作者 | 阿里巴巴技術專家 溪恆
一、需求來源
為什麼需要服務發現
在 K8s 集群裏面會通過 pod 去部署應用,與傳統的應用部署不同,傳統應用部署在給定的機器上面去部署,我們知道怎麼去調用別的機器的 IP 地址。但是在 K8s 集群裏面應用是通過 pod 去部署的, 而 pod 生命周期是短暫的。在 pod 的生命周期過程中,比如它創建或銷毀,它的 IP 地址都會發生變化,這樣就不能使用傳統的部署方式,不能指定 IP 去訪問指定的應用。
另外在 K8s 的應用部署里,之前雖然學習了 deployment 的應用部署模式,但還是需要創建一個 pod 組,然後這些 pod 組需要提供一個統一的訪問入口,以及怎麼去控制流量負載均衡到這個組裡面。比如說測試環境、預發環境和線上環境,其實在部署的過程中需要保持同樣的一個部署模板以及訪問方式。因為這樣就可以用同一套應用的模板在不同的環境中直接發布。
Service:Kubernetes 中的服務發現與負載均衡
最後應用服務需要暴露到外部去訪問,需要提供給外部的用戶去調用的。我們上節了解到 pod 的網絡跟機器不是同一個段的網絡,那怎麼讓 pod 網絡暴露到去給外部訪問呢?這時就需要服務發現。
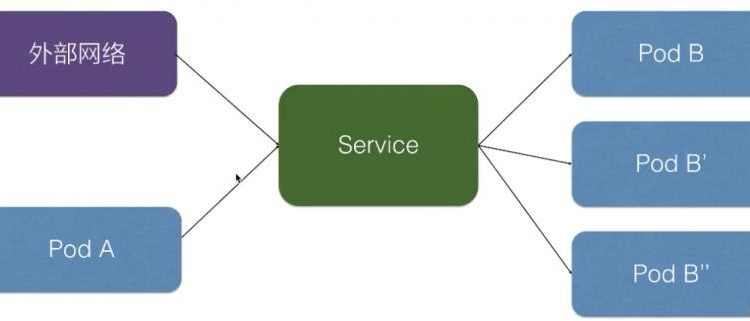
在 K8s 裏面,服務發現與負載均衡就是 K8s Service。上圖就是在 K8s 里 Service 的架構,K8s Service 向上提供了外部網絡以及 pod 網絡的訪問,即外部網絡可以通過 service 去訪問,pod 網絡也可以通過 K8s Service 去訪問。
向下,K8s 對接了另外一組 pod,即可以通過 K8s Service 的方式去負載均衡到一組 pod 上面去,這樣相當於解決了前面所說的複發性問題,或者提供了統一的訪問入口去做服務發現,然後又可以給外部網絡訪問,解決不同的 pod 之間的訪問,提供統一的訪問地址。
二、用例解讀
下面進行實際的一個用例解讀,看 pod K8s 的 service 要怎麼去聲明、怎麼去使用?
Service 語法
首先來看 K8s Service 的一個語法,上圖實際就是 K8s 的一個聲明結構。這個結構里有很多語法,跟之前所介紹的 K8s 的一些標準對象有很多相似之處。比如說標籤 label 去做一些選擇、selector 去做一些選擇、label 去聲明它的一些 label 標籤等。
這裡有一個新的知識點,就是定義了用於 K8s Service 服務發現的一個協議以及端口。繼續來看這個模板,聲明了一個名叫 my-service 的一個 K8s Service,它有一個 app:my-service 的 label,它選擇了 app:MyApp 這樣一個 label 的 pod 作為它的後端。
最後是定義的服務發現的協議以及端口,這個示例中我們定義的是 TCP 協議,端口是 80,目的端口是 9376,效果是訪問到這個 service 80 端口會被路由到後端的 targetPort,就是只要訪問到這個 service 80 端口的都會負載均衡到後端 app:MyApp 這種 label 的 pod 的 9376 端口。
創建和查看 Service
如何去創建剛才聲明的這個 service 對象,以及它創建之後是什麼樣的效果呢?通過簡單的命令:
- kubectl apply -f service.yaml
或者是
- kubectl created -f service.yaml
上面的命令可以簡單地去創建這樣一個 service。創建好之後,可以通過:
- kubectl discribe service
去查看 service 創建之後的一個結果。
service 創建好之後,你可以看到它的名字是 my-service。Namespace、Label、Selector 這些都跟我們之前聲明的一樣,這裏聲明完之後會生成一個 IP 地址,這個 IP 地址就是 service 的 IP 地址,這個 IP 地址在集群裏面可以被其它 pod 所訪問,相當於通過這個 IP 地址提供了統一的一個 pod 的訪問入口,以及服務發現。
這裏還有一個 Endpoints 的屬性,就是我們通過 Endpoints 可以看到:通過前面所聲明的 selector 去選擇了哪些 pod?以及這些 pod 都是什麼樣一個狀態?比如說通過 selector,我們看到它選擇了這些 pod 的一個 IP,以及這些 pod 所聲明的 targetPort 的一個端口。
實際的架構如上圖所示。在 service 創建之後,它會在集群裏面創建一個虛擬的 IP 地址以及端口,在集群里,所有的 pod 和 node 都可以通過這樣一個 IP 地址和端口去訪問到這個 service。這個 service 會把它選擇的 pod 及其 IP 地址都掛載到後端。這樣通過 service 的 IP 地址訪問時,就可以負載均衡到後端這些 pod 上面去。
當 pod 的生命周期有變化時,比如說其中一個 pod 銷毀,service 就會自動從後端摘除這個 pod。這樣實現了:就算 pod 的生命周期有變化,它訪問的端點是不會發生變化的。
集群內訪問 Service
在集群裏面,其他 pod 要怎麼訪問到我們所創建的這個 service 呢?有三種方式:
-
首先我們可以通過 service 的虛擬 IP 去訪問,比如說剛創建的 my-service 這個服務,通過 kubectl get svc 或者 kubectl discribe service 都可以看到它的虛擬 IP 地址是 172.29.3.27,端口是 80,然後就可以通過這個虛擬 IP 及端口在 pod 裏面直接訪問到這個 service 的地址。
-
第二種方式直接訪問服務名,依靠 DNS 解析,就是同一個 namespace 里 pod 可以直接通過 service 的名字去訪問到剛才所聲明的這個 service。不同的 namespace 裏面,我們可以通過 service 名字加“.”,然後加 service 所在的哪個 namespace 去訪問這個 service,例如我們直接用 curl 去訪問,就是 my- 就可以訪問到這個 service。
-
第三種是通過環境變量訪問,在同一個 namespace 里的 pod 啟動時,K8s 會把 service 的一些 IP 地址、端口,以及一些簡單的配置,通過環境變量的方式放到 K8s 的 pod 裏面。在 K8s pod 的容器啟動之後,通過讀取系統的環境變量比讀取到 namespace 裏面其他 service 配置的一個地址,或者是它的端口號等等。比如在集群的某一個 pod 裏面,可以直接通過 curl $ 取到一個環境變量的值,比如取到 MY_SERVICE_SERVICE_HOST 就是它的一個 IP 地址,MY_SERVICE 就是剛才我們聲明的 MY_SERVICE,SERVICE_PORT 就是它的端口號,這樣也可以請求到集群裏面的 MY_SERVICE 這個 service。
Headless Service
service 有一個特別的形態就是 Headless Service。service 創建的時候可以指定 clusterIP:None,告訴 K8s 說我不需要 clusterIP(就是剛才所說的集群裏面的一個虛擬 IP),然後 K8s 就不會分配給這個 service 一個虛擬 IP 地址,它沒有虛擬 IP 地址怎麼做到負載均衡以及統一的訪問入口呢?
它是這樣來操作的:pod 可以直接通過 service_name 用 DNS 的方式解析到所有後端 pod 的 IP 地址,通過 DNS 的 A 記錄的方式會解析到所有後端的 Pod 的地址,由客戶端選擇一個後端的 IP 地址,這個 A 記錄會隨着 pod 的生命周期變化,返回的 A 記錄列表也發生變化,這樣就要求客戶端應用要從 A 記錄把所有 DNS 返回到 A 記錄的列表裡面 IP 地址中,客戶端自己去選擇一個合適的地址去訪問 pod。
可以從上圖看一下跟剛才我們聲明的模板的區別,就是在中間加了一個 clusterIP:None,即表明不需要虛擬 IP。實際效果就是集群的 pod 訪問 my-service 時,會直接解析到所有的 service 對應 pod 的 IP 地址,返回給 pod,然後 pod 裏面自己去選擇一個 IP 地址去直接訪問。
向集群外暴露 Service
前面介紹的都是在集群裏面 node 或者 pod 去訪問 service,service 怎麼去向外暴露呢?怎麼把應用實際暴露給公網去訪問呢?這裏 service 也有兩種類型去解決這個問題,一個是 NodePort,一個是 LoadBalancer。
-
NodePort 的方式就是在集群的 node 上面(即集群的節點的宿主機上面)去暴露節點上的一個端口,這樣相當於在節點的一個端口上面訪問到之後就會再去做一層轉發,轉發到虛擬的 IP 地址上面,就是剛剛宿主機上面 service 虛擬 IP 地址。
-
LoadBalancer 類型就是在 NodePort 上面又做了一層轉換,剛才所說的 NodePort 其實是集群裏面每個節點上面一個端口,LoadBalancer 是在所有的節點前又掛一個負載均衡。比如在阿里雲上掛一個 SLB,這個負載均衡會提供一個統一的入口,並把所有它接觸到的流量負載均衡到每一個集群節點的 node pod 上面去。然後 node pod 再轉化成 ClusterIP,去訪問到實際的 pod 上面。
三、操作演示
下面進行實際操作演示,在阿里雲的容器服務上面進去體驗一下如何使用 K8s Service。
創建 Service
我們已經創建好了一個阿里雲的容器集群,然後並且配置好本地終端到阿里雲容器集群的一個連接。
首先可以通過 kubectl get cs ,可以看到我們已經正常連接到了阿里雲容器服務的集群上面去。
今天將通過這些模板實際去體驗阿里雲服務上面去使用 K8s Service。有三個模板,首先是 client,就是用來模擬通過 service 去訪問 K8s 的 service,然後負載均衡到我們的 service 裏面去聲明的一組 pod 上。
K8s Service 的上面,跟剛才介紹一樣,我們創建了一個 K8s Service 模板,裏面 pod,K8s Service 會通過前端指定的 80 端口負載均衡到後端 pod 的 80 端口上面,然後 selector 選擇到 run:nginx 這樣標籤的一些 pod 去作為它的後端。
然後去創建帶有這樣標籤的一組 pod,通過什麼去創建 pod 呢?就是之前所介紹的 K8s deployment,通過 deployment 我們可以輕鬆創建出一組 pod,然後上面聲明 run:nginx 這樣一個label,並且它有兩個副本,會同時跑出來兩個 pod。
先創建一組 pod,就是創建這個 K8s deployment,通過 kubectl create -f service.yaml。這個 deployment 也創建好了,再看一下 pod 有沒有創建出來。如下圖看到這個 deployment 所創建的兩個 pod 都已經在 running 了。通過 kubectl get pod -o wide 可以看到 IP 地址。通過 -l,即 label 去做篩選,run=nginx。如下圖所示可以看到,這兩個 pod 分別是 10.0.0.135 和 10.0.0.12 這樣一個 IP 地址,並且都是帶 run=nginx 這個 label 的。
下面我們去創建 K8s service,就是剛才介紹的通過 service 去選擇這兩個 pod。這個 service 已經創建好了。
根據剛才介紹,通過 kubectl describe svc 可以看到這個 service 實際的一個狀態。如下圖所示,剛才創建的 nginx service,它的選擇器是 run=nginx,通過 run=nginx 這個選擇器選擇到後端的 pod 地址,就是剛才所看到那兩個 pod 的地址:10.0.0.12 和 10.0.0.135。這裏可以看到 K8s 為它生成了集群裏面一個虛擬 IP 地址,通過這個虛擬 IP 地址,它就可以負載均衡到後面的兩個 pod 上面去。
現在去創建一個客戶端的 pod 實際去感受一下如何去訪問這個 K8s Service,我們通過 client.yaml 去創建客戶端的 pod,kubectl get pod 可以看到客戶端 pod 已經創建好並且已經在運行中了。
通過 kubectl exec 到這個 pod 裏面,進入這個 pod 去感受一下剛才所說的三種訪問方式,首先可以直接去訪問這個 K8s 為它生成的這個 ClusterIP,就是虛擬 IP 地址,通過 curl 訪問這個 IP 地址,這個 pod 裏面沒有裝 curl。通過 wget 這個 IP 地址,輸入進去測試一下。可以看到通過這個去訪問到實際的 IP 地址是可以訪問到後端的 nginx 上面的,這個虛擬是一個統一的入口。
第二種方式,可以通過直接 service 名字的方式去訪問到這個 service。同樣通過 wget,訪問我們剛才所創建的 service 名 nginx,可以發現跟剛才看到的結果是一樣的。
在不同的 namespace 時,也可以通過加上 namespace 的一個名字去訪問到 service,比如這裏的 namespace 為 default。
最後我們介紹的訪問方式裏面還可以通過環境變量去訪問,在這個 pod 裏面直接通過執行 env 命令看一下它實際注入的環境變量的情況。看一下 nginx 的 service 的各種配置已經註冊進來了。
可以通過 wget 同樣去訪問這樣一個環境變量,然後可以訪問到我們的一個 service。
介紹完這三種訪問方式,再看一下如何通過 service 外部的網絡去訪問。我們 vim 直接修改一些剛才所創建的 service。
最後我們添加一個 type,就是 LoadBalancer,就是我們前面所介紹的外部訪問的方式。
然後通過 kubectl apply,這樣就把剛剛修改的內容直接生效在所創建的 service 裏面。
現在看一下 service 會有哪些變化呢?通過 kubectl get svc -o wide,我們發現剛剛創建的 nginx service 多了一個 EXTERNAL-IP,就是外部訪問的一個 IP 地址,剛才我們所訪問的都是 CLUSTER-IP,就是在集群裏面的一個虛擬 IP 地址。
然後現在實際去訪問一下這個外部 IP 地址 39.98.21.187,感受一下如何通過 service 去暴露我們的應用服務,直接在終端裏面點一下,這裏可以看到我們直接通過這個應用的外部訪問端點,可以訪問到這個 service,是不是很簡單?
我們最後再看一下用 service 去實現了 K8s 的服務發現,就是 service 的訪問地址跟 pod 的生命周期沒有關係。我們先看一下現在的 service 後面選擇的是這兩個 pod IP 地址。
我們現在把其中的一個 pod 刪掉,通過 kubectl delete 的方式把前面一個 pod 刪掉。
我們知道 deployment 會讓它自動生成一個新的 pod,現在看 IP 地址已經變成 137。
現在再去 describe 一下剛才的 service,如下圖,看到前面訪問端點就是集群的 IP 地址沒有發生變化,對外的 LoadBalancer 的 IP 地址也沒有發生變化。在所有不影響客戶端的訪問情況下,後端的一個 pod IP 已經自動放到了 service 後端裏面。
這樣就相當於在應用的組件調用的時候可以不用關心 pod 在生命周期的一個變化。
以上就是所有演示。
四、架構設計
最後是對 K8s 設計的一個簡單的分析以及實現的一些原理。
Kubernetes 服務發現架構
如上圖所示,K8s 服務發現以及 K8s Service 是這樣整體的一個架構。
K8s 分為 master 節點和 worker 節點:
- master 裏面主要是 K8s 管控的內容;
- worker 節點裏面是實際跑用戶應用的一個地方。
在 K8s master 節點裏面有 APIServer,就是統一管理 K8s 所有對象的地方,所有的組件都會註冊到 APIServer 上面去監聽這個對象的變化,比如說我們剛才的組件 pod 生命周期發生變化,這些事件。
這裏面最關鍵的有三個組件:
- 一個是 Cloud Controller Manager,負責去配置 LoadBalancer 的一個負載均衡器給外部去訪問;
- 另外一個就是 Coredns,就是通過 Coredns 去觀測 APIServer 裏面的 service 後端 pod 的一個變化,去配置 service 的 DNS 解析,實現可以通過 service 的名字直接訪問到 service 的虛擬 IP,或者是 Headless 類型的 Service 中的 IP 列表的解析;
- 然後在每個 node 裏面會有 kube-proxy 這個組件,它通過監聽 service 以及 pod 變化,然後實際去配置集群裏面的 node pod 或者是虛擬 IP 地址的一個訪問。
實際訪問鏈路是什麼樣的呢?比如說從集群內部的一個 Client Pod3 去訪問 Service,就類似於剛才所演示的一個效果。Client Pod3 首先通過 Coredns 這裏去解析出 ServiceIP,Coredns 會返回給它 ServiceName 所對應的 service IP 是什麼,這個 Client Pod3 就會拿這個 Service IP 去做請求,它的請求到宿主機的網絡之後,就會被 kube-proxy 所配置的 iptables 或者 IPVS 去做一層攔截處理,之後去負載均衡到每一個實際的後端 pod 上面去,這樣就實現了一個負載均衡以及服務發現。
對於外部的流量,比如說剛才通過公網訪問的一個請求。它是通過外部的一個負載均衡器 Cloud Controller Manager 去監聽 service 的變化之後,去配置的一個負載均衡器,然後轉發到節點上的一個 NodePort 上面去,NodePort 也會經過 kube-proxy 的一個配置的一個 iptables,把 NodePort 的流量轉換成 ClusterIP,緊接着轉換成後端的一個 pod 的 IP 地址,去做負載均衡以及服務發現。這就是整個 K8s 服務發現以及 K8s Service 整體的結構。
後續進階
後續再進階部分我們還會更加深入地去講解 K8s Service 的實現原理,以及在 service 網絡出問題之後,如何去診斷以及去修復的技巧。
本文總結
本文的主要內容就到此為止了,這裏為大家簡單總結一下:
- 為什麼雲原生的場景需要服務發現和負載均衡,
- 在 Kubernetes 中如何使用 Kubernetes 的 Service 做服務發現和負載均衡
- Kubernetes 集群中 Service 涉及到的組件和大概實現原理
相信經過本文的學習與把握,大家能夠通過 Kubernetes Service 將複雜的企業級應用快速並標準地編排起來。
“阿里巴巴雲原生微信公眾號(ID:Alicloudnative)關注微服務、Serverless、容器、Service Mesh等技術領域、聚焦雲原生流行技術趨勢、雲原生大規模的落地實踐,做最懂雲原生開發者的技術公眾號。”
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※收購3c,收購IPHONE,收購蘋果電腦-詳細收購流程一覽表
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想要讓你的商品成為最夯、最多人討論的話題?網頁設計公司讓你強力曝光
※高價收購3C產品,價格不怕你比較
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!