環境資訊中心綜合外電;姜唯 編譯;林大利 審校
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※南投搬家前需注意的眉眉角角,別等搬了再說!
※新北清潔公司,居家、辦公、裝潢細清專業服務
該系列博文會告訴你如何從入門到進階,一步步地學習Java基礎知識,並上手進行實戰,接着了解每個Java知識點背後的實現原理,更完整地了解整個Java技術體系,形成自己的知識框架。
構造方法(或構造函數)是類的一種特殊方法,用來初始化類的一個新的對象。Java 中的每個類都有一個默認的構造方法,它必須具有和類名相同的名稱,而且沒有返回類型。構造方法的默認返回類型就是對象類型本身,並且構造方法不能被 static、final、synchronized、abstract 和 native 修飾。
提示:構造方法用於初始化一個新對象,所以用 static 修飾沒有意義;構造方法不能被子類繼承,所以用 final 和 abstract 修飾沒有意義;多個線程不會同時創建內存地址相同的同一個對象,所以用 synchronized 修飾沒有必要。
構造方法的語法格式如下:
public class Person {
/**
* 1.構造方法沒有返回值 默認返回類型就是對象類型本身
* 2.構造方法的方法名和類名相同
*/
//無參構造方法
public Person() {
System.out.println("我是無參構造方法");
}
//有參構造方法
public Person(String username,Integer age) {
System.out.println("我是有參構造"+"姓名:"+username+" 密碼:"+age);
}
public static void main(String[] args) {
Person p1=new Person();//調用無參構造
Person p2=new Person("小王",12);//調用有參構造
}
}
關於構造方法,需要注意:
普通代碼塊是我們用得最多的也是最普遍的,它就是在方法名後面用{}括起來的代碼段。普通代碼塊是不能夠單獨存在的,它必須要緊跟在方法名後面。同時也必須要使用方法名調用它。
public class Test {
public void test(){
System.out.println("普通代碼塊");
}
}
在類中直接定義沒有任何修飾符、前綴、後綴的代碼塊即為構造代碼塊。我們明白一個類必須至少有一個構造函數,構造函數在生成對象時被調用。構造代碼塊和構造函數一樣同樣是在生成一個對象時被調用
public class Test{
{
System.out.println("我是構造代碼塊");
}
}
注意:
想到靜態我們就會想到static,靜態代碼塊就是用static修飾的用{}括起來的代碼段,它的主要目的就是對靜態屬性進行初始化。
public class Test {
static{
System.out.println("靜態代碼塊");
}
}
注意:
A:
public class Test {
public Test(){
System.out.println("Test構造函數");
}
{
System.out.println("Test構造代碼塊");
}
static {
System.out.println("靜態代碼塊");
}
public static void main(String[] args) {
}
}
結果:
靜態代碼塊
B:
public class Test {
public Test(){
System.out.println("Test構造函數");
}
{
System.out.println("Test構造代碼塊");
}
static {
System.out.println("靜態代碼塊");
}
public static void main(String[] args) {
Test t=new Test();//創建了一個對象
}
}
這段代碼相比於上述代碼多了一個創建對象的代碼
結果:
靜態代碼塊 Test構造代碼塊 Test構造函數
C:
public class Test {
public Test(){
System.out.println("Test構造函數");
}
{
System.out.println("Test構造代碼塊");
}
static {
System.out.println("靜態代碼塊");
}
public static void main(String[] args) {
Test t1=new Test();//創建了一個對象
Test t2=new Test();
}
}
結果:
靜態代碼塊 Test構造代碼塊 Test構造函數 Test構造代碼塊 Test構造函數
由此結果可以看出:靜態代碼塊只會在類加載的時候執行一次,而構造函數和構造代碼塊則會在每次創建對象的都會執行一次
對於一個類而言,按照如下順序執行:
- 執行靜態代碼塊
- 執行構造代碼塊
- 執行構造函數
對於靜態變量、靜態初始化塊、變量、初始化塊、構造器,它們的初始化順序依次是(靜態變量、靜態初始化塊)>(變量、初始化塊)>構造器。
D:
public class Test {
//靜態變量
public static String staticField="靜態變量";
//變量
public String field="變量";
//靜態初始化塊
static {
System.out.println(staticField);
System.out.println("靜態初始化塊");
}
{
System.out.println(field);
System.out.println("初始化塊");
}
//構造函數
public Test() {
System.out.println("構造函數");
}
public static void main(String[] args) {
Test t=new Test();
}
}
結果:
靜態變量 靜態初始化塊 變量 初始化塊 構造函數
class TestA{
public TestA() {
System.out.println("A的構造函數");
}
{
System.out.println("A的構造代碼塊");
}
static {
System.out.println("A的靜態代碼塊");
}
}
public class TestB extends TestA {
public TestB() {
System.out.println("B的構造函數");
}
{
System.out.println("B的構造代碼塊");
}
static {
System.out.println("B的靜態代碼塊");
}
public static void main(String[] args) {
TestB t=new TestB();
}
}
這裡有兩個類,屬於繼承的關係,讀者先不要看答案,自己思考一下結果是啥?
1 A的靜態代碼塊 2 B的靜態代碼塊 3 A的構造代碼塊 4 A的構造函數 5 B的構造代碼塊 6 B的構造函數
結果
當設計到繼承時,代碼的執行順序如下:
1、執行父類的靜態代碼塊,並初始化父類的靜態成員
2、執行子類的靜態代碼塊,並初始化子類的靜態成員
3、執行父類的構造代碼塊,執行父類的構造函數,並初始化父類的普通成員變量
4、執行子類的構造代碼塊,執行子類的構造函數,並初始化子類的普通成員變量
Java初始化流程圖:
class Parent {
/* 靜態變量 */
public static String p_StaticField = "父類--靜態變量";
/* 變量 */
public String p_Field = "父類--變量";
protected int i = 9;
protected int j = 0;
/* 靜態初始化塊 */
static {
System.out.println(p_StaticField);
System.out.println("父類--靜態初始化塊");
}
/* 初始化塊 */
{
System.out.println(p_Field);
System.out.println("父類--初始化塊");
}
/* 構造器 */
public Parent() {
System.out.println("父類--構造器");
System.out.println("i=" + i + ", j=" + j);
j = 20;
}
}
public class SubClass extends Parent {
/* 靜態變量 */
public static String s_StaticField = "子類--靜態變量";
/* 變量 */
public String s_Field = "子類--變量";
/* 靜態初始化塊 */
static {
System.out.println(s_StaticField);
System.out.println("子類--靜態初始化塊");
}
/* 初始化塊 */
{
System.out.println(s_Field);
System.out.println("子類--初始化塊");
}
/* 構造器 */
public SubClass() {
System.out.println("子類--構造器");
System.out.println("i=" + i + ",j=" + j);
}
/* 程序入口 */
public static void main(String[] args) {
System.out.println("子類main方法");
new SubClass();
}
}
結果:
父類--靜態變量 父類--靜態初始化塊 子類--靜態變量 子類--靜態初始化塊 子類main方法 父類--變量 父類--初始化塊 父類--構造器 i=9, j=0 子類--變量 子類--初始化塊 子類--構造器 i=9,j=20
(1)訪問SubClass.main(),(這是一個static方法),於是裝載器就會為你尋找已經編譯的SubClass類的代碼(也就是SubClass.class文件)。在裝載的過程中,裝載器注意到它有一個基類(也就是extends所要表示的意思),於是它再裝載基類。不管你創不創建基類對象,這個過程總會發生。如果基類還有基類,那麼第二個基類也會被裝載,依此類推。
(2)執行根基類的static初始化,然後是下一個派生類的static初始化,依此類推。這個順序非常重要,因為派生類的“static初始化”有可能要依賴基類成員的正確初始化。
(3)當所有必要的類都已經裝載結束,開始執行main()方法體,並用new SubClass()創建對象。
(4)類SubClass存在父類,則調用父類的構造函數,你可以使用super來指定調用哪個構造函數。基類的構造過程以及構造順序,同派生類的相同。首先基類中各個變量按照字面順序進行初始化,然後執行基類的構造函數的其餘部分。
(5)對子類成員數據按照它們聲明的順序初始化,執行子類構造函數的其餘部分。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益
※教你寫出一流的銷售文案?
整理以前的面試題,發現問js數據類型的頻率挺高的,回憶當初自己的答案,就是簡簡單單的把幾個類型名稱羅列了出來,便沒有了任何下文。其實這一個知識點下可以牽涉發散出很多的知識點,如果一個面試者只是羅列的那些名詞出來,可能面試官都不願意繼續問下去了,這該算是js基礎的基礎了。如果這個問題沒有很好的回答,其他問題仍舊沒有突出的亮點,很可能就過不了。
在網上看了一個體系,可作為大致的學習檢閱自己的途徑,按照清單上的知識檢測自己還有哪些不足和提升,最後形成自己的知識體系。在工作、學習甚至面試時,可以快速定位到知識點。
1. JavaScript規定了幾種語言類型 2. JavaScript對象的底層數據結構是什麼 3. Symbol類型在實際開發中的應用、可手動實現一個簡單的 Symbol 4. JavaScript中的變量在內存中的具體存儲形式 5. 基本類型對應的內置對象,以及他們之間的裝箱拆箱操作 6. 理解值類型和引用類型 7. null和 undefined的區別 8. 至少可以說出三種判斷 JavaScript數據類型的方式,以及他們的優缺點,如何準確的判斷數組類型 9. 可能發生隱式類型轉換的場景以及轉換原則,應如何避免或巧妙應用 10. 出現小數精度丟失的原因, JavaScript可以存儲的最大数字、最大安全数字, JavaScript處理大数字的方法、避免精度丟失的方法
答:js的數據類型分為簡單數據類型和複雜數據類型;
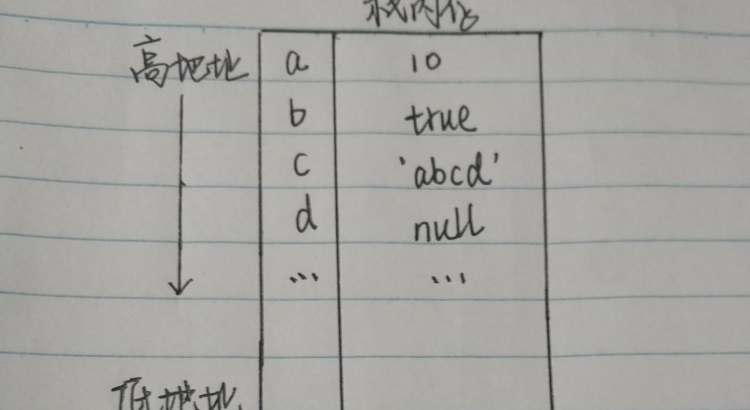
簡單數據類型有六種,分別是String(字符串)、Number(数字)、Null(空)、undefined(未定義)、boolean(布爾值)、symbol(符號),表示不能再繼續分下去的類型,在內存中以固定的大小存儲在棧中,按值訪問;
複雜數據類型是指對象,這裡有常見的array、function、object等,本質上是一組無序的鍵值對組成。它的值大小不固定,所以保存在堆中,但在棧中會存儲有指向其堆內存的地址,按引用來訪問。js不允許直接訪問內存中的位置,也就是說不能直接操作對象的內存空間。也就是說,當我們想要訪問應用類型的值的時候,需要先從棧中獲得對象的地址指針,然後通過地址指針找到其在堆中的數據。
需要注意的是,
1、簡單數據類型中的boolean、number、string不是由內置函數new出來的,儘管他們有對應的引用類型;
2、symbol是ES6引入的一種新的原始數據,表示獨一無二且不可改變的值。通過 Symbol 函數調用生成,由於生成的 symbol 值為原始類型,所以 Symbol 函數不能使用 new 調用;
3、將一個變量賦值給另一個變量時,基礎類型複製的是值,賦值完成兩個變量在沒有任何關係;而對象類型的複製的是地址,修改一個變量另一個變量也會跟着一起變化。(如何解決這個問題?關於深拷貝and淺拷貝)
這個問題目前對我來說,不能夠理解到底是想問什麼,還有問題,看到一篇這個文章,轉載《從chrome源碼看js object的實現》:
(暫未學習總結)
js的數據類型分為簡單數據類型和複雜數據類型;在內存中,簡單數據類型以固定的大小存儲在棧中;複雜數據類型存儲在堆中,且大小不固定,同時在棧中會存儲其指向堆地址的指針。
因為這裏問的是內存中的存儲形式,所以我一直注意的是內存中堆棧,後來忽然看到一篇文章寫了數據結構中的堆和棧就有一點懵,先簡單記錄一下相關知識點。
是一種物理結構,用於存放不同數據的內存空間,分為棧區和堆區。
棧(stack)是向低地址擴展的數據結構,是一塊連續的內存區域;一般來說其大小是系統預先規定好的,存儲大小已知的變量(函數的參數值、局部變量的值等)。由操作系統自動申請分配並釋放(回收)空間,無需程序員控制,這樣的好處是內存可以及時得到回收。但棧的大小有限,如果申請的空間超過棧的剩餘空間,就會提示棧溢出(一般無窮次的遞歸調用或大量的內存分配會引起棧溢出)。
在分配內存的時候類似於數據結構中的棧,先進后出的原則,即從棧低向棧頂,依次存儲。棧是向下增長,即從高地址到低地址分配內存,且內存區域連續、每個單元的大小相同。如下圖:
在現代程序中,在編譯時刻不能決定大小的對象將被分配在堆區。一般由程序員分配釋放,例如;c++和Java語言都為程序員提供了new(或malloc()),該語句創建的對象(或指向對象的指針),然後使用delete(或free())語句釋放。如果程序員不主動釋放,程序結束時由OS回收。 在內存分配的時候方式類似於鏈表,堆是向上增長,即從低地址到高地址擴展,是不連續的內存區域。如下圖:
是一種抽象的數據存儲結構,
棧:一種連續存儲的數據結構,特點是存儲的數據先進后出,只能在棧頂一端對數據項進行插入和刪除。
堆:是一棵完全二叉樹結構(知識點未掌握)
答:為了便於操作基本類型值,ECMAScript提供了3個特殊的引用類型:Boolean、Number和String, 每當讀取一個基本類型值的時候,後台會創建一個對應的基本包裝類型的對象,從而能夠調用一些方法來操作這些基本類型。每個包裝類型都映射到同名的基本類型。
裝箱就是把基本類型轉換為對應的內置對象,這裏可分為隱式和顯式裝箱。 拆箱就是與裝箱相反,把對象轉變為基本類型的值。 Ⅰ 隱式裝箱 在讀取模式下,訪問基本類型值(即讀取基本類型的值),就會創建基本類型所對應的基本包裝類型的一個對象,從而讓我們能夠調用一些方法來操作這些數據。這個基本包裝類型是臨時的,操作基本類型值的語句一經執行完畢,就會立即銷毀新創建的包裝對象。
var s1 = “stringtext”; var s2 = s1.substring(2);
如上面的例子,第一行變量s1是一個基本類型的字符串,第二行調用了s1的substring()方法,並將結果保存在了s2中。 基本類型值不是對象,從邏輯上講它們不應該有方法。其實這裏就包含了隱式裝箱,後台自動完成了一系列的處理。當第二行代碼訪問s1時,訪問過程處於一種讀取模式,即從內存中讀取這個字符串的值。 在讀取字符串時,後台會完成一下處理。
(1)創建String類型的一個實例 => var s1 = new String(“stringtext”); (2)在實例上調用指定的方法 => var s2 = s1.substring(2); (3)摧毀這個實例 => s1 = null;
注:①上面s1 = null;這種做法叫做解除引用,一旦有數據不再有用,通過設置其值為null來是釋放其引用;一般適用於大多數全局變量和全局對象的屬性。 ②
引用類型和基本包裝類型的主要區別:就是對象的生存期。使用new操作符創建的引用類型的實例,在執行流離開當前作用域之前都一直保存在內存中。而自動創建的基本包裝類型的對象,則只存在於一行代碼的執行瞬間,然後立即被銷毀,因此我們不能在運行時為基本類型值添加屬性和方法。
var s1 = “stringtext”; s1.color = “red”; //在這一句話執行完的瞬間,第二行創建的String就已經被銷毀了。 console.log(s1.color);//執行這一行代碼時又創建了自己的String對象,而該對象沒有color屬性。 //undefine
Ⅱ 顯式裝箱 通過New調用Boolean、Number、String來創建基本包裝類型的對象。不過,不建議顯式地創建基本包裝類型的對象,儘管它們操作基本類型值的能力相當重要,每個基本包裝類型都提供了操作相應值的便捷方法。 Object構造函數會像工廠方法一樣,根據傳入值的類型返回相應基本包裝類型的實例。
var obj = new Object(“stringtext”); console.log(obj instanceof String); //true
Ⅲ 拆箱 把對象轉變為基本類型的值,在拆箱的過程調用了JavaScript引擎內部的抽象操作,ToPrimitive(轉換為原始值),對原始值不發生轉換處理,只針對引用類型。 JavaScript引擎內部的抽象操作ToPrimitive()是這樣定義的,
ToPrimitive(input [, PreferredType])
該操作接受兩個參數,第一個參數是要轉變的值,第二個是PreferredType為可選參數,只接受Number或String,作用是設置想要轉換原值時的轉換偏好。最後使input轉換成原始值。
如果PreferredType被標誌為Number,則會進行下面的操作來轉換input。 ①如果輸入的是一個原始值,則直接返回它; ②否則,如果輸入的值是一個對象,則調用該對象的valueOf()方法,如果valueOf()方法的返回值是一個原始值,則返回這個原始值; ③否則,調用這個對象的toString()方法,如果toString方法的返回值是一個原始值,則返回這個原始值; ④否則,拋出TypeError異常; 如果PreferredType被標誌為String,則轉換操作的第二步和第三步的順序會調換。即 ①如果輸入的是一個原始值,則直接返回它; ②否則,如果輸入的值是一個對象,則調用該對象的 toString()方法,如果toString()方法的返回值是一個原始值,則返回這個原始值; ③否則,調用這個對象的valueOf()方法,如果valueOf()方法的返回值是一個原始值,則返回這個原始值; ④否則,拋出TypeError異常; 如果沒有PreferredType的值會按照這樣的規則來自動設置: Date類型的對象會被設置為String,其他類型的值被設置為Number
| inputTpye | result |
| Null | 不轉換,直接返回 |
| Undefined | 不轉換,直接返回 |
| Number | 不轉換,直接返回 |
| Boolean | 不轉換,直接返回 |
| String | 不轉換,直接返回 |
| Symbol | 不轉換,直接返回 |
| Object | 按照下列步驟進行轉換 |
參考文章: 《js隱式裝箱》 《[譯]JavaScript在中,{} + {}等於多少?》 原文《javaScript在中,what is {} + {} in javascrupt ?》
js包含兩種數據類型,基本數據類型和複雜數據類型,而其對應的值基本類型的值指的是簡單的數據段,引用類型指的是那些可能有多個值構成的對象。可以從三個方面來理解:動態的屬性、複製變量的值、傳遞參數
1)、動態的屬性
定義基本類型值和引用類型值的方式類似,即創建一個變量併為該變量賦值。兩者的區別在於,對於引用類型的值,我們可以為其添加屬性和方法,也可以改變和刪除其屬性和方法;對於基本類型的值,我們不能為其動態地添加屬性。
var person = new Object(); //創建一個對象並將其保存在變量person中 person.name = “Song”; //為該對象添加一個名為name的屬性,並賦值為Song console.log(person.name); //訪問name這個屬性 //Song
2)、複製變量的值
在從一個變量向另一個變量複製基本類型值和引用類型值時,兩則也是不同的,這主要是由於基本類型和引用類型在內存中存儲不同導致的。
Ⅰ基本類型的值 基本類型的值是存在棧中,存儲的即是基本類型的值;如果從一個變量向另一個變量複製的時候,就會重新創建一個變量的新值然後將其複製到為新變量分配的位置上,此時兩個變量各自擁有屬於自己的獨立的內存空間,因此兩者可以參与任何操作而不會相互影響。
var a = 1; var b = a; b = 2; console.log(a);//1 console.log(b);//2
內存變化大致如下:
Ⅱ複製引用類型的值
引用類型的值存儲在堆中,同時在棧中會有相應的堆地址(指針),指向其在堆的位置。此時如果我們要複製一個引用類型時,複製的不是堆內存中的值,而是將棧內存中的地址複製過去,複製操作結束后,兩個對象實際上都指向堆中的同一個地方。因此改變其中一個對象(堆中的值改變),那麼會影響到另一個對象。
var obj1 = { name:”Song” }; var obj2 = obj1; obj2.name = “D”; //改變obj2的name屬性的值,則將obj1的也改變了。 console.log(obj1.name); // D
注:關於深拷貝和淺拷貝
3)、傳遞參數
ECMAScript中所有函數的參數都是按值傳遞的,無論在向參數傳遞的是基本類型還是引用類型。(我的理解:正因為是按值傳遞的,所以我們才可以利用此來完成深拷貝)
有一道關於證明引用類型是按值傳遞還是按引用傳遞的題目如下:
function test(person){ person.age = 26; person = { name:'yyy', age:30 } return person } const p1 = { name:'yck', age:25 }; const p2 = test(p1); console.log(p1); console.log(p2);
首先當我們從一個變量向另一個變量複製引用類型的值時,這個值是存儲在棧中的指針地址,複製操作結束后,兩個變量引用的是同一個對象,改變其中一個變量,就會影響另一個變量。
而在向參數傳遞引用類型的值時,同樣是把內存中的地址複製給一個局部變量,所以在上述代碼中,將p1的內存地址指針複製給了局部變量person,兩者引用的是同一個對象,這個時候在函數中改變變量,就會影響到外部。
接下來相當於從新開闢了一個內存空間,然後將此內存空間的地址賦給person,可以理解為將剛才指向p1的指針地址給覆蓋了,所以改變了person的指向,當該函數結束后便釋放此內存。
(此圖作為自己的理解,不代表實際,很有可能實際並不是這樣操作的。)
所以在person.age = 26;這句話執行后把p1內存里的值改變了,打印出來p1是{name: “yck”, age: 26} p2是{name: “yyy”, age: 30}
而我理解的如果按引用傳遞,則相當於person的指向是和p1也一樣,所以後續只要是對person進行了操作,都會直接影響p1。
因此在這種情況下,打印出來p1和p2都是{name: “yyy”, age: 30}
1)、null類型
《高程》上解釋:null值表示一個空對象指針,所以這也是使用typeof操作符檢測null值時會返回”object”的原因。
var car = null; console.log(typeof car); //object
一般來說,我們要保存對象的變量在還沒有真正保存對象之前可以賦值初始化為null,其他的基礎類型在未賦值前默認為undefined,這樣一來我們直接檢查變量是否為null可以知道相應的變量是否已經保存了一個對象的引用。 即如果定義的變量準備在將來保存為對象,那麼我們將該變量初始化為null,而不是undefined。 2)、undefined類型 在使用var申明變量但未對其初始化時,這個變量的值就是undefined。
var s; console.log(s == undefined); //true
3)、null和undefined的區別 一般來說undefined是派生自null的值,因此null == undefined 是為true,因為它們是類似的值;如果用全等於(===),null ===undefined會返回false ,因為它們是不同類型的值。以此我們可以區分null和undefined。
問:判斷js數據類型有哪幾種方式,分別有什麼優缺點?怎麼樣判斷一個值是數組類型還是對象?(或者typeof能不能正確判斷類型)
答:一般來說有5種常用的方法,分別是typeof、instanceof、Object.prototype.toString()、constructor、jquery的type();
1)對於typeof來說,在檢測基本數據類型時十分得力,對於基本類型,除了null都可以返回正確類型,對於對象來說,除了function都返回object。
基本類型
typeof “somestring” // ‘string’
typeof true // ‘boolean’
typeof 10 // ‘number’
typeof Symbol() // ‘symbol’
typeof null // ‘object’ 無法判定是否為 null
typeof undefined // ‘undefined’複雜類型
typeof {} // ‘object’
typeof [] // ‘object’ 如果需要判斷數組類型,則不能使用這樣方式
typeof(() => {}) // ‘function’
注:怎麼使用複合條件來檢測null值的類型?
var a = null;
(!a && typeof a === “object”); // true
2)對於instanceof來說,可以來判斷已知對象的類型,如果使用instanceof來判斷基本類型,則始終返回false。
其原理是測試構造函數的prototype是否出現在被檢測對象的原型鏈上;所有的複雜類型的值都是object的實例,在檢測一個引用類型值和Object構造函數時,instanceof操作符始終返回true。
[] instanceof Array //true -》 無法優雅的判斷一個值到底屬於數組還是普通對象 ({}) instanceof Object //true (()=>{}) instanceof Function //true
而且在《高程》上還看到說一個問題,如果不是單一的全局執行環境,比如網頁中包含多個框架,那麼實際上存在兩個以上不同的全局執行環境,從而存在兩個以上不同版本的Array構造函數,如果從一個框架向另外一個框架傳入數組,那麼傳入的數據與在第二個框架中原生創建的數組分別具有各自不同的構造函數。eg:例如index頁面傳入一個arr變量給iframe去處理,則即使arr instanceof Array還是返回false,因為兩個引用的Array類型不是同一個。並且constructor可以重寫所以不能確保萬無一失。
對於數組來說,相當於new Array()出的一個實例,所以arr.proto === Array.prototype;又因為Array是Object的子對象,所以Array.prototype.proto === Object.prototype。因此Object構造函數在arr的原型鏈上,便無法判斷一個值到底屬於數組還是普通對象。
注:判斷變量是否為數組的方法
3)通用但比較繁瑣的方法Object.prototype.toString()
該方法本質是利用Object.prototype.toString()方法得到對象內部屬性[[Class]],傳入基本類型也能夠判斷出結果是因為對其值做了包裝。
Object.prototype.toString.call({}) === ‘[object Object]’ ——-> true;
Object.prototype.toString.call([]) === ‘[object Array]’ ——-> true;
Object.prototype.toString.call(() => {}) === ‘[object Function]’ ——-> true;
Object.prototype.toString.call(‘somestring’) === ‘[object String]’ ——-> true;
Object.prototype.toString.call(1) === ‘[object Number]’ ——-> true;
Object.prototype.toString.call(true) === ‘[object Boolean]’ ——-> true;
Object.prototype.toString.call(Symbol()) === ‘[object Symbol]’ ——-> true;
Object.prototype.toString.call(null) === ‘[object Null]’ ——-> true;
Object.prototype.toString.call(undefined) === ‘[object Undefined]’ ——-> true;Object.prototype.toString.call(new Date()) === ‘[object Date]’ ——-> true;
Object.prototype.toString.call(Math) === ‘[object Math]’ ——-> true;
Object.prototype.toString.call(new Set()) === ‘[object Set]’ ——-> true;
Object.prototype.toString.call(new WeakSet()) === ‘[object WeakSet]’ ——-> true;
Object.prototype.toString.call(new Map()) === ‘[object Map]’ ——-> true;
Object.prototype.toString.call(new WeakMap()) === ‘[object WeakMap]’ ——-> true;
4)根據對象的constructor判斷
[].constructor === Array ——–> true var d = new Date(); d.constructor === Date ———> true (()=>{}).constructor === Function ——-> true 注意: constructor 在類繼承時會出錯 eg: function A(){}; function B(){}; A.prototype = new B(); //A繼承自B var aobj = new A(); aobj.constructor === B ——–> true; aobj.constructor === A ——–> false; 而instanceof方法不會出現該問題,對象直接繼承和間接繼承的都會報true:
5)jquery的type()
如果對象是undefined或null,則返回相應的“undefined”或“null”, jQuery.type( undefined ) === “undefined” jQuery.type() === “undefined” jQuery.type( null ) === “null” 如果對象有一個內部的[[Class]]和一個瀏覽器的內置對象的 [[Class]] 相同,我們返回相應的 [[Class]] 名字。 jQuery.type( true ) === “boolean” jQuery.type( 3 ) === “number” jQuery.type( “test” ) === “string” jQuery.type( function(){} ) === “function” jQuery.type( [] ) === “array” jQuery.type( new Date() ) === “date” jQuery.type( new Error() ) === “error” // as of jQuery 1.9 jQuery.type( /test/ ) === “regexp”
6)如何判斷一個數組?
var a = [];
a.instanceof Array; ——–> true
a.constructor === Array ——–> true
Object.prototype.toString.call(a) === ‘[object Array]’ ——–> true
Array.isArray([]); ——–> true
(暫未整理)
答:在ECMAScript數據類型中的Number類型是使用IEEE754格式來表示的整數和浮點數值,所謂浮點數值就是該數值必須包含一個小數點,並且小數點後面必須至少有一位数字。而在使用基於IEEE754數值的浮點運算時出現參數舍入的誤差問題,即出現小數精度丟失,無法測試特定的浮點數值。
①在進行0.1+0.2的時候首先要將其轉換成二進制。
0.1 => 0.0001 1001 1001 1001…(無限循環) 0.2 => 0.0011 0011 0011 0011…(無限循環) ②由於 JavaScript 採用 IEEE 754 標準,數值存儲為64位雙精度格式,數值精度最多可以達到 53 個二進制位(1 個隱藏位與 52 個有效位)。如果數值的精度超過這個限度,第54位及後面的位就會被丟棄,所以在相加的時候會因為小數位的限制而將二進制数字截斷。 0.0001 1001 1001 1001…+0.0011 0011 0011 0011… = 0.0100110011001100110011001100110011001100110011001100 ③再轉換成十進制就成了0.30000000000000004,而非我們期望的0.3
在《js權威指南》中有指出:
Javascript採用了IEEE-745浮點數表示法(幾乎所有的編程語言都採用),這是一種二進製表示法,可以精確地表示分數,比如1/2,1/8,1/1024。遺憾的是,我們常用的分數(特別是在金融的計算方面)都是十進制分數1/10,1/100等。二進制浮點數表示法並不能精確的表示類似0.1這樣 的簡單的数字,上訴代碼的中的x和y的值非常接近最終的正確值,這種計算結果可以勝任大多數的計算任務:這個問題也只有在比較兩個值是否相等時才會出現。 這個問題並不是只在javascript中才會出現,在任何使用二進制浮點數的編程語言中都會出現這個問題。 所以說,精度丟失並不是語言的問題,而是浮點數存儲本身固有的缺陷。只不過在 C++/C#/Java 這些語言中已經封裝好了方法來避免精度的問題,而 JavaScript 是一門弱類型的語言,從設計思想上就沒有對浮點數有個嚴格的數據類型,所以精度誤差的問題就顯得格外突出。 javascript的未來版本或許會支持十進制数字類型以避免這些舍入問題,在這之前,你更願意使用大整數進行重要的金融計算,例如,要使用整數‘分’而不是使用小數‘元’進行貨比單位的運算。
答:一般常用的有四個方法,第一個是設置一個“能夠接受的誤差範圍”,在這個範圍內,可認為沒有誤差;第二個是使用三方的類庫math.js;第三是使用toFixed()方法;第四是封裝一個計算類(加、減、乘、除)。 ①ES6在Number對象上面,新增了一個極小的常量Number.EPSILON,它表示1與大於1的最小浮點數之間的差,它是實際上是javascript能夠表示的最小精度(可以接受的最小誤差範圍),誤差如果小於這個值,就可以認為已經沒有意義了,即不存在誤差。
Number.EPSILON === Math.pow(2, -52) // true 說明這個值Number.EPSILON是等於 2 的 -52 次方
寫一個誤差檢測函數,來判斷0.1 + 0.2 === 0.3 設置誤差範圍為 2 的-50 次方(即
Number.EPSILON * Math.pow(2, 2)),即如果兩個浮點數的差小於這個值,我們就認為這兩個浮點數相等。
function withinErrorMargin (left, right) { return Math.abs(left - right) < Number.EPSILON * Math.pow(2, 2); } withinErrorMargin(0.1 + 0.2, 0.3) //true
②math.js是一個廣泛應用於JavaScript 和 Node.js的數學庫,它的特點是靈活表達式解析器,支持符號計算,內置大量函數與常量,並提供集成解決方案來處理不同的數據類型,如数字,大数字,複數,分數,單位和矩陣。
③toFixed()方法 定義:toFixed() 方法可把 Number 四舍五入為指定小數位數的数字。 用法:NumberObject.toFixed(num) 其中num是必須的,規定小數的位數,是 0 ~ 20 之間的值,包括 0 和 20,有些實現可以支持更大的數值範圍。如果省略了該參數,將用 0 代替。 然而實際上,並不是完美的,可能你開發時候測試的幾個實例恰巧都是你想要的結果,可能在實際上線后遇到大量的數據后發現出問題了,不能正確的計算。一般是在遇到最後一位是5的時候,就不是’四舍五入”,eg:2.55.toFixed(1) // 2.5,而我們齊期望的是2.56。 我有查這個產生誤差的原因,有人說是“銀行家的舍入規則”,即四舍六入五考慮,這裏“四”是指≤4 時捨去,”六”是指≥6時進上。”五”指的是根據5後面的数字來定,當5後有數時,舍5入1;當5后無有效数字時,需要分兩種情況來講:5前為奇數,舍5入1;5前為偶數,舍5不進(0是偶數)。但在某些情況下也是不成立。
2.65.toFixed(1) //2.6 結果正確 2.45.toFixed(1) //2.5 希望得到的結果是2.4 2.35.toFixed(1) //2.4 結果正確
由於無法解決這種問題,所以看到有一些是以項目需求為準重寫符合要求的函數,在Math.round(x)來擴展解決toFixed()四舍五入不精確的問題。 原本round(x) 方法可把一個数字四舍五入為最接近的整數,其中x是必須的且必須是数字。雖然解決了四舍五入的問題,但卻沒有直接解決保留小數點后多少位的問題,因而需要重寫符合需求的函數。
function RoundNum(n, m){ //n表示需要四舍五入的數,m表示需要保留的小數位數 var newNum = Math.round(n * Math.pow(10, m)) / Math.pow(10, m) ; //首先將要保留的小數位數的小數部分轉成整數部分,利用冪函數將n乘以10的m次方 //然後利用Math.round()方法進行四舍五入處理 //最後再除以10的m次方還原小數部分 //注:此時還未能將所有数字正確轉換。例如將1.0001保留3位小數我們想要的結果是1.000,而此時newNum裏面的值是1 //所以還需要處理此種特殊情況,即保留的小數位上全0 var newSNum = newNum.toString(); //這一步將剛才進行處理過的數轉換成字符串 var rs = newSNum.indexOf('.'); //利用indexOf查找字符串中是否有.,它返回某個指定的字符串值在字符串中首次出現的位置,不存在則返回-1 if (rs < 0) { rs = newSNum.length; newSNum += '.'; } while (newSNum.length <= rs + m) { //在末尾加0 newSNum += '0'; } return newSNum; } console.log(RoundNum(1.0005, 3)); //得到1.001
④封裝一個計算類(加、減、乘、除)
(暫未實際寫過)
答:最大数字是Number.MAX_VALUE、最大安全数字是Number.MAX_SAFE_INTEGER。Number.MAX_VALUE大於Number.MAX_SAFE_INTEGER,我的理解是js可以精確表示最大安全数字以內的數,超過了最大安全数字但沒超過最大数字可以表示,但不精確,如果超過了最大数字,則這個數值會自動轉換成特殊的Infinity值。
由於內存的限制,ECMAScript並不能保存世界上所有的數值,ECMAScript能夠表示的最小數值是Number.MIN_VALUE,能夠表示的最大數值是Number.MAX_VALUE。超過數值是正值,則被轉成Infinity(正無窮),如果是負值則被轉成-Infinity(負無窮)。如果在某次返回了正或負的Infinity值,那麼該值將無法繼續參与下一次的計算,所以我們需要確定一個數值是不是有窮的,即是不是位於最小和最大的數值之間,可以使用isFinite()函數,如果該函數參數在最小和最大數值之間時會返回true。注意,如果參數類型不是數值,Number.isFinite一律返回false。
JavaScript 能夠準確表示的整數範圍在-2^53到2^53之間(不含兩個端點),超過這個範圍,無法精確表示這個值。ES6 引入了Number.MAX_SAFE_INTEGER和Number.MIN_SAFE_INTEGER這兩個常量,用來表示這個範圍的上下限。Number.isSafeInteger()則是用來判斷一個整數是否落在這個範圍之內。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想要讓你的商品成為最夯、最多人討論的話題?網頁設計公司讓你強力曝光
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!
※新北清潔公司,居家、辦公、裝潢細清專業服務

前言
本來想着關於寫JVM這個專欄,直接寫知識點乾貨的,但是想着還是有必要開篇講一下為什麼要學習JVM,這樣的話讓一些學習者心裏有點底的感覺比較好…
不得不說,隨着互聯網門檻越來越高,JVM知識也是中高級程序員階段必問的一個話題!現在不像以前了,以前會點html都好找工作,現在由於學習軟件的人越來越多,而且每年大學生都在畢業(而老一輩的也很少換工作)人只會越來越多,隨便在大街上拉一個頭髮茂盛的大叔都可能就是搞軟件的,現在有一股妖風,不管啥公司都慢慢像阿里這樣的大公司靠近,面試不問點jvm、併發、分佈式都不好意思(雖然公司可能沒有用到,雖然可能僅僅CURD),老是覺得問問這些顯得逼格高點,不管處於什麼原因很多公司的確都是這樣的!
所以我不得不相信很多人一開始接觸 Java 虛擬機只是因為面試需要用到,所以硬着頭皮去學。所以很多人對於為什麼要學虛擬機這個問題,一致的答案皆是:因為面試。
其實學習JVM並不僅僅在於面試,而在於更深入地理解 Java 這門語言,以及為未來排查線上問題打下基礎。其實說白了,還是得先 好(通)好(過)學(面)java(試)….
然而現實就是這樣,畢竟現實源於生活!也正是因為生活學習JVM為了面試的同時也為今後更好的學習java打下了基礎!
學習 Java 虛擬機能深入地理解 Java 這門語言。對於剛剛工作一兩年的朋友來說,各個 API 都沒用熟,自然不會去深入研究 Java 中的各種細節。如果你這輩子只甘心做一個平庸的Java碼農,那麼你完全沒有必要去學習JVM相關的知識。
但對於工作了三年以後的朋友來說,很多時候你要解決一個問題必須深入到字節碼層次去分析,你才能得到準確的結論,而字節碼就是虛擬機的一部分。
深入地理解 Java 這門語言實例:
1、我們常用的布爾型 Boolean,我們都知道它有兩個值,true 和 false。但你們知道其實在運行時,Java 虛擬機是沒有布爾型 Boolean 這種類型的。Boolean 型在虛擬機中使用整型的 1 和 0 表示。
2、我們都知道類路徑和類名唯一確定一個類,但事實上並不是這樣。或者說,我們前面說的結論只是表面上的。如果深入到虛擬機層面來說,類加載器、類路徑、類名才唯一決定一個類。也就是說,如果兩個不同的類加載器它們加載同一個 class 類文件,那這兩個類加載器加載的類就是不同的。
以上兩個例子如果你不懂虛擬機的一些基礎知識,那麼你就很難深入理解一些細節。
不說別的,就光和同事聊天,同事說到什麼新生代老年代問你一個GC日誌排查,你沒有JVM基礎,賊尬,那個時候你就只會喊我C牛B….
學習虛擬機是為線上排查問題打下基礎。我們知道我們一個 Java 應用部署在線上機器上,肯定時不時會出現問題。除去網絡、系統本身問題,很多時候 Java 應用出現問題,就是 Java 虛擬機的內存出現了問題。要麼是內存溢出了,要麼是 GC 頻繁導致響應慢等等。
那如何解決這些問題呢?首先,你必須學會看懂日誌吧。那麼你就必須要看得懂 GC 日誌,這是 Java 虛擬機內容的一部分。你看懂了 GC 日誌,那麼你就得明白什麼是年輕代、老年代、永久代、元數據區等,這些就是 Java 虛擬機的內存模型。你懂了 Java 虛擬機的內存模型,那你就得知道 Java 虛擬機是如何進行垃圾回收的,它們使用的垃圾回收算法是怎樣的,它們有何優缺點。接下來就是各種垃圾回收器的特性。
你看,這一切東西都是相關聯的。你想要解決線上的 Java 應用崩潰問題,那麼你就必須學會 GC 日誌。要看懂 GC 日誌,就必須學習 Java 虛擬機內存模型。要看懂 Java 虛擬機內存模型,你就要學會垃圾回收機制等等。
學習JVM對於一個Java程序員的好處大概可以概括為下六點:
1、能夠明白為什麼Java最早期被稱為解釋型語言,而後來為什麼又被大家叫做解釋與編譯並存的語言(了解JVM中解釋器以及即時編譯器就可以回答這個問題);
2、你能夠理解動態編譯與靜態編譯的區別,以及動態編譯相對於靜態編譯到底有什麼好處(JVM JIT);
3、能夠利用一些工具,jmap, jvisualvm, jstat, jconsole等工具可以輔助你觀察Java應用在運行時堆的布局情況,由此你可以通過調整JVM相關參數提高Java應用的性能;
4、可以清楚知道Java程序是如何執行的;
5、可以明白為什麼Java等高級語言具有可移植性強的特性。 其實這個問題相當於“為什麼C/C++程序員需要學體繫結構與編譯原理?“
6、能夠知道你的頭髮是怎麼沒有的
其實在開始寫JVM專欄之前就很想寫一個併發編程專欄了,想了很久,最後還是決定先寫一個JVM專欄!學習JVM有一個最大的特點就是….學了就忘,嗯哼~
由於虛擬機種類繁多這裏就不一一列舉,最常用的就是Hotspot虛擬機(翻譯過來就是 熱 地點、斑點,理解為熱點也行)以後該專欄都是以Hotspot虛擬機為準的文章。
如果想要更深入的理解JVM推薦看周志明老師的《深入理解Java虛擬機》。實戰類型的,可以看葛一鳴老師的《實戰Java虛擬機》
為了方便大家學習JVM,不用去網上找相關書籍,博主準備了周志明老師的《深入理解Java虛擬機》电子書,慢慢啃吧hhhhhhhh…
周志明老師的《深入理解Java虛擬機》:
提取碼:i3xz
以下是本JVM專欄的文章:
再次提醒:學習JVM有一個最大的特點就是….學了就忘,嗯哼~
最後,歡迎各位關注我的公眾號,一起探討技術,嚮往技術,追求技術…
參考:
《深入理解Java虛擬機》
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
※智慧手機時代的來臨,RWD網頁設計已成為網頁設計推薦首選
※評比南投搬家公司費用收費行情懶人包大公開
※幫你省時又省力,新北清潔一流服務好口碑
目錄
MyBatis是一個持久層框架,使用簡單,學習成本較低。可以執行自己手寫的SQL語句,比較靈活。但是MyBatis的自動化程度不高,移植性也不高,有時從一個數據庫遷移到另外一個數據庫的時候需要自己修改配置。
一個Mybatis最簡單的使用列子如下:
public class UserDaoTest {
private SqlSessionFactory sqlSessionFactory;
@Before
public void setUp() throws Exception{
ClassPathResource resource = new ClassPathResource("mybatis-config.xml");
InputStream inputStream = resource.getInputStream();
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
}
@Test
public void selectUserTest(){
String id = "{0003CCCA-AEA9-4A1E-A3CC-06D884BA3906}";
SqlSession sqlSession = sqlSessionFactory.openSession();
CbondissuerMapper cbondissuerMapper = sqlSession.getMapper(CbondissuerMapper.class);
Cbondissuer cbondissuer = cbondissuerMapper.selectByPrimaryKey(id);
System.out.println(cbondissuer);
sqlSession.close();
}
}本博客只涉及創建SessionFactory,以及從SessionFactory獲取SqlSession的流程。具體執行Sql的流程會在其他博客中分析。
ClassPathResource resource = new ClassPathResource("mybatis-config.xml");
InputStream inputStream = resource.getInputStream();
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);通過上面代碼發現,創建SqlSessionFactory的代碼在SqlSessionFactoryBuilder中,進去一探究竟:
//整個過程就是將配置文件解析成Configration對象,然後創建SqlSessionFactory的過程
//Configuration是SqlSessionFactory的一個內部屬性
public SqlSessionFactory build(InputStream inputStream, String environment, Properties properties) {
try {
XMLConfigBuilder parser = new XMLConfigBuilder(inputStream, environment, properties);
return build(parser.parse());
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error building SqlSession.", e);
} finally {
ErrorContext.instance().reset();
try {
inputStream.close();
} catch (IOException e) {
// Intentionally ignore. Prefer previous error.
}
}
}
public SqlSessionFactory build(Configuration config) {
return new DefaultSqlSessionFactory(config);
}下面我們看下解析配置文件過程中的一些細節。
先給出一個配置文件的列子:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!--SqlSessionFactoryBuilder中配置的配置文件的優先級最高;config.properties配置文件的優先級次之;properties標籤中的配置優先級最低 -->
<properties resource="org/mybatis/example/config.properties">
<property name="username" value="dev_user"/>
<property name="password" value="F2Fa3!33TYyg"/>
</properties>
<!--一些重要的全局配置-->
<settings>
<setting name="cacheEnabled" value="true"/>
<!--<setting name="lazyLoadingEnabled" value="true"/>-->
<!--<setting name="multipleResultSetsEnabled" value="true"/>-->
<!--<setting name="useColumnLabel" value="true"/>-->
<!--<setting name="useGeneratedKeys" value="false"/>-->
<!--<setting name="autoMappingBehavior" value="PARTIAL"/>-->
<!--<setting name="autoMappingUnknownColumnBehavior" value="WARNING"/>-->
<!--<setting name="defaultExecutorType" value="SIMPLE"/>-->
<!--<setting name="defaultStatementTimeout" value="25"/>-->
<!--<setting name="defaultFetchSize" value="100"/>-->
<!--<setting name="safeRowBoundsEnabled" value="false"/>-->
<!--<setting name="mapUnderscoreToCamelCase" value="false"/>-->
<!--<setting name="localCacheScope" value="STATEMENT"/>-->
<!--<setting name="jdbcTypeForNull" value="OTHER"/>-->
<!--<setting name="lazyLoadTriggerMethods" value="equals,clone,hashCode,toString"/>-->
<!--<setting name="logImpl" value="STDOUT_LOGGING" />-->
</settings>
<typeAliases>
</typeAliases>
<plugins>
<plugin interceptor="com.github.pagehelper.PageInterceptor">
<!--默認值為 false,當該參數設置為 true 時,如果 pageSize=0 或者 RowBounds.limit = 0 就會查詢出全部的結果-->
<!--如果某些查詢數據量非常大,不應該允許查出所有數據-->
<property name="pageSizeZero" value="true"/>
</plugin>
</plugins>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://10.59.97.10:3308/windty"/>
<property name="username" value="windty_opr"/>
<property name="password" value="windty!234"/>
</dataSource>
</environment>
</environments>
<databaseIdProvider type="DB_VENDOR">
<property name="MySQL" value="mysql" />
<property name="Oracle" value="oracle" />
</databaseIdProvider>
<mappers>
<!--這邊可以使用package和resource兩種方式加載mapper-->
<!--<package name="包名"/>-->
<!--<mapper resource="./mappers/SysUserMapper.xml"/>-->
<mapper resource="./mappers/CbondissuerMapper.xml"/>
</mappers>
</configuration>下面是解析配置文件的核心方法:
private void parseConfiguration(XNode root) {
try {
//issue #117 read properties first
//解析properties標籤,並set到Configration對象中
//在properties配置屬性后,在Mybatis的配置文件中就可以使用${key}的形式使用了。
propertiesElement(root.evalNode("properties"));
//解析setting標籤的配置
Properties settings = settingsAsProperties(root.evalNode("settings"));
//添加vfs的自定義實現,這個功能不怎麼用
loadCustomVfs(settings);
//配置類的別名,配置后就可以用別名來替代全限定名
//mybatis默認設置了很多別名,參考附錄部分
typeAliasesElement(root.evalNode("typeAliases"));
//解析攔截器和攔截器的屬性,set到Configration的interceptorChain中
//MyBatis 允許你在已映射語句執行過程中的某一點進行攔截調用。默認情況下,MyBatis 允許使用插件來攔截的方法調用包括:
//Executor (update, query, flushStatements, commit, rollback, getTransaction, close, isClosed)
//ParameterHandler (getParameterObject, setParameters)
//ResultSetHandler (handleResultSets, handleOutputParameters)
//StatementHandler (prepare, parameterize, batch, update, query)
pluginElement(root.evalNode("plugins"));
//Mybatis創建對象是會使用objectFactory來創建對象,一般情況下不會自己配置這個objectFactory,使用系統默認的objectFactory就好了
objectFactoryElement(root.evalNode("objectFactory"));
objectWrapperFactoryElement(root.evalNode("objectWrapperFactory"));
reflectorFactoryElement(root.evalNode("reflectorFactory"));
//設置在setting標籤中配置的配置
settingsElement(settings);
//解析環境信息,包括事物管理器和數據源,SqlSessionFactoryBuilder在解析時需要指定環境id,如果不指定的話,會選擇默認的環境;
//最後將這些信息set到Configration的Environment屬性裏面
environmentsElement(root.evalNode("environments"));
//
databaseIdProviderElement(root.evalNode("databaseIdProvider"));
//無論是 MyBatis 在預處理語句(PreparedStatement)中設置一個參數時,還是從結果集中取出一個值時, 都會用類型處理器將獲取的值以合適的方式轉換成 Java 類型。解析typeHandler。
typeHandlerElement(root.evalNode("typeHandlers"));
//解析Mapper
mapperElement(root.evalNode("mappers"));
} catch (Exception e) {
throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e);
}
}上面解析流程結束後會生成一個Configration對象,包含所有配置信息,然後會創建一個SqlSessionFactory對象,這個對象包含了Configration對象。
下面是openSession的過程:
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
Transaction tx = null;
try {
final Environment environment = configuration.getEnvironment();
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
//獲取執行器,這邊獲得的執行器已經代理攔截器的功能(見下面代碼)
final Executor executor = configuration.newExecutor(tx, execType);
//根據獲取的執行器創建SqlSession
return new DefaultSqlSession(configuration, executor, autoCommit);
} catch (Exception e) {
closeTransaction(tx); // may have fetched a connection so lets call close()
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}//interceptorChain生成代理類,具體參見Plugin這個類的方法
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
executor = new SimpleExecutor(this, transaction);
}
if (cacheEnabled) {
executor = new CachingExecutor(executor);
}
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}到此為止,我們已經獲得了SqlSession,拿到SqlSession就可以執行各種CRUD方法了。
對於MyBatis啟動的流程(獲取SqlSession的過程)這邊簡單總結下:
SQL的具體執行流程見後續博客。
一些重要類總結:
//TypeAliasRegistry
registerAlias("string", String.class);
registerAlias("byte", Byte.class);
registerAlias("long", Long.class);
registerAlias("short", Short.class);
registerAlias("int", Integer.class);
registerAlias("integer", Integer.class);
registerAlias("double", Double.class);
registerAlias("float", Float.class);
registerAlias("boolean", Boolean.class);
registerAlias("byte[]", Byte[].class);
registerAlias("long[]", Long[].class);
registerAlias("short[]", Short[].class);
registerAlias("int[]", Integer[].class);
registerAlias("integer[]", Integer[].class);
registerAlias("double[]", Double[].class);
registerAlias("float[]", Float[].class);
registerAlias("boolean[]", Boolean[].class);
registerAlias("_byte", byte.class);
registerAlias("_long", long.class);
registerAlias("_short", short.class);
registerAlias("_int", int.class);
registerAlias("_integer", int.class);
registerAlias("_double", double.class);
registerAlias("_float", float.class);
registerAlias("_boolean", boolean.class);
registerAlias("_byte[]", byte[].class);
registerAlias("_long[]", long[].class);
registerAlias("_short[]", short[].class);
registerAlias("_int[]", int[].class);
registerAlias("_integer[]", int[].class);
registerAlias("_double[]", double[].class);
registerAlias("_float[]", float[].class);
registerAlias("_boolean[]", boolean[].class);
registerAlias("date", Date.class);
registerAlias("decimal", BigDecimal.class);
registerAlias("bigdecimal", BigDecimal.class);
registerAlias("biginteger", BigInteger.class);
registerAlias("object", Object.class);
registerAlias("date[]", Date[].class);
registerAlias("decimal[]", BigDecimal[].class);
registerAlias("bigdecimal[]", BigDecimal[].class);
registerAlias("biginteger[]", BigInteger[].class);
registerAlias("object[]", Object[].class);
registerAlias("map", Map.class);
registerAlias("hashmap", HashMap.class);
registerAlias("list", List.class);
registerAlias("arraylist", ArrayList.class);
registerAlias("collection", Collection.class);
registerAlias("iterator", Iterator.class);
registerAlias("ResultSet", ResultSet.class);https://blog.csdn.net/luanlouis/article/details/40422941
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包"嚨底家"
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家費用,距離,噸數怎麼算?達人教你簡易估價知識!
※教你寫出一流的銷售文案?

在平時的工作中,我們經常接觸到數據庫表和用戶以及角色的使用,由於經常使用默認的數據庫表空間和模式(Schema),所以我們往往忽略了數據庫表空間和模式的概念以及作用。
接下來,先介紹一下模式和表空間的定義以及作用。
一個數據庫包含一個或多個已命名的模式,模式又包含表。模式還可以包含其它對象, 包括數據類型、函數、操作符等。同一個對象名可以在不同的模式里使用而不會導致衝突; 比如,herschema和myschema都可以包含一個名為mytable的表。 和數據庫不同,模式不是嚴格分離的:只要有權限,一個用戶可以訪問他所連接的數據庫中的任意模式中的對象。
我們需要模式的原因有好多:
模式類似於操作系統層次的目錄,只不過模式不能嵌套。
表空間是實際的數據存儲的地方。一個數據庫schema可能存在於多個表空間,相似地,一個表空間也可以為多個schema服務。
通過使用表空間,管理員可以控制磁盤的布局。表空間的最常用的作用是優化性能,例如,一個最常用的索引可以建立在非常快的硬盤上,而不太常用的表可以建立在便宜的硬盤上,比如用來存儲用於進行歸檔文件的表。
在PostgreSQL中,存在兩個容易混淆的概念:角色/用戶。之所以說這兩個概念容易混淆,是因為對於PostgreSQL來說,這是完全相同的兩個對象。唯一的區別是在創建的時候:
1.我用下面的psql創建了角色custom:
CREATE ROLE custom PASSWORD 'custom';接着我使用新創建的角色custom登錄,PostgreSQL給出拒絕信息:
FATAL:role 'custom' is not permitted to log in.說明該角色沒有登錄權限,系統拒絕其登錄
2.我又使用下面的psql創建了用戶guest:
CREATE USER guest PASSWORD 'guest';接着我使用guest登錄,登錄成功
難道這兩者有區別嗎?查看文檔,又這麼一段說明:CREATE USER is the same as CREATE ROLE except that it implies LOGIN. —-CREATE USER除了默認具有LOGIN權限之外,其他與CREATE ROLE是完全相同的。
為了驗證這句話,修改custom的權限,增加LOGIN權限:
ALTER ROLE custom LOGIN;再次用custom登錄,成功!那麼事情就明了了:
CREATE ROLE custom PASSWORD ‘custom’ LOGIN 等同於 CREATE USER custom PASSWORD ‘custom’.
這就是ROLE/USER的區別。
模式(schema)是對數據庫(database)邏輯分割。
在數據庫創建的同時,就已經默認為數據庫創建了一個模式–public,這也是該數據庫的默認模式。所有為此數據庫創建的對象(表、函數、試圖、索引、序列等)都是創建在這個模式中的:
1.創建一個數據庫mars
CREATE DATABASE mars;2.用custom角色登錄到mars數據庫,查看數據庫中的所有模式:\dn
显示結果只有public一個模式。
3.創建一張測試表
CREATE TABLE test(id integer not null);4.查看當前數據庫的列表:\d;
显示結果是表test屬於模式public.也就是test表被默認創建在了public模式中。
5.創建一個新模式custom,對應於登錄用戶custom:
CREATE SCHEMA custom;
ALTER SCHEMA custom OWNER TO custom;6.再次創建一張test表,這次這張表要指明模式
CREATE TABLE custom.test (id integer not null);7.查看當前數據庫的列表: \d
显示結果是表test屬於模式custom.也就是這個test表被創建在了custom模式中。
得出結論是:數據庫是被模式(schema)來切分的,一個數據庫至少有一個模式,所有數據庫內部的對象(object)是被創建於模式的。用戶登錄到系統,連接到一個數據庫后,是通過該數據庫的search_path來尋找schema的搜索順序,可以通過命令SHOW search_path;具體的順序,也可以通過SET search_path TO 'schema_name'來修改順序。
官方建議是這樣的:在管理員創建一個具體數據庫后,應該為所有可以連接到該數據庫的用戶分別創建一個與用戶名相同的模式,然後,將
search_path設置為$user,即默認的模式是與用戶名相同的模式。
數據庫創建語句:
CREATE DATABASE dbname;默認的數據庫所有者是當前創建數據庫的角色,默認的表空間是系統的默認表空間pg_default。
為什麼是這樣的呢?
因為在PostgreSQL中,數據的創建是通過克隆數據庫模板來實現的,這與SQL SERVER是同樣的機制。由於CREATE DATABASE dbname並沒有指明數據庫模板,所以系統將默認克隆template1數據庫,得到新的數據庫dbname。(By default, the new database will be created by cloning the standard system database template1)
template1數據庫的默認表空間是pg_default,這個表空間是在數據庫初始化時創建的,所以所有template1中的對象將被同步克隆到新的數據庫中。
相對完整的語法應該是這樣的:
CREATE DATABASE dbname TEMPLATE template1 TABLESPACE tablespacename;
ALTER DATABASE dbname OWNER TO custom;1.連接到template1數據庫,創建一個表作為標記:
CREATE TABLE test(id integer not null);向表中插入數據
INSERT INTO test VALUES (1);2.創建一個表空間:
CREATE TABLESPACE tsmars OWNER custom LOCATION '/tmp/data/tsmars';在此之前應該確保目錄/tmp/data/tsmars存在,並且目錄為空。
3.創建一個數據庫,指明該數據庫的表空間是剛剛創建的tsmars:
CREATE DATABASE dbmars TEMPLATE template1 OWNERE custom TABLESPACE tsmars;
ALTER DATABASE dbmars OWNER TO custom;4.查看系統中所有數據庫的信息:\l+
可以發現,dbmars數據庫的表空間是tsmars,擁有者是custom;
仔細分析后,不難得出結論:
在PostgreSQL中,表空間是一個目錄,裏面存儲的是它所包含的數據庫的各種物理文件。
表空間是一個存儲區域,在一個表空間中可以存儲多個數據庫,儘管PostgreSQL不建議這麼做,但我們這麼做完全可行。一個數據庫並不知直接存儲表結構等對象的,而是在數據庫中邏輯創建了至少一個模式,在模式中創建了表等對象,將不同的模式指派該不同的角色,可以實現權限分離,又可以通過授權,實現模式間對象的共享,並且還有一個特點就是:public模式可以存儲大家都需要訪問的對象。
表空間用於定義數據庫對象在物理存儲設備上的位置,不特定於某個單獨的數據庫。數據庫是數據庫對象的物理集合,而schema則是數據庫內部用於組織管理數據庫對象的邏輯集合,schema名字空間之下則是各種應用程序會接觸到的對象,比如表、索引、數據類型、函數、操作符等。
角色(用戶)則是數據庫服務器(集群)全局範圍內的權限控制系統,用於各種集群範圍內所有的對象權限管理。因此角色不特定於某個單獨的數據庫,但角色如果需要登錄數據庫管理系統則必須連接到一個數據庫上。角色可以擁有各種數據庫對象。
關注公眾號:JAVA九點半課堂,這裡有一批優秀的技術大牛,為你提供方向,提供資源!加入我們,一起探討技術,共同進步!回復“資料”獲取 2T 行業最新資料!
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※想知道網站建置、網站改版該如何進行嗎?將由專業工程師為您規劃客製化網頁設計及後台網頁設計
※不管是台北網頁設計公司、台中網頁設計公司,全省皆有專員為您服務
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※別再煩惱如何寫文案,掌握八大原則!
數據庫有三級模型的概念,在這裏,數據倉庫也是有着三級模型並且是有着相似的思路。
1.概念模型
“信息世界”中的信息結構,也常常借用關係數據庫設計中的E-R方法,不過在數據倉庫的設計是以主題替代實體。
根據業務的範圍和使用來劃分主題
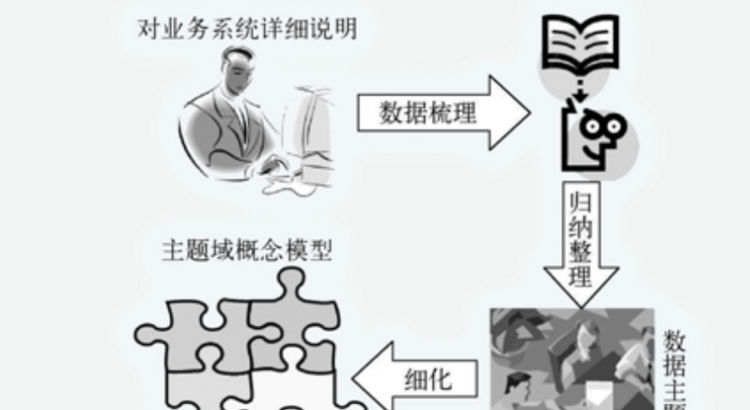
劃分的方法是首先要確定系統邊界,包括了解決策者需求(關注點),需求類型。通過對業務系統的詳細說明,確定數據覆蓋範圍,對數據進行梳理,列出數據主題詳細的清單,了解源數據狀況。
對每個數據主題都作出詳細的解釋,然後經過歸納、分類,整理成各個數據主題域,確定系統包含的主題。列出每個數據主題域包含哪些部分,並對每個數據主題域作出詳細的解釋,最後劃分成主題域概念模型。
2.邏輯模型
邏輯模型的設計是數據倉庫實施中最重要的一步,因為它直接反映了數據分析部門的實際需求和業務規則,同時對物理模型的設計和實現具有指導作用。它的特點就是通過實體和實體之間的關係勾勒出整個企業的數據藍圖和規劃。邏輯模型一般遵循第三範式,與概念模型不同,它主要關注細節性的業務規則,同時需要解決每個主題包含哪些概念範疇和跨主題域的繼承和共享的問題。
根據需求列出需要分析的主題,需求目標緯度指標,緯度層次分析的指標,分析的方法、數據來源等
對於一些緯度存在層次問題,比如說產品存在產品的類別,產品的子類別以及具體的產品
在邏輯模型設計中需要考慮粒度層次的劃分。數據倉庫的粒度層次劃分直接影響了數據倉庫模型的設計,通常細粒度的數據模型直接從企業模型選取實體作為邏輯模型的實體,而粗粒度的數據模型需要經過匯總計算得到相應的實體。粒度決定企業數據倉庫的實現方式、性能、靈活性和數據倉庫的數據量。
粒度指的是描述數據的綜合程度。粒度規定了數據倉庫潛在的能力和靈活性,如果沒有粒度級別的變化,數據倉庫將不能回答需要低於所採用細節級的問題。同時,粒度級別是數據庫規模的主要決定因素之一,對操作的開銷及性能都有顯著影響。
數據粒度越小,信息越細,數據量越大;顆粒粒度越大就忽略了眾多的細節,數據量越小。
3.物理模型
將邏輯模型轉變為物理模型包括以下幾個步驟:
(1)實體名(Entity) 轉變為表名(Table)。
(2)屬性名(Attribute) 轉換為列名(Column) ,確定列的屬性(Property) 。
(3)確定表之間連接主鍵和外鍵屬性或屬性組。
在物理模型設計中同時要考慮數據的存儲結構、存取時間、存儲空間利用率、維護代價等。根據數據的重要程度、使用頻率和響應時間將數據分類,不同類數據分別存放在不同存儲設備中,重要性高、經常存取並對反應時間要求高的數據存放在高速存儲設備上:存取頻率低或對存取響應時間要求低的數據可以存放在低速存儲設備上。根據數據量設定存儲塊、緩衝區大小和個數。
兩大類物理模型
數據倉庫的的數據模型相對數據庫更簡單一些,根據事實表和維度表的關係,主要有星形結構模型和雪花型結構模型兩種。
當所有維表都直接連接到“事實表”上時,整個圖解就像星星一樣,故將該模型稱為星型模型。
星型架構是一種非規範化的結構,多維數據集的每一個維度都直接與事實表相連接,所以數據有一定的冗餘,如在商店維度表中,存在省A的城市B以及省A的城市C兩條記錄,那麼省A的信息分別存儲了兩次,即存在冗餘。
雪花型架構相對於星形架構的優點是,能夠直接利用現有的數據庫建模工具進行建模,提高工作效率;以後對維度表的變更會更加靈活,而星形結構會牽涉到大量的數據更新:由於不存在數據冗餘,因此數據的裝載速度會更快。雪花型架構通過去除了數據冗餘,通過最大限度地減少數據存儲量以及聯合較小的維表來改善查詢性能。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※南投搬家前需注意的眉眉角角,別等搬了再說!
※新北清潔公司,居家、辦公、裝潢細清專業服務

在生產場景中,我們經常用到LINQ運算符進行查詢獲取數據,現在我們就來了解下生產場景經常出現幾種複雜查詢運算符。
藉助LINQ Join運算符,可根據每個源的鍵選擇器連接兩個數據源,並在鍵匹配時生成值的元組。
var query = from blog in _context.Set<Blog>() join post in _context.Set<Post>() on blog.BlogId equals post.BlogId select new { blog, post };
SQL:
SELECT [blog].[BlogId], [blog].[Createtime], [blog].[Updatetime], [blog].[Url], [post].[PostId], [post].[BlogId], [post].[Content], [post].[Title]
FROM [Blog] AS [blog]
INNER JOIN [Post] AS [post] ON [blog].[BlogId] = [post].[BlogId]
SQL Server Profiler:
雖然Left Join不是LINQ運算符,但關係數據庫具有常用於查詢的Left Join的概念。LINQ查詢中的特定模式提供與服務器上的LEFT JOIN相同的結果。
var query = from blog in _context.Set<Blog>() join post in _context.Set<Post>() on blog.BlogId equals post.BlogId into grouping from post in grouping.DefaultIfEmpty() select new { blog, post };
SQL:
SELECT [blog].[BlogId], [blog].[Createtime], [blog].[Updatetime], [blog].[Url], [post].[PostId], [post].[BlogId], [post].[Content], [post].[Title]
FROM [Blog] AS [blog]
LEFT JOIN [Post] AS [post] ON [blog].[BlogId] = [post].[BlogId]
SQL Server Profiler:
LINQ GroupBy運算符創建IGrouping<TKey, TElement>類型的結果,其中TKey和TElement可以是任意類型。此外,IGrouping實現了IEnumerable<TElement>,這意味着可在分組后使用任意LINQ運算符來對其進行組合。
var query = from blog in _context.Set<Blog>() group blog by blog.Url into g select new { g.Key, Count = g.Count() };
SQL:
SELECT [blog].[Url] AS [Key], COUNT(*) AS [Count]
FROM [Blog] AS [blog]
GROUP BY [blog].[Url]
SQL Server Profiler:
分組的聚合運算符出現在Where或OrderBy(或其他排序方式)LINQ運算符中。它在SQL中將Having子句用於Where子句。
var query = from blog in _context.Set<Blog>() group blog by blog.Url into g where g.Count() > 0 orderby g.Key select new { g.Key, Count = g.Count() };
SQL:
SELECT [blog].[Url] AS [Key], COUNT(*) AS [Count] FROM [Blog] AS [blog] GROUP BY [blog].[Url] HAVING COUNT(*) > 0 ORDER BY [Key]
SQL Server Profiler:
EF Core支持的聚合運算符如下所示:
●Avg
●Count
●LongCount
●Max
●Min
●Sum
藉助LINQ SelectMany運算符,可為每個外部元素枚舉集合選擇器,並從每個數據源生成值的元組。
var query0 = from b in _context.Set<Blog>() from p in _context.Set<Post>() select new { b, p }; var query1 = from b in _context.Set<Blog>() from p in _context.Set<Post>().Where(p => b.BlogId == p.BlogId).DefaultIfEmpty() select new { b, p }; var query2 = from b in _context.Set<Blog>() from p in _context.Set<Post>().Select(p => b.Url + "=>" + p.Title).DefaultIfEmpty() select new { b, p };
SQL:
SELECT [b].[BlogId], [b].[Createtime], [b].[Updatetime], [b].[Url], [p].[PostId], [p].[BlogId], [p].[Content], [p].[Title] FROM [Blog] AS [b] CROSS JOIN [Post] AS [p] SELECT [b].[BlogId], [b].[Createtime], [b].[Updatetime], [b].[Url], [t0].[PostId], [t0].[BlogId], [t0].[Content], [t0].[Title] FROM [Blog] AS [b] CROSS APPLY ( SELECT [t].[PostId], [t].[BlogId], [t].[Content], [t].[Title] FROM ( SELECT NULL AS [empty] ) AS [empty] LEFT JOIN ( SELECT [p].[PostId], [p].[BlogId], [p].[Content], [p].[Title] FROM [Post] AS [p] WHERE [b].[BlogId] = [p].[BlogId] ) AS [t] ON 1 = 1 ) AS [t0] SELECT [b].[BlogId], [b].[Createtime], [b].[Updatetime], [b].[Url], [t0].[c] FROM [Blog] AS [b] CROSS APPLY ( SELECT [t].[c] FROM ( SELECT NULL AS [empty] ) AS [empty] LEFT JOIN ( SELECT ([b].[Url] + N'=>') + [p].[Title] AS [c] FROM [Post] AS [p] ) AS [t] ON 1 = 1 ) AS [t0]
SQL Server Profiler:
好了,這裏就不多寫關於LINQ其他示例了,如果需要了解的小夥伴們,可以移步“”這裏了解。
有一些複雜業務場景,使用LINQ查詢可能會導致SQL查詢效率低下並不適用,那麼這時候就需要到原生SQL查詢了。EF Core為我們提供FromSql擴展方法基於原始SQL查詢。 FromSql只能在直接位於DbSet<>上的查詢根上使用。
var blogs = _context.Blog.FromSql("SELECT * FROM dbo.Blog").ToList();
原生SQL查詢可用於執行存儲過程。
var blogs = _context.Blog .FromSql("EXECUTE dbo.GetMostPopularBlogs") .ToList();
向原始SQL查詢引入任何用戶提供的值時,必須注意防範SQL注入攻擊。除了驗證確保此類值不包含無效字符,還要將值與SQL文本參數化處理。
下面的示例通過在SQL查詢字符串中包含形參佔位符並提供額外的實參,將單個形參傳遞到存儲過程。雖然此語法可能看上去像String.Format語法,但提供的值包裝在DbParameter中,且生成的參數名稱插入到指定{0}佔位符的位置。
var url = "http://blogs.msdn.com/webdev"; var blogs = _context.Blog .FromSql("EXECUTE dbo.GetMostPopularBlogForUrl {0}", url) .ToList();
SQL:
exec sp_executesql N'EXECUTE dbo.GetMostPopularBlogForUrl @p0 ',N'@p0 nvarchar(4000)',@p0=N'http://blogs.msdn.com/webdev'
SQL Server Profiler:
還可以構造DbParameter並將其作為參數值提供。由於使用了常規SQL參數佔位符而不是字符串佔位符,因此可安全地使用FromSql:
var urlParams = new SqlParameter("Url", "http://blogs.msdn.com/webdev"); var blogs = _context.Blog .FromSql("EXECUTE dbo.GetMostPopularBlogForUrl @Url", urlParams) .ToList();
SQL:
exec sp_executesql N'EXECUTE dbo.GetMostPopularBlogForUrl @Url ',N'@Url nvarchar(28)',@Url=N'http://blogs.msdn.com/webdev'
SQL Server Profiler:
可使用LINQ運算符在初始的原始SQL查詢基礎上進行組合。EF Core將其視為子查詢,並在數據庫中對其進行組合。下面的示例使用原始SQL查詢,該查詢從表值函數 (TVF) 中進行選擇。然後,使用LINQ進行篩選和排序,從而對其進行組合。
var searchTerm = "http://blogs.msdn.com/visualstudio"; var blogs = _context.Blog .FromSql($"SELECT * FROM dbo.Blog") .Where(b => b.Url == searchTerm) .Include(c=>c.Post) .OrderByDescending(b => b.Createtime) .ToList();
SQL:
exec sp_executesql N'SELECT [b].[BlogId], [b].[Createtime], [b].[Updatetime], [b].[Url] FROM ( SELECT * FROM dbo.Blog ) AS [b] WHERE [b].[Url] = @__searchTerm_1 ORDER BY [b].[Createtime] DESC, [b].[BlogId]',N'@__searchTerm_1 nvarchar(4000)',@__searchTerm_1=N'http://blogs.msdn.com/visualstudio' exec sp_executesql N'SELECT [b.Post].[PostId], [b.Post].[BlogId], [b.Post].[Content], [b.Post].[Title] FROM [Post] AS [b.Post] INNER JOIN ( SELECT [b0].[BlogId], [b0].[Createtime] FROM ( SELECT * FROM dbo.Blog ) AS [b0] WHERE [b0].[Url] = @__searchTerm_1 ) AS [t] ON [b.Post].[BlogId] = [t].[BlogId] ORDER BY [t].[Createtime] DESC, [t].[BlogId]',N'@__searchTerm_1 nvarchar(4000)',@__searchTerm_1=N'http://blogs.msdn.com/visualstudio'
SQL Server Profiler:
當在數據庫中執行查詢時,異步查詢可避免阻止線程。異步查詢對於在客戶端應用程序中保持響應式UI非常重要。 異步查詢還可以增加Web應用程序中的吞吐量,即通過釋放線程,以處理其他Web應用程序中的請求。
public async Task<IActionResult> Index() { var id1 = Thread.CurrentThread.ManagedThreadId.ToString(); var blogs = await _context.Blog.ToListAsync(); var id2 = Thread.CurrentThread.ManagedThreadId.ToString(); return View(blogs); }
當我們運行以上代碼時候,通過在關鍵字await上下文加入兩段獲取線程ID代碼,我們會看到如下結果:
看到兩段線程代碼輸出ID結果沒有?從上圖可以觀察到,當我們在進入某個視圖或者方法時候,執行到await某一個方法,當前線程不會一直等待下去,會立馬回收到線程池,供其他地方調用!當該await方法返回數據時候,才從線程池調用空閑線程執行await方法下文餘下的步驟。所以UI界面才不會進入假死狀態。
參考文獻:
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!
※幫你省時又省力,新北清潔一流服務好口碑
※別再煩惱如何寫文案,掌握八大原則!
摘錄自2019年12月2日世界新聞網報導
全球暖化和氣候變遷的影響已經成為國安問題,甚至被喻為將可能導致「第三次世界大戰」,前國務卿柯瑞(John Kerry)近日召集許多有影響力人士,如國會議員、軍事專家及好萊塢名人等,組成跨黨派聯盟——「第零次世界大戰」(World War Zero),聯合對抗氣候變遷。
該組織成員除了前總統柯林頓(Bill Clinton)和卡特(Jimmy Carter),也聚集許多好萊塢名人如影星李奧納多‧狄卡皮歐(Leonardo DiCaprio)、史汀(Sting)及艾希頓庫奇(Ashton Kutcher)等人;該組織成員目前約60人,目標是在明年募到超過1000萬元資金,並舉辦跨黨派的「氣候會談」。
柯瑞在1日連同組織成員之一,共和黨籍前加州州長阿諾‧史瓦辛格( Arnold Schwarzenegger),對於聯盟的成立發言表示:「沒有任何國家真正把事情做好,他們甚至把問題變得更糟,所以我們才召集這些人」。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想要讓你的商品成為最夯、最多人討論的話題?網頁設計公司讓你強力曝光
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!
※新北清潔公司,居家、辦公、裝潢細清專業服務