說明:設計模式系列文章是讀劉偉所著《設計模式的藝術之道(軟件開發人員內功修鍊之道)》一書的閱讀筆記。個人感覺這本書講的不錯,有興趣推薦讀一讀。詳細內容也可以看看此書作者的博客https://blog.csdn.net/LoveLion/article/details/17517213
模式概述
絕大多數B/S系統都有一個首頁或者導航頁面,大部分C/S系統都提供了菜單或者工具欄,在這裏,首頁和導航頁面就充當了B/S系統的外觀角色,而菜單和工具欄充當了C/S系統的外觀角色,通過它們用戶可以快速訪問子系統,增強了軟件的易用性。
在軟件開發中,有時候為了完成一項較為複雜的功能,一個客戶類需要和多個業務類交互,而這些需要交互的業務類經常會作為一個整體出現,由於涉及到的類比較多,導致使用時代碼較為複雜,此時,特別需要一個類似服務員一樣的角色,由它來負責和多個業務類進行交互,而客戶類只需與該類交互。外觀模式通過引入一個外觀角色(Facade)來簡化客戶端與子系統(Subsystem)之間的交互,為複雜的子系統調用提供一個統一的入口,降低子系統與客戶端的耦合度,使得客戶端調用非常方便。
模式定義
外觀模式中,一個子系統的外部與其內部的通信通過一個統一的外觀類進行,外觀類將客戶類與子系統的內部複雜性分隔開,使得客戶類只需要與外觀角色打交道,而不需要與子系統內部的很多對象打交道。
外觀模式(
Facade Pattern):為子系統中的一組接口提供一個統一的入口。外觀模式定義了一個高層接口,這個接口使得這一子系統更加容易使用
外觀模式又稱為門面模式,它是一種對象結構型模式。外觀模式是迪米特法則的一種具體實現,通過引入一個新的外觀角色可以降低原有系統的複雜度,同時降低客戶類與子系統的耦合度。
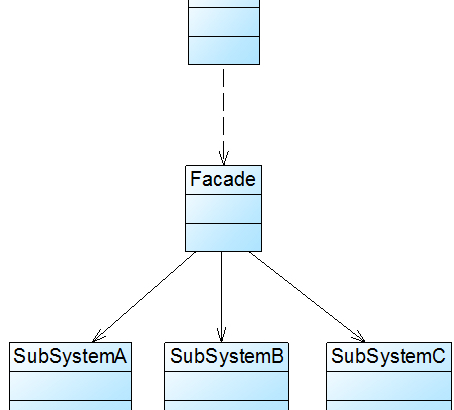
模式結構圖
外觀模式沒有一個一般化的類圖描述,下圖所示的類圖也可以作為描述外觀模式的結構圖:
外觀模式包含如下兩個角色:
-
Facade(外觀角色):在客戶端可以調用它的方法,在外觀角色中可以知道相關的(一個或者多個)子系統的功能和責任;在正常情況下,它將所有從客戶端發來的請求委派到相應的子系統去,傳遞給相應的子系統對象處理。
-
SubSystem(子系統角色):在軟件系統中可以有一個或者多個子系統角色,每一個子系統可以不是一個單獨的類,而是一個類的集合,它實現子系統的功能;每一個子系統都可以被客戶端直接調用,或者被外觀角色調用,它處理由外觀類傳過來的請求;子系統並不知道外觀的存在,對於子系統而言,外觀角色僅僅是另外一個客戶端而已。
模式偽代碼
外觀模式中所指的子系統是一個廣義的概念,它可以是一個類、一個功能模塊、系統的一個組成部分或者一個完整的系統。子系統類通常是一些業務類,實現了一些具體的、獨立的業務功能,其典型代碼如下:
public class SubSystemA {
public void methodA() {
//業務實現代碼
}
}
public class SubSystemB {
public void methodB() {
//業務實現代碼
}
}
public class SubSystemC {
public void methodC() {
//業務實現代碼
}
}
引入外觀類,與子系統業務類之間的交互統一由外觀類來完成
public class Facade {
private SubSystemA obj1 = new SubSystemA();
private SubSystemB obj2 = new SubSystemB();
private SubSystemC obj3 = new SubSystemC();
public void method() {
obj1.methodA();
obj2.methodB();
obj3.methodC();
}
}
由於在外觀類中維持了對子系統對象的引用,客戶端可以通過外觀類來間接調用子系統對象的業務方法,而無須與子系統對象直接交互。引入外觀類后,客戶端代碼變得非常簡單,典型代碼如下:
public static void main(String[] args) {
Facade facade = new Facade();
facade.method();
}
模式改進
在標準的外觀模式中,如果需要增加、刪除或更換與外觀類交互的子系統類,必須修改外觀類或客戶端的源代碼,這將違背開閉原則,因此可以通過引入抽象外觀類來對系統進行改進,在一定程度上可以解決該問題。在引入抽象外觀類之後,客戶端可以針對抽象外觀類進行編程,對於新的業務需求,不需要修改原有外觀類,而對應增加一個新的具體外觀類,由新的具體外觀類來關聯新的子系統對象。
定義抽象外觀類
public abstract class AbstractFacade {
public abstract void method();
}
根據具體的場景,實現具體的外觀類
public class Facade1 extends AbstractFacade {
private SubSystemA obj1 = new SubSystemA();
private SubSystemB obj2 = new SubSystemB();
@Override
public void method() {
obj1.methodA();
obj2.methodB();
}
}
public class Facade2 extends AbstractFacade {
private SubSystemB obj1 = new SubSystemB();
private SubSystemC obj2 = new SubSystemC();
@Override
public void method() {
obj1.methodB();
obj2.methodC();
}
}
客戶端針對抽象外觀類進行編程,代碼片段如下:
public static void main(String[] args) {
AbstractFacade facade = new Facade1();
// facade = new Facade2();
facade.method();
}
模式應用
個人認為外觀模式某些情況下可以看成是對既有系統的再次封裝,所以各種類庫、工具庫(比如hutool)、框架基本都有外觀模式的影子。外觀模式讓調用方更加簡潔,不用關心內部的實現,與此同時,也讓越來越多的程序猿多了個調包俠的昵稱(當然了這其中也包括筆者●´ω`●行無際)。
所以,你可能在很多開源代碼中看到類似XxxBootstrap、XxxContext、XxxMain等類似的Class,再追進去看一眼,你可能發現裏面關聯了一大堆的複雜的對象,這些對象對於外層調用者來說幾乎是透明的。
例子太多,以致於不知道舉啥例子(實際是偷懶的借口O(∩_∩)O哈哈~)。
模式總結
外觀模式並不給系統增加任何新功能,它僅僅是簡化調用接口。在幾乎所有的軟件中都能夠找到外觀模式的應用。所有涉及到與多個業務對象交互的場景都可以考慮使用外觀模式進行重構。
主要優點
(1) 它對客戶端屏蔽了子系統組件,減少了客戶端所需處理的對象數目,並使得子系統使用起來更加容易。通過引入外觀模式,客戶端代碼將變得很簡單,與之關聯的對象也很少。
(2) 它實現了子系統與客戶端之間的松耦合關係,這使得子系統的變化不會影響到調用它的客戶端,只需要調整外觀類即可。
(3) 一個子系統的修改對其他子系統沒有任何影響,而且子系統內部變化也不會影響到外觀對象。
適用場景
(1) 當要為訪問一系列複雜的子系統提供一個簡單入口時可以使用外觀模式。
(2) 客戶端程序與多個子系統之間存在很大的依賴性。引入外觀類可以將子系統與客戶端解耦,從而提高子系統的獨立性和可移植性。
(3) 在層次化結構中,可以使用外觀模式定義系統中每一層的入口,層與層之間不直接產生聯繫,而通過外觀類建立聯繫,降低層之間的耦合度。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!

 繼新北市電動機車 E-bike 於 10 月上路後,台北市政府也採用能源局補助業者研發旳氫燃料電池機車,每台配備 2 支金屬儲氫罐,交換費用 30 元,行駛中排水,但二氧化碳排放為 0,續航力定速時可達 86 公里,不過,若在行駛市區時,遇上紅綠燈走走停停,續航力會降為 50 公里。環保局表示,廠商提供試騎的 15 輛氫燃料電池機車將用於環保稽查、工地巡查、土地丈量等業務。 環保局表示,氫燃料電池首創用於機車,金屬容器包覆氫氧化物粉末,相較氣體狀較安全,業者提供的 15 部試騎機車將停於於市府公務停車場,也會提供交換氣體,試用 3 個月後評估成效。 負責研發的亞太燃料電池科技專案經理陳建豪表示,氣燃料電池不須充電,而是利用能源轉換,將氫氣透過觸媒轉換成電能,轉換過程僅會排放水,該款氫燃料電池機車時速最快可達 60 公里。業者說,量產後機車售價約 7 萬元,但免燃料稅。陳建豪表示,全球各國多有氫燃料電池的安全使用規範,但台灣沒有,盼政府能協助立法。 (Source:)
繼新北市電動機車 E-bike 於 10 月上路後,台北市政府也採用能源局補助業者研發旳氫燃料電池機車,每台配備 2 支金屬儲氫罐,交換費用 30 元,行駛中排水,但二氧化碳排放為 0,續航力定速時可達 86 公里,不過,若在行駛市區時,遇上紅綠燈走走停停,續航力會降為 50 公里。環保局表示,廠商提供試騎的 15 輛氫燃料電池機車將用於環保稽查、工地巡查、土地丈量等業務。 環保局表示,氫燃料電池首創用於機車,金屬容器包覆氫氧化物粉末,相較氣體狀較安全,業者提供的 15 部試騎機車將停於於市府公務停車場,也會提供交換氣體,試用 3 個月後評估成效。 負責研發的亞太燃料電池科技專案經理陳建豪表示,氣燃料電池不須充電,而是利用能源轉換,將氫氣透過觸媒轉換成電能,轉換過程僅會排放水,該款氫燃料電池機車時速最快可達 60 公里。業者說,量產後機車售價約 7 萬元,但免燃料稅。陳建豪表示,全球各國多有氫燃料電池的安全使用規範,但台灣沒有,盼政府能協助立法。 (Source:)