代理模式是一種理論上非常簡單,但是各種地方的實現往往卻非常複雜。本文將從代理模式的基本概念出發,探討代理模式在java領域的應用與實現。讀完本文你將get到以下幾點:
- 為什麼需要代理模式,它通常用來解決什麼問題,以及代理模式的設計與實現思路
- Java領域中代理模式3種不同實現類型(靜態代理,jdk動態代理,cglib)
- 代理模式的面試考點
為什麼要使用代理模式
在生活中我們通常是去商場購買東西,而不是去工廠。最主要的原因可能有以下幾種:
- 成本太高,去工廠路途遙遠成本太高,並且可能從工廠進貨要辦理一些手續流程;
- 工廠不直接賣給你,畢竟可能設計到一些行業機密或者無良廠家有一些不想讓你知道的東西;
- 商場能提供一些商品之外的服務,商場里有舒適的溫度,整潔的洗手間,當然還有漂亮的小姐姐。
在面向對象的系統中也有同樣的問題,有些對象由於某種原因,比如對象創建開銷很大,或者某些操作需要安全控制等,直接訪問會給使用者或者系統結構帶來很多麻煩,這時我們就需要考慮使用代理模式。
在應用中我們可能會用代理模式解決以下問題:
- 權限控制與日誌, 在客戶端請求接口時我們可能需要在調用之前對權限進行驗證,或者通過記錄接口調用前後時間,統計執行時長,又或者說我們需要記錄用戶的一些操作日誌信息等,我們可以對原接口進行代理,然後根據需求在接口執行前後增加一些特定的操作。
- 重量級操作, 比如創建開銷大的對象, 可以先由代理對象扮演對象的替身,在需要的使用再創建對象,然後代理再將請求委託給真實的對象。
什麼是代理模式
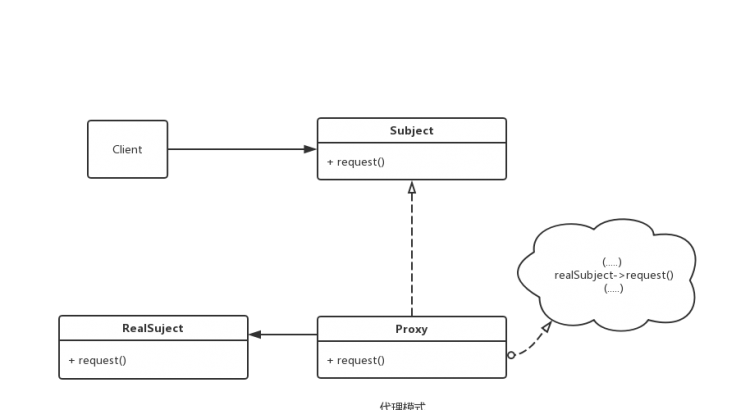
代理模式:為其他對象提供一種代理以控制(隔離,使用接口)對這個對象的訪問。類圖如下:
所謂控制,其實使用接口隔離其他對象與這個對象之間的交互;就是為client對象對RealSubject對象的訪問一種隔離,本質上就是CLient→RealSuject的關係變成了Client→Subject, Proxy→RealSubject。 需要注意的時,代理類(Proxy)並不一定要求保持接口的完整的一致性(既也可以完全不需實現Subject接口),只要能夠實現間接控制即可。
代理模式代碼演進
背景:假設已有一個訂單系統,可以保存訂單信息。
需求:打印保存訂單信息消耗時間。
/**
* 訂單服務
*
* @author cruder
* @date 2019-11-23 15:42
**/
public class OrderService2 {
/**
* 保存訂單接口
*/
public void saveOrder(String orderInfo) throws InterruptedException {
// 隨機休眠,模擬訂單保存需要的時間
Thread.sleep(System.currentTimeMillis() & 100);
System.out.println("訂單:" + orderInfo + " 保存成功");
}
}
普通方式實現
直接修改源代碼,這通常也是最簡單和最容易想到的實現。
/**
* 保存訂單接口, 直接修改代碼
*/
public void saveOrder(String orderInfo) throws InterruptedException {
long start = System.currentTimeMillis();
// 隨機休眠,模擬訂單保存需要的時間
Thread.sleep(System.currentTimeMillis() & 100);
System.out.println("訂單:" + orderInfo + " 保存成功");
System.out.println("保存訂單用時: " + (System.currentTimeMillis() - start) + "ms");
}
面向對象設計原則中的“開閉原則”告訴我們,開閉原則規定“軟件中的對象(類,模塊,函數等等)應該對於擴展是開放的,但是對於修改是封閉的”,這意味着一個實體是允許在不改變它的源代碼的前提下變更它的行為。
代理模式實現
/**
* 1. 定義接口,為了使代理被代理對象看起來一樣。當然這一步完全可以省略
*
* @author cruder
* @date 2019-11-23 15:58
**/
public interface IOrderService {
/**
* 保存訂單接口
* @param orderInfo 訂單信息
*/
void saveOrder(String orderInfo) throws InterruptedException;
}
/**
* 2. 原有訂單服務,也實現這個接口。注意 此步驟也完全可以省略。
*
* @author cruder
* @date 2019-11-23 15:42
**/
public class OrderService implements IOrderService{
/**
* 保存訂單接口
*/
@Override
public void saveOrder(String orderInfo) throws InterruptedException {
// 隨機休眠,模擬訂單保存需要的時間
Thread.sleep(System.currentTimeMillis() & 100);
System.out.println("訂單:" + orderInfo + " 保存成功");
}
}
/**
* 3. 創建代理類,實現訂單服務接口【這才是代理模式的實現】
*
* @author cruder
* @date 2019-11-23 16:01
**/
public class OrderServiceProxy implements IOrderService{
/**
* 內部持有真實的訂單服務對象,保存訂單工作實際由它來完成
*/
private IOrderService orderService;
@Override
public void saveOrder(String orderInfo) throws InterruptedException {
/**
* 延遲初始化,也可以創建代理對象時就創建,或者作為構造參數傳進來
* 僅作為代碼實例,不考慮線程安全問題
*/
if (orderService == null) {
orderService = new OrderService();
}
long start = System.currentTimeMillis();
orderService.saveOrder(orderInfo);
System.out.println("保存訂單用時: " + (System.currentTimeMillis() - start) + "ms");
}
}執行程序
執行程序
代理模式的優缺點
優點: 1、職責清晰。 2、高擴展性。 3、智能化。
缺點:
1、由於在客戶端和真實主題之間增加了代理對象,因此有些類型的代理模式可能會造成請求的處理速度變慢。 2、實現代理模式需要額外的工作,有些代理模式的實現非常複雜。
Java中代理模式的實現
在java中代理模式可以按照代理類的創建時機分兩類,即靜態代理和動態代理,而動態代理又可以分為jdk動態代理和cglib動態代理。每種實現方式都各有千秋,接下來筆者將回針對不同的實現方式進行演示和剖析。
靜態代理
在上文代理模式代碼演進中就使用了靜態代理模式。所謂靜態代理中的“靜”字,無非就是代理類的創建時機不同罷了。靜態代理需要為每個被代理的對象手動創建一個代理類;而動態代理則時在運行時通過某種機制來動態生成,不需要手動創建代理類。
動態代理 – jdk
jdk動態代理模式是利用java中的反射技術,在運行時動態創建代理類。接下來我們仍藉助上文中的訂單服務的案例,使用jdk動態代理實現。
基於動態jdk涉及到兩個核心的類Proxy類和一個 InvocationHandler接口。
/**
* 基於JDK技術 動態代理類技術核心 Proxy類和一個 InvocationHandler 接口
*
* @author cruder
* @date 2019-11-23 16:40
**/
public class ProxyFactory implements InvocationHandler {
/**
* 委託對象,既被代理的對象
*/
private Object target;
public ProxyFactory (Object target) {
this.target = target;
}
/**
* 生成代理對象
* 1. Classloader loader: 制定當前被代理對象使用的累加子啊其,獲取加載器的方法固定
* 2. Class<?>[] interfaces: 委託類的接口類型,使用泛型方法確認類型
* 3. InvocationHandler handler: 事件處理,執行委託對象的方法時會觸發事件處理器方法,
* 會把當前執行的委託對象方法作為參數傳入
*/
public Object getProxyInstance() {
Class clazz = target.getClass();
return Proxy.newProxyInstance(clazz.getClassLoader(), clazz.getInterfaces(), this);
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
long start = System.currentTimeMillis();
method.invoke(target, args);
System.out.println("保存訂單用時: " + (System.currentTimeMillis() - start) + "ms");
return null;
}
}
/**
* 通過動態代理方式來保存訂單
*
* @author cruder
* @date 2019-11-23 15:49
**/
public class Client {
public static void main(String[] args) throws InterruptedException {
ProxyFactory proxyFactory= new ProxyFactory (new OrderService());
IOrderService orderService = (IOrderService) proxyFactory.getProxyInstance();
orderService.saveOrder(" cruder 新買的花褲衩 ");
}
}
以上便是jdk動態代理的全部實現,有種只可意會不可言傳的感覺,筆者始終感覺這種實現看起來很彆扭。不過也要強行總結以下,jdk實現動態代理可以分為以下幾個步驟:
- 先檢查委託類是否實現了相應接口,保證被訪問方法在接口中也要有定義
- 創建一個實現InvocationHandler接口的類
- 在類中定義一個被代理對象的成員屬性,為了擴展方便可以直接使用Object類,也可以根據需求定義相應的接口
- 在invoke方法中實現對委託對象的調用,根據需求對方法進行增強
- 使用Proxy.newProxyInstance(…)方法創建代理對象,並提供要給獲取代理對象的方法
代理類源碼閱讀
上文中基於jdk動態代理的代碼實現中對於可*的產品經理來說已經完全滿足了需求,但是對於具有Geek精神的程序員來說這遠遠不夠,對於這種不知其所以然的東西往往讓人感到不安。接下來我們將通過自定義的一個小工具類將動態生成的代理類保存到本地來一看究竟。
/**
* 將生成的代理類保存為.class文件的工具類
*
* @author cruder
* @date 2019-08-15 0:27
*/
public class ProxyUtils {
/**
* 將代理類保存到指定路徑
*
* @param path 保存到的路徑
* @param proxyClassName 代理類的Class名稱
* @param interfaces 代理類接口
* @return
*/
public static boolean saveProxyClass(String path, String proxyClassName, Class[] interfaces){
if (proxyClassName == null || path == null) {
return false;
}
// 獲取文件字節碼,然後輸出到目標文件中
byte[] classFile = ProxyGenerator.generateProxyClass(proxyClassName, interfaces);
try (FileOutputStream out = new FileOutputStream(path)) {
out.write(classFile);
out.flush();
} catch (IOException e) {
e.printStackTrace();
return false;
}
return true;
}
}
// 此處是重點, 生成的代理類實現了IOrderService,並且繼承了Proxy
public final class $Proxy0 extends Proxy implements IOrderService {
private static Method m1;
private static Method m3;
private static Method m2;
private static Method m0;
public $Proxy0(InvocationHandler var1) throws {
super(var1);
}
public final boolean equals(Object var1) throws {
try {
return (Boolean)super.h.invoke(this, m1, new Object[]{var1});
} catch (RuntimeException | Error var3) {
throw var3;
} catch (Throwable var4) {
throw new UndeclaredThrowableException(var4);
}
}
public final void saveOrder(Order var1) throws {
try {
super.h.invoke(this, m3, new Object[]{var1});
} catch (RuntimeException | Error var3) {
throw var3;
} catch (Throwable var4) {
throw new UndeclaredThrowableException(var4);
}
}
public final String toString() throws {
try {
return (String)super.h.invoke(this, m2, (Object[])null);
} catch (RuntimeException | Error var2) {
throw var2;
} catch (Throwable var3) {
throw new UndeclaredThrowableException(var3);
}
}
public final int hashCode() throws {
try {
return (Integer)super.h.invoke(this, m0, (Object[])null);
} catch (RuntimeException | Error var2) {
throw var2;
} catch (Throwable var3) {
throw new UndeclaredThrowableException(var3);
}
}
static {
try {
// 通過反射獲取Method對象
m1 = Class.forName("java.lang.Object").getMethod("equals", Class.forName("java.lang.Object"));
m3 = Class.forName("cn.mycookies.test08proxy.IOrderService").getMethod("saveOrder", Class.forName("cn.mycookies.test08proxy.Order"));
m2 = Class.forName("java.lang.Object").getMethod("toString");
m0 = Class.forName("java.lang.Object").getMethod("hashCode");
} catch (NoSuchMethodException var2) {
throw new NoSuchMethodError(var2.getMessage());
} catch (ClassNotFoundException var3) {
throw new NoClassDefFoundError(var3.getMessage());
}
}
}
ps: 實習轉正面試中被問到為什麼jdk動態代理被代理的類為什麼要實現接口?
cglib動態代理
對於cglib我想大多數人應該都很陌生,或者是在學習Spring中AOP(面向切面編程)時聽說了它使用jdk和cglib兩種方式實現了動態代理。接下來筆者將針對cglib進行簡要介紹。
cglib動態代理和jdk動態代理類似,也是採用操作字節碼機制,在運行時生成代理類。cglib 動態代理採取的是創建目標類的子類的方式,因為是子類化,我們可以達到近似使用被調用者本身的效果。
字節碼處理機制-指得是ASM來轉換字節碼並生成新的類
注:spring中有完整的cglib相關的依賴,所以以下代碼基於spring官方下載的demo中直接進行編寫的
/**
* 1. 訂單服務-委託類,不需要再實現接口
*
* @author cruder
* @date 2019-11-23 15:42
**/
public class OrderService {
/**
* 保存訂單接口
*/
public void saveOrder(String orderInfo) throws InterruptedException {
// 隨機休眠,模擬訂單保存需要的時間
Thread.sleep(System.currentTimeMillis() & 100);
System.out.println("訂單:" + orderInfo + " 保存成功");
}
}
/**
* cglib動態代理工廠
*
* @author cruder
* @date 2019-11-23 18:36
**/
public class ProxyFactory implements MethodInterceptor {
/**
* 委託對象, 即被代理對象
*/
private Object target;
public ProxyFactory(Object target) {
this.target = target;
}
/**
* 返回一個代理對象
* @return
*/
public Object getProxyInstance(){
// 1. 創建一個工具類
Enhancer enhancer = new Enhancer();
// 2. 設置父類
enhancer.setSuperclass(target.getClass());
// 3. 設置回調函數
enhancer.setCallback(this);
// 4.創建子類對象,即代理對象
return enhancer.create();
}
@Override
public Object intercept(Object o, Method method, Object[] args, MethodProxy methodProxy) throws Throwable {
long start = System.currentTimeMillis();
Object result = method.invoke(target, args);
System.out.println("cglib代理:保存訂單用時: " + (System.currentTimeMillis() - start) + "ms");
return result;
}
}
/**
* 使用cglib代理類來保存訂單
*
* @author cruder
* @date 2019-11-23 15:49
**/
public class Client {
public static void main(String[] args) throws InterruptedException {
// 1. 創建委託對象
OrderService orderService = new OrderService();
// 2. 獲取代理對象
OrderService orderServiceProxy = (OrderService) new ProxyFactory(orderService).getProxyInstance();
String saveFileName = "CglibOrderServiceDynamicProxy.class";
ProxyUtils.saveProxyClass(saveFileName, orderService.getClass().getSimpleName(), new Class[]{IOrderService.class});
orderServiceProxy.saveOrder(" cruder 新買的花褲衩 ");
}
}
cglib動態代理實現步驟和jdk及其相似,可以分為以下幾個步驟:
- 創建一個實現MethodInterceptor接口的類
- 在類中定義一個被代理對象的成員屬性,為了擴展方便可以直接使用Object類,也可以根據需求定義相應的接口
- 在invoke方法中實現對委託對象的調用,根據需求對方法進行增強
- 使用Enhancer創建生成代理對象,並提供要給獲取代理對象的方法
cglib動態代理生成的代理類和jdk動態代理代碼格式上幾乎沒有什麼區別,唯一的區別在於cglib生成的代理類繼承了僅僅Proxy類,而jdk動態代理生成的代理類繼承了Proxy類的同時也實現了一個接口。代碼如下:
// 生成一個Proxy的子類
public final class OrderService extends Proxy {
private static Method m1;
private static Method m2;
private static Method m0;
public OrderService(InvocationHandler var1) throws {
super(var1);
}
public final boolean equals(Object var1) throws {
try {
return (Boolean)super.h.invoke(this, m1, new Object[]{var1});
} catch (RuntimeException | Error var3) {
throw var3;
} catch (Throwable var4) {
throw new UndeclaredThrowableException(var4);
}
}
public final String toString() throws {
try {
return (String)super.h.invoke(this, m2, (Object[])null);
} catch (RuntimeException | Error var2) {
throw var2;
} catch (Throwable var3) {
throw new UndeclaredThrowableException(var3);
}
}
public final int hashCode() throws {
try {
return (Integer)super.h.invoke(this, m0, (Object[])null);
} catch (RuntimeException | Error var2) {
throw var2;
} catch (Throwable var3) {
throw new UndeclaredThrowableException(var3);
}
}
static {
try {
m1 = Class.forName("java.lang.Object").getMethod("equals", Class.forName("java.lang.Object"));
m2 = Class.forName("java.lang.Object").getMethod("toString");
m0 = Class.forName("java.lang.Object").getMethod("hashCode");
} catch (NoSuchMethodException var2) {
throw new NoSuchMethodError(var2.getMessage());
} catch (ClassNotFoundException var3) {
throw new NoClassDefFoundError(var3.getMessage());
}
}
}
jdk動態代理 VS cglib
JDK Proxy 的優勢:
- 最小化依賴關係,減少依賴意味着簡化開發和維護,JDK 本身的支持,可能比 cglib 更加可靠。
- 平滑進行 JDK 版本升級,而字節碼類庫通常需要進行更新以保證在新版 Java 上能夠使用。
- 代碼實現簡單。
cglib 優勢:
- 有的時候調用目標可能不便實現額外接口,從某種角度看,限定調用者實現接口是有些侵入性的實踐,類似 cglib 動態代理就沒有這種限制。
- 只操作我們關心的類,而不必為其他相關類增加工作量。
總結
- 代理模式: 為其他對象提供一種代理以控制(隔離,使用接口)對這個對象的訪問。
- jdk動態代理生成的代理類繼承了Proxy類並實現了被代理的接口;而cglib生成的代理類則僅繼承了Proxy類。
- jdk動態代理最大缺點:只能代理接口,既委託類必須實現相應的接口
- cglib缺點:由於是通過“子類化”的方式, 所以不能代理final的委託類或者普通委託類的final修飾的方法。
Q&A
- 為什麼jdk動態代理只能代理接口?
- Spring中AOP的實現採用那種代理方式?
- 都說jdk動態代理性能遠比cglib要差,如果是,依據是什麼?
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※想知道網站建置、網站改版該如何進行嗎?將由專業工程師為您規劃客製化網頁設計及後台網頁設計
※不管是台北網頁設計公司、台中網頁設計公司,全省皆有專員為您服務
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※帶您來看台北網站建置,台北網頁設計,各種案例分享