafka會在恰當的時候才真正刪除。
Zookeeper 上存的 Kafka 相關數據
如何確保消息只被消費一次
前面已經講到,同一主題里的分區數據,只能被相同消費組裡其中一個消費者消費。當有多個消費者同時消費同一主題時,將這些消費者都加入相同的消費組,這時生產者的消息只能被其中一個消費者消費。
重複消費和數據丟失問題
生產者發送消息成功后,不等 Kafka 同步完成的確認,繼續發送下一條消息。在發的過程中如果 Leader Kafka 宕機了,但生產者並不知情,發出去的信息 Kafka 就收不到,導致數據丟失。解決方案是將 Request.Required.Acks 設置為 -1,表示生產者等所有副本都確認收到后才發送下一條消息。
Request.Required.Acks=0 表示發送消息即完成發送,不等待確認(可靠性低,延遲小,最容易丟失消息)
Request.Required.Acks=1 表示當 Leader 提交同步完成后才發送下一條消息
消費者有兩種情況,一種是消費的時候自動提交偏移量導致數據丟失:拿到消息的同時偏移量加一,如果業務處理失敗,下一次消費的時候偏移量已經加一了,上一個偏移量的數據丟失了。
另一種是手動提交偏移量導致重複消費:等業務處理成功后再手動提交偏移量,有可能出現業務處理成功,偏移量提交失敗,那下一次消費又是同一條消息。
怎麼解決呢?這是一個 or 的問題,偏移量要麼自動提交要麼手動提交,對應的問題是要麼數據丟失要麼重複消費。如果消息要求實時性高,丟個一兩條沒關係的話可以選擇自動提交偏移量。如果消息一條都不能丟的話可以選擇手動提交偏移量,然後將業務設計成冪等,不管這條消息消費多少次最終和消費一次的結果一樣。
Linux Kafka 操作命令
Windows 可視化工具 Kafka Tool
123.207.79.96 ZooKeeper-Kafka-01
生產者和消費者使用代碼
訂閱號:偉洪winnie
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計最專業,超強功能平台可客製化
※回頭車貨運收費標準