鈣素
Canvas 是在HTML5中新增的標籤用於在網頁實時生成圖像,並且可以操作圖像內容,基本上它是一個可以用JavaScript操作的位圖。也就是說我們將通過JS完成畫圖而不是css。
canvas 默認布局為 inline-block,可以認為是一種特殊的圖片。
走起 ~
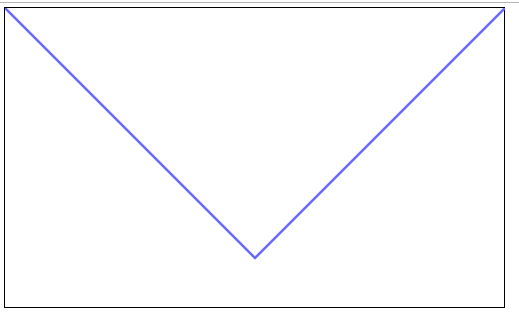
canvas 劃線
<canvas id="can" width="800" height="800"></canvas>
(寬高不能放在style裏面,否則比例不對)
canvas裏面的width和height相當於圖片的原始尺寸,加了外部style的寬高,就相當於對圖片進行壓縮和拉伸。
// 1、獲取原生dom對象
let dom = document.getElementById('can');
// 2、獲取繪圖對象
let can = dom.getContext('2d'); // 3d是webgl
// 定義線條起點
can.moveTo(0,0);
// 定義線條中點(非終點)
can.lineTo(400,400);
can.lineTo(800,0);
// 對標記範圍進行描邊
can.stroke()
// 對標記範圍進行填充
can.fill();
設置線條屬性
線條默認寬度是 1。
(一定要在繪圖之前設置。)
can.lineWidth = 2; //設置線條寬度
can.strokeStyle = '#f00'; // 設置線條顏色
can.fillStyle = '#f00'; // 設置填充區域顏色
折線樣式
miter:尖角(當尖角長度值過長時會自動變成折角,如果強制显示尖角:can.miterLimit = 100 設置尖角長度閾值。round:圓角bevel:折角
can.lineJoin = 'miter';
can.moveTo(100, 100);
can.lineTo(300, 100);
can.lineTo(100, 200);
can.stroke()
can.lineJoin = 'round';
can.moveTo(400, 100);
can.lineTo(600, 100);
can.lineTo(400, 200);
can.stroke()
can.lineJoin = 'bevel';
can.moveTo(700, 100);
can.lineTo(900, 100);
can.lineTo(700, 200);
can.stroke()
設置線帽
round:加圓角線帽square:加直角線帽butt:不加線帽
can.lineCap = 'round';
can.moveTo(100, 100);
can.lineTo(300, 100);
can.stroke()
// 新建繪圖,使得上一次的繪畫樣式不會影響下面的繪畫樣式(代碼加在上一次繪畫和下一次繪畫中間。)
can.beginPath()
can.lineCap = 'square';
can.moveTo(100, 200);
can.lineTo(300, 200);
can.stroke()
can.beginPath()
can.lineCap = 'butt';
can.moveTo(100, 300);
can.lineTo(300, 300);
can.stroke()
畫矩形
// 參數:x,y,寬,高
can.rect(100,100,100,100);
can.stroke();
// 畫完即填充
can.fillRect(100,100,100,100);
畫圓弧
// 參數:圓心x,圓心y,半徑,圓弧起點與圓心的夾角度數,圓弧終點與圓心的夾角度數,true(逆時針繪畫)
can.arc(500,300,200,0,2*Math.PI/360*90,false);
can.stroke()
示例:
can.moveTo(500,300);
can.lineTo(500 + Math.sqrt(100), 300 + Math.sqrt(100))
can.arc(500, 300, 100, 2 * Math.PI / 360 *startDeg, 2 * Math.PI / 360 *endDeg, false);
can.closePath()//將圖形起點和終點用線連接起來使之成為封閉的圖形
can.fill()
Tips:
1、can.beginPath() // 新建繪圖,使得上一次的繪畫樣式不會影響下面的繪畫樣式(代碼加在上一次繪畫和下一次繪畫中間。)
2、can.closePath() //將圖形起點和終點用線連接起來使之成為封閉的圖形。
旋轉畫布
can.rotate(2*Math.PI/360*45); // 一定要寫在開始繪圖之前
can.fillRect(0,0,200, 10);
旋轉整個畫布的坐標系(參考坐標為畫布的(0,0)位置)
縮放畫布
can.scale(0.5,2);
can.fillRect(0,0,200, 10);
示例:
整個畫布:x方向縮放為原來的0.5,y方向拉伸為原來的2倍。
畫布位移
can.translate(100,100)
can.fillRect(0,0,200, 10);
保存與恢復畫布狀態
can.save() // 存檔:保存當前畫布坐標系狀態
can.restore() // 讀檔:恢復之前保存的畫布坐標系狀態
需要正確坐標系繪圖的時候,再讀檔之前的正確坐標系。
can.restore() // 將當前的畫布坐標系狀態恢復成上一次保存時的狀態
can.fillRect(dom.width/2, dom.height/2, 300, 100)
指針時鐘(案例)
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>clock</title>
<style type="text/css">
#can {
width: 1000px;
height: 600px;
background: linear-gradient(45deg, green, skyblue);
}
</style>
</head>
<body>
<canvas id="can" width="2000" height="1200"></canvas>
</body>
<script type="text/javascript">
let dom = document.getElementById('can');
let can = dom.getContext('2d');
// 把畫布的圓心移動到畫布的中心
can.translate(dom.width / 2, dom.height / 2);
// 保存當前的畫布坐標系
can.save()
run();
function run() {
setInterval(function() {
clearCanvas();
draw();
}, 10);
}
// 繪圖
function draw() {
let time = new Date();
let hour = time.getHours();
let min = time.getMinutes();
let sec = time.getSeconds();
let minSec = time.getMilliseconds();
drawPannl();
drawHour(hour, min, sec);
drawMin(min, sec);
drawSec(sec, minSec);
drawPoint();
}
// 最簡單的方法:由於canvas每當高度或寬度被重設時,畫布內容就會被清空
function clearCanvas() {
dom.height = dom.height;
can.translate(dom.width / 2, dom.height / 2);
can.save()
}
// 畫錶盤
function drawPannl() {
can.beginPath();
can.restore()
can.save()
can.lineWidth = 10;
can.strokeStyle = 'skyblue';
can.arc(0, 0, 400, 0, 2 * Math.PI);
can.stroke();
for (let i = 0; i < 12; i++) {
can.beginPath();
can.lineWidth = 16;
can.strokeStyle = 'greenyellow';
can.rotate(2 * Math.PI / 12)
can.moveTo(0, -395);
can.lineTo(0, -340);
can.stroke();
}
for (let i = 0; i < 60; i++) {
can.beginPath();
can.lineWidth = 10;
can.strokeStyle = '#fff';
can.rotate(2 * Math.PI / 60)
can.moveTo(0, -395);
can.lineTo(0, -370);
can.stroke();
}
}
// 畫時針
function drawHour(h, m, s) {
can.beginPath();
can.restore()
can.save()
can.lineWidth = 24;
can.strokeStyle = 'palevioletred';
can.lineCap = 'round'
can.rotate(2 * Math.PI / (12 * 60 * 60) * (h * 60 * 60 + m * 60 + s))
can.moveTo(0, 0);
can.lineTo(0, -200);
can.stroke();
}
// 畫分針
function drawMin(m, s) {
can.beginPath();
can.restore()
can.save()
can.lineWidth = 14;
can.strokeStyle = '#09f';
can.lineCap = 'round'
can.rotate(2 * Math.PI / (60 * 60) * (m * 60 + s))
can.moveTo(0, 0);
can.lineTo(0, -260);
can.stroke();
}
// 畫秒針
function drawSec(s, ms) {
can.beginPath();
can.restore()
can.save()
can.lineWidth = 8;
can.strokeStyle = '#f00';
can.lineCap = 'round'
can.rotate(2 * Math.PI / (60 * 1000) * (s * 1000 + ms));
can.moveTo(0, 50);
can.lineTo(0, -320);
can.stroke();
}
// 畫中心點
function drawPoint() {
can.beginPath();
can.restore()
can.save()
can.lineWidth = 10;
can.fillStyle = 'red';
can.arc(0, 0, 12, 0, 2 * Math.PI);
can.fill();
}
</script>
</html>
圓弧時鐘(案例)
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>clock</title>
<style type="text/css">
#can {
width: 1000px;
height: 600px;
background: linear-gradient(45deg, rgb(94, 53, 6), black);
}
</style>
</head>
<body>
<canvas id="can" width="2000" height="1200"></canvas>
</body>
<script type="text/javascript">
let dom = document.getElementById('can');
let can = dom.getContext('2d');
// 把畫布的圓心移動到畫布的中心
can.translate(dom.width / 2, dom.height / 2);
// 保存當前的畫布坐標系
can.save();
// 圓形指針起始角度
let startDeg = 2 * Math.PI / 360 * 270;
run();
// draw();
function run() {
setInterval(function() {
clearCanvas();
draw();
}, 20);
}
// 繪圖
function draw() {
let time = new Date();
// let hour = time.getHours();
let hour = time.getHours() > 10 ? time.getHours() - 12 : time.getHours();
let min = time.getMinutes();
let sec = time.getSeconds();
let minSec = time.getMilliseconds();
drawPannl();
drawTime(hour, min, sec, minSec);
drawHour(hour, min, sec);
drawMin(min, sec);
drawSec(sec, minSec);
drawPoint();
}
// 最簡單的方法:由於canvas每當高度或寬度被重設時,畫布內容就會被清空
function clearCanvas() {
dom.height = dom.height;
can.translate(dom.width / 2, dom.height / 2);
can.save()
}
// 畫錶盤
function drawPannl() {
can.restore()
can.save()
// 設置時錶盤
can.beginPath();
can.lineWidth = 50;
can.strokeStyle = 'rgba(255,23,87,0.2)';
can.arc(0, 0, 400, 0, 2 * Math.PI);
can.stroke();
// 設置分錶盤
can.beginPath();
can.strokeStyle = 'rgba(169,242,15,0.2)';
can.arc(0, 0, 345, 0, 2 * Math.PI);
can.stroke();
// 設置秒錶盤
can.beginPath();
can.strokeStyle = 'rgba(21,202,230,0.2)';
can.arc(0, 0, 290, 0, 2 * Math.PI);
can.stroke();
// 小時刻度
// for (let i = 0; i < 12; i++) {
// can.beginPath();
// can.lineWidth = 16;
// can.strokeStyle = 'rgba(0,0,0,0.2)';
// can.rotate(2 * Math.PI / 12)
// can.moveTo(0, -375);
// can.lineTo(0, -425);
// can.stroke();
// }
// 分針刻度
// for (let i = 0; i < 60; i++) {
// can.beginPath();
// can.lineWidth = 10;
// can.strokeStyle = '#fff';
// can.rotate(2 * Math.PI / 60)
// can.moveTo(0, -395);
// can.lineTo(0, -370);
// can.stroke();
// }
}
// 畫時針
function drawHour(h, m, s) {
let rotateDeg = 2 * Math.PI / (12 * 60 * 60) * (h * 60 * 60 + m * 60 + s);
can.beginPath();
can.restore()
can.save()
// 時針圓弧
can.lineWidth = 50;
can.strokeStyle = 'rgb(255,23,87)';
can.lineCap = 'round';
can.shadowColor = "rgb(255,23,87)"; // 設置陰影顏色
can.shadowBlur = 20; // 設置陰影範圍
can.arc(0, 0, 400, startDeg, startDeg + rotateDeg);
can.stroke();
// 時針指針
can.beginPath();
can.lineWidth = 24;
can.strokeStyle = 'rgb(255,23,87)';
can.lineCap = 'round'
can.rotate(rotateDeg)
can.moveTo(0, 0);
can.lineTo(0, -100);
can.stroke();
}
// 畫分針
function drawMin(m, s) {
let rotateDeg = 2 * Math.PI / (60 * 60) * (m * 60 + s);
can.beginPath();
can.restore()
can.save()
// 分針圓弧
can.lineWidth = 50;
can.strokeStyle = 'rgb(169,242,15)';
can.lineCap = 'round'
can.shadowColor = "rgb(169,242,15)";
can.shadowBlur = 20;
can.arc(0, 0, 345, startDeg, startDeg + rotateDeg);
can.stroke();
// 分針指針
can.beginPath();
can.lineWidth = 14;
can.strokeStyle = 'rgb(169,242,15)';
can.lineCap = 'round'
can.rotate(rotateDeg)
can.moveTo(0, 0);
can.lineTo(0, -160);
can.stroke();
}
// 畫秒針
function drawSec(s, ms) {
let rotateDeg = 2 * Math.PI / (60 * 1000) * (s * 1000 + ms);
can.beginPath();
can.restore()
can.save()
can.lineWidth = 50;
can.strokeStyle = 'rgb(21,202,230)';
can.lineCap = 'round'
can.arc(0, 0, 290, startDeg, startDeg + rotateDeg);
can.stroke();
can.beginPath();
can.lineWidth = 8;
can.strokeStyle = 'rgb(21,202,230)';
can.lineCap = 'round'
can.shadowColor = "rgb(21,202,230)";
can.shadowBlur = 20;
can.rotate(rotateDeg);
can.moveTo(0, 50);
can.lineTo(0, -220);
can.stroke();
}
// 畫中心點
function drawPoint() {
can.beginPath();
can.restore()
can.save()
can.lineWidth = 10;
can.fillStyle = 'red';
can.arc(0, 0, 12, 0, 2 * Math.PI);
can.fill();
}
// 显示数字時鐘
function drawTime(h, m, s, ms) {
can.font = '60px Calibri';
can.fillStyle = '#0f0'
can.shadowColor = "#fff";
can.shadowBlur = 20;
can.fillText(`${h}:${m}:${s}.${ms}`, -140, -100);
}
</script>
</html>
(啾咪 ^.<)
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※高價3c回收,收購空拍機,收購鏡頭,收購 MACBOOK-更多收購平台討論專區
※評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
※收購3c瘋!各款手機、筆電、相機、平板,歡迎來詢價!
※智慧手機時代的來臨,RWD網頁設計已成為網頁設計推薦首選