上文回顧
我們實現了根據搜索關鍵詞查詢商品列表和根據商品分類查詢,並且使用到了mybatis-pagehelper插件,講解了如何使用插件來幫助我們快速實現分頁數據查詢。本文我們將繼續開發商品詳情頁面和商品留言功能的開發。
需求分析
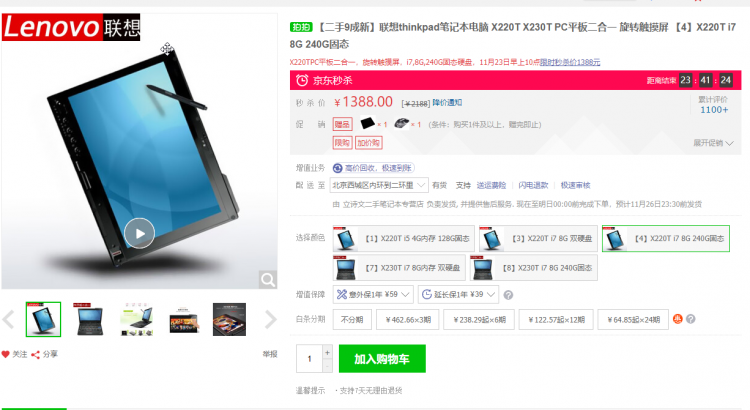
關於商品詳情頁,和往常一樣,我們先來看一看jd的示例:
從上面2張圖,我們可以看出來,大體上需要展示給用戶的信息。比如:商品圖片,名稱,價格,等等。在第二張圖中,我們還可以看到有一個商品評價頁簽,這些都是我們本節要實現的內容。
商品詳情
開發梳理
我們根據上圖(權當是需求文檔,很多需求文檔寫的比這個可能還差勁很多…)分析一下,我們的開發大致都要關注哪些points:
- 商品標題
- 商品圖片集合
- 商品價格(原價以及優惠價)
- 配送地址(我們的實現不在此,我們後續直接實現在下單邏輯中)
- 商品規格
- 商品分類
- 商品銷量
- 商品詳情
- 商品參數(生產場地,日期等等)
- …
根據我們梳理出來的信息,接下來開始編碼就會很簡單了,大家可以根據之前課程講解的,先自行實現一波,請開始你們的表演~
編碼實現
DTO實現
因為我們在實際的數據傳輸過程中,不可能直接把我們的數據庫entity之間暴露到前端,而且我們商品相關的數據是存儲在不同的數據表中,我們必須要封裝一個ResponseDTO來對數據進行傳遞。
ProductDetailResponseDTO包含了商品主表信息,以及圖片列表、商品規格(不同SKU)以及商品具體參數(產地,生產日期等信息)
@Data
@ToString
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class ProductDetailResponseDTO {
private Products products;
private List<ProductsImg> productsImgList;
private List<ProductsSpec> productsSpecList;
private ProductsParam productsParam;
}Custom Mapper實現
根據我們之前表的設計,這裏使用生成的通用mapper就可以滿足我們的需求。
Service實現
從我們封裝的要傳遞到前端的ProductDetailResponseDTO就可以看出,我們可以根據商品id分別查詢出商品的相關信息,在controller進行數據封裝就可以了,來實現我們的查詢接口。
-
查詢商品主表信息(名稱,內容等)
在
com.liferunner.service.IProductService中添加接口方法:/** * 根據商品id查詢商品 * * @param pid 商品id * @return 商品主信息 */ Products findProductByPid(String pid);接着,在
com.liferunner.service.impl.ProductServiceImpl中添加實現方法:@Override @Transactional(propagation = Propagation.SUPPORTS) public Products findProductByPid(String pid) { return this.productsMapper.selectByPrimaryKey(pid); }直接使用通用mapper根據主鍵查詢就可以了。
同上,我們依次來實現圖片、規格、以及商品參數相關的編碼工作
-
查詢商品圖片信息列表
/** * 根據商品id查詢商品規格 * * @param pid 商品id * @return 規格list */ List<ProductsSpec> getProductSpecsByPid(String pid); ---------------------------------------------------------------- @Override public List<ProductsSpec> getProductSpecsByPid(String pid) { Example example = new Example(ProductsSpec.class); val condition = example.createCriteria(); condition.andEqualTo("productId", pid); return this.productsSpecMapper.selectByExample(example); } -
查詢商品規格列表
/** * 根據商品id查詢商品規格 * * @param pid 商品id * @return 規格list */ List<ProductsSpec> getProductSpecsByPid(String pid); ------------------------------------------------------------------ @Override public List<ProductsSpec> getProductSpecsByPid(String pid) { Example example = new Example(ProductsSpec.class); val condition = example.createCriteria(); condition.andEqualTo("productId", pid); return this.productsSpecMapper.selectByExample(example); } -
查詢商品參數信息
/** * 根據商品id查詢商品參數 * * @param pid 商品id * @return 參數 */ ProductsParam findProductParamByPid(String pid); ------------------------------------------------------------------ @Override public ProductsParam findProductParamByPid(String pid) { Example example = new Example(ProductsParam.class); val condition = example.createCriteria(); condition.andEqualTo("productId", pid); return this.productsParamMapper.selectOneByExample(example); }
Controller實現
在上面將我們需要的信息查詢實現之後,然後我們需要在controller對數據進行包裝,之後再返回到前端,供用戶來進行查看,在com.liferunner.api.controller.ProductController中添加對外接口/detail/{pid},實現如下:
@GetMapping("/detail/{pid}")
@ApiOperation(value = "根據商品id查詢詳情", notes = "根據商品id查詢詳情")
public JsonResponse findProductDetailByPid(
@ApiParam(name = "pid", value = "商品id", required = true)
@PathVariable String pid) {
if (StringUtils.isBlank(pid)) {
return JsonResponse.errorMsg("商品id不能為空!");
}
val product = this.productService.findProductByPid(pid);
val productImgList = this.productService.getProductImgsByPid(pid);
val productSpecList = this.productService.getProductSpecsByPid(pid);
val productParam = this.productService.findProductParamByPid(pid);
val productDetailResponseDTO = ProductDetailResponseDTO
.builder()
.products(product)
.productsImgList(productImgList)
.productsSpecList(productSpecList)
.productsParam(productParam)
.build();
log.info("============查詢到商品詳情:{}==============", productDetailResponseDTO);
return JsonResponse.ok(productDetailResponseDTO);
}從上述代碼中可以看到,我們分別查詢了商品、圖片、規格以及參數信息,使用ProductDetailResponseDTO.builder().build()封裝成返回到前端的對象。
Test API
按照慣例,寫完代碼我們需要進行測試。
{
"status": 200,
"message": "OK",
"data": {
"products": {
"id": "smoke-100021",
"productName": "(奔跑的人生) - 中華",
"catId": 37,
"rootCatId": 1,
"sellCounts": 1003,
"onOffStatus": 1,
"createdTime": "2019-09-09T06:45:34.000+0000",
"updatedTime": "2019-09-09T06:45:38.000+0000",
"content": "吸煙有害健康“
},
"productsImgList": [
{
"id": "1",
"productId": "smoke-100021",
"url": "http://www.life-runner.com/product/smoke/img1.png",
"sort": 0,
"isMain": 1,
"createdTime": "2019-07-01T06:46:55.000+0000",
"updatedTime": "2019-07-01T06:47:02.000+0000"
},
{
"id": "2",
"productId": "smoke-100021",
"url": "http://www.life-runner.com/product/smoke/img2.png",
"sort": 1,
"isMain": 0,
"createdTime": "2019-07-01T06:46:55.000+0000",
"updatedTime": "2019-07-01T06:47:02.000+0000"
},
{
"id": "3",
"productId": "smoke-100021",
"url": "http://www.life-runner.com/product/smoke/img3.png",
"sort": 2,
"isMain": 0,
"createdTime": "2019-07-01T06:46:55.000+0000",
"updatedTime": "2019-07-01T06:47:02.000+0000"
}
],
"productsSpecList": [
{
"id": "1",
"productId": "smoke-100021",
"name": "中華",
"stock": 2276,
"discounts": 1.00,
"priceDiscount": 7000,
"priceNormal": 7000,
"createdTime": "2019-07-01T06:54:20.000+0000",
"updatedTime": "2019-07-01T06:54:28.000+0000"
},
],
"productsParam": {
"id": "1",
"productId": "smoke-100021",
"producPlace": "中國",
"footPeriod": "760天",
"brand": "中華",
"factoryName": "中華",
"factoryAddress": "陝西",
"packagingMethod": "盒裝",
"weight": "100g",
"storageMethod": "常溫",
"eatMethod": "",
"createdTime": "2019-05-01T09:38:30.000+0000",
"updatedTime": "2019-05-01T09:38:34.000+0000"
}
},
"ok": true
}商品評價
在文章一開始我們就看過jd詳情頁面,有一個詳情頁簽,我們來看一下:
它這個實現比較複雜,我們只實現相對重要的幾個就可以了。
開發梳理
針對上圖中紅色方框圈住的內容,分別有:
- 評價總數
- 好評度(根據好評總數,中評總數,差評總數計算得出)
- 評價等級
- 以及用戶信息加密展示
- 評價內容
- …
我們來實現上述分析的相對必要的一些內容。
編碼實現
查詢評價
根據我們需要的信息,我們需要從用戶表、商品表以及評價表中來聯合查詢數據,很明顯單表通用mapper無法實現,因此我們先來實現自定義查詢mapper,當然數據的傳輸對象是我們需要先來定義的。
Response DTO實現
創建com.liferunner.dto.ProductCommentDTO.
@Data
@NoArgsConstructor
@AllArgsConstructor
@Builder
public class ProductCommentDTO {
//評價等級
private Integer commentLevel;
//規格名稱
private String specName;
//評價內容
private String content;
//評價時間
private Date createdTime;
//用戶頭像
private String userFace;
//用戶昵稱
private String nickname;
}Custom Mapper實現
在com.liferunner.custom.ProductCustomMapper中添加查詢接口方法:
/***
* 根據商品id 和 評價等級查詢評價信息
* <code>
* Map<String, Object> paramMap = new HashMap<>();
* paramMap.put("productId", pid);
* paramMap.put("commentLevel", level);
*</code>
* @param paramMap
* @return java.util.List<com.liferunner.dto.ProductCommentDTO>
* @throws
*/
List<ProductCommentDTO> getProductCommentList(@Param("paramMap") Map<String, Object> paramMap);在mapper/custom/ProductCustomMapper.xml中實現該接口方法的SQL:
<select id="getProductCommentList" resultType="com.liferunner.dto.ProductCommentDTO" parameterType="Map">
SELECT
pc.comment_level as commentLevel,
pc.spec_name as specName,
pc.content as content,
pc.created_time as createdTime,
u.face as userFace,
u.nickname as nickname
FROM items_comments pc
LEFT JOIN users u
ON pc.user_id = u.id
WHERE pc.item_id = #{paramMap.productId}
<if test="paramMap.commentLevel != null and paramMap.commentLevel != ''">
AND pc.comment_level = #{paramMap.commentLevel}
</if>
</select>如果沒有傳遞評價級別的話,默認查詢全部評價信息。
Service 實現
在com.liferunner.service.IProductService中添加查詢接口方法:
/**
* 查詢商品評價
*
* @param pid 商品id
* @param level 評價級別
* @param pageNumber 當前頁碼
* @param pageSize 每頁展示多少條數據
* @return 通用分頁結果視圖
*/
CommonPagedResult getProductComments(String pid, Integer level, Integer pageNumber, Integer pageSize);在com.liferunner.service.impl.ProductServiceImpl實現該方法:
@Override
public CommonPagedResult getProductComments(String pid, Integer level, Integer pageNumber, Integer pageSize) {
Map<String, Object> paramMap = new HashMap<>();
paramMap.put("productId", pid);
paramMap.put("commentLevel", level);
// mybatis-pagehelper
PageHelper.startPage(pageNumber, pageSize);
val productCommentList = this.productCustomMapper.getProductCommentList(paramMap);
for (ProductCommentDTO item : productCommentList) {
item.setNickname(SecurityTools.HiddenPartString4SecurityDisplay(item.getNickname()));
}
// 獲取mybatis插件中獲取到信息
PageInfo<?> pageInfo = new PageInfo<>(productCommentList);
// 封裝為返回到前端分頁組件可識別的視圖
val commonPagedResult = CommonPagedResult.builder()
.pageNumber(pageNumber)
.rows(productCommentList)
.totalPage(pageInfo.getPages())
.records(pageInfo.getTotal())
.build();
return commonPagedResult;
}因為評價過多會使用到分頁,這裏使用通用分頁返回結果,關於分頁,可查看。
Controller實現
在com.liferunner.api.controller.ProductController中添加對外查詢接口:
@GetMapping("/comments")
@ApiOperation(value = "查詢商品評價", notes = "根據商品id查詢商品評價")
public JsonResponse getProductComment(
@ApiParam(name = "pid", value = "商品id", required = true)
@RequestParam String pid,
@ApiParam(name = "level", value = "評價級別", required = false, example = "0")
@RequestParam Integer level,
@ApiParam(name = "pageNumber", value = "當前頁碼", required = false, example = "1")
@RequestParam Integer pageNumber,
@ApiParam(name = "pageSize", value = "每頁展示記錄數", required = false, example = "10")
@RequestParam Integer pageSize
) {
if (StringUtils.isBlank(pid)) {
return JsonResponse.errorMsg("商品id不能為空!");
}
if (null == pageNumber || 0 == pageNumber) {
pageNumber = DEFAULT_PAGE_NUMBER;
}
if (null == pageSize || 0 == pageSize) {
pageSize = DEFAULT_PAGE_SIZE;
}
log.info("============查詢商品評價:{}==============", pid);
val productComments = this.productService.getProductComments(pid, level, pageNumber, pageSize);
return JsonResponse.ok(productComments);
}FBI WARNING:
@ApiParam(name = “level”, value = “評價級別”, required = false, example = “0”)
@RequestParam Integer level
關於ApiParam參數,如果接收參數為非字符串類型,一定要定義example為對應類型的示例值,否則Swagger在訪問過程中會報example轉換錯誤,因為example缺省為””空字符串,會轉換失敗。例如我們刪除掉level這個字段中的example=”0“,如下為錯誤信息(但是並不影響程序使用。)
2019-11-23 15:51:45 WARN AbstractSerializableParameter:421 - Illegal DefaultValue null for parameter type integer
java.lang.NumberFormatException: For input string: ""
at java.lang.NumberFormatException.forInputString(NumberFormatException.java:65)
at java.lang.Long.parseLong(Long.java:601)
at java.lang.Long.valueOf(Long.java:803)
at io.swagger.models.parameters.AbstractSerializableParameter.getExample(AbstractSerializableParameter.java:412)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at com.fasterxml.jackson.databind.ser.BeanPropertyWriter.serializeAsField(BeanPropertyWriter.java:688)
at com.fasterxml.jackson.databind.ser.std.BeanSerializerBase.serializeFields(BeanSerializerBase.java:721)
at com.fasterxml.jackson.databind.ser.BeanSerializer.serialize(BeanSerializer.java:166)
at com.fasterxml.jackson.databind.ser.impl.IndexedListSerializer.serializeContents(IndexedListSerializer.java:119)Test API
福利講解
添加Propagation.SUPPORTS和不加的區別
有心的小夥伴肯定又注意到了,在Service中處理查詢時,我一部分使用了@Transactional(propagation = Propagation.SUPPORTS),一部分查詢又沒有添加事務,那麼這兩種方式有什麼不一樣呢?接下來,我們來揭開神秘的面紗。
-
Propagation.SUPPORTS
/** * Support a current transaction, execute non-transactionally if none exists. * Analogous to EJB transaction attribute of the same name. * <p>Note: For transaction managers with transaction synchronization, * {@code SUPPORTS} is slightly different from no transaction at all, * as it defines a transaction scope that synchronization will apply for. * As a consequence, the same resources (JDBC Connection, Hibernate Session, etc) * will be shared for the entire specified scope. Note that this depends on * the actual synchronization configuration of the transaction manager. * @see org.springframework.transaction.support.AbstractPlatformTransactionManager#setTransactionSynchronization */ SUPPORTS(TransactionDefinition.PROPAGATION_SUPPORTS),主要關注
Support a current transaction, execute non-transactionally if none exists.從字面意思來看,就是如果當前環境有事務,我就加入到當前事務;如果沒有事務,我就以非事務的方式執行。從這方面來看,貌似我們加不加這一行其實都沒啥差別。划重點:NOTE,對於一個帶有事務同步的管理器來說,這裡有一丟丟的小區別啦。(所以大家在讀註釋的時候,一定要看這個Note.往往這裏面會有好東西給我們,就相當於我們的大喇叭!)
這個同步事務管理器定義了一個事務同步的一個範圍,如果加了這個註解,那麼就等同於我讓你來管我啦,你裏面的資源我想用就可以用(JDBC Connection, Hibernate Session).
結論1
SUPPORTS 標註的方法可以獲取和當前事務環境一致的 Connection 或 Session,不使用的話一定是一個新的連接;
再注意下面又一個NOTE,即便上面的配置加入了,但是事務管理器的實際同步配置會影響到真實的執行到底是否會用你。看它的說明:@see org.springframework.transaction.support.AbstractPlatformTransactionManager#setTransactionSynchronization.
/**
* Set when this transaction manager should activate the thread-bound
* transaction synchronization support. Default is "always".
* <p>Note that transaction synchronization isn't supported for
* multiple concurrent transactions by different transaction managers.
* Only one transaction manager is allowed to activate it at any time.
* @see #SYNCHRONIZATION_ALWAYS
* @see #SYNCHRONIZATION_ON_ACTUAL_TRANSACTION
* @see #SYNCHRONIZATION_NEVER
* @see TransactionSynchronizationManager
* @see TransactionSynchronization
*/
public final void setTransactionSynchronization(int transactionSynchronization) {
this.transactionSynchronization = transactionSynchronization;
}描述信息只是說在同一個事務管理器才能起作用,並沒有什麼實際意義,我們來看一下TransactionSynchronization具體的內容:
package org.springframework.transaction.support;
import java.io.Flushable;
public interface TransactionSynchronization extends Flushable {
/** Completion status in case of proper commit. */
int STATUS_COMMITTED = 0;
/** Completion status in case of proper rollback. */
int STATUS_ROLLED_BACK = 1;
/** Completion status in case of heuristic mixed completion or system errors. */
int STATUS_UNKNOWN = 2;
/**
* Suspend this synchronization.
* Supposed to unbind resources from TransactionSynchronizationManager if managing any.
* @see TransactionSynchronizationManager#unbindResource
*/
default void suspend() {
}
/**
* Resume this synchronization.
* Supposed to rebind resources to TransactionSynchronizationManager if managing any.
* @see TransactionSynchronizationManager#bindResource
*/
default void resume() {
}
/**
* Flush the underlying session to the datastore, if applicable:
* for example, a Hibernate/JPA session.
* @see org.springframework.transaction.TransactionStatus#flush()
*/
@Override
default void flush() {
}
/**
* ...
*/
default void beforeCommit(boolean readOnly) {
}
/**
* ...
*/
default void beforeCompletion() {
}
/**
* ...
*/
default void afterCommit() {
}
/**
* ...
*/
default void afterCompletion(int status) {
}
}事務管理器可以通過org.springframework.transaction.support.AbstractPlatformTransactionManager#setTransactionSynchronization(int)來對當前事務進行行為干預,比如將它設置為1,可以執行事務回調,設置為2,表示出錯了,但是如果沒有加入PROPAGATION.SUPPORTS註解的話,即便你在當前事務中,你也不能對我進行操作和變更。
結論2
添加
PROPAGATION.SUPPORTS之後,當前查詢中可以對當前的事務進行設置回調動作,不添加就不行。
源碼下載
下節預告
下一節我們將繼續開發商品詳情展示以及商品評價業務,在過程中使用到的任何開發組件,我都會通過專門的一節來進行介紹的,兄弟們末慌!
gogogo!
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!