計算機相關專業初識–對於計算機相關專業我們在迷茫什麼
前言
由於種種原因,迫使我寫下這篇博客,我相信,初入計算機相關專業的萌新肯定很迷茫,我該學什麼,我該如何去學,我該如何學好等等問題纏繞心頭。有很多學弟學妹問我該如何去學計算機相關專業,作為過來人,我決定將我的所知所得寫下來,讓初入計算機相關專業的萌新的學習之路走得更順暢一些。
一、什麼是計算機
對於剛學習計算機相關專業的萌新來說,了解一下計算機的工作原理是十分必要的,但是在這裏我們不過多闡述,讓大家簡單了解一下就好。
讓我們先來看一下對於計算機名詞的解釋:
計算機(computer)俗稱電腦,是現代一種用於高速計算的电子計算機器,可以進行數值計算,又可以進行邏輯計算,還具有存儲記憶功能。是能夠按照程序運行,自動、高速處理海量數據的現代化智能电子設備。
划重點:
-
我們注意到,計算機就是一種用於進行數值計算的現代化智能电子設備。需要理解的是為什麼是進行數值計算,在這裏,你會疑惑,為什麼是數值計算呢,我輸入的明明不是数字呀?這個問題很容易解釋清楚,因為計算機只是一種电子設備,它不具有人類獨立思考和不斷學習的能力,它的所有功能都是事先設定好的,所以當計算機面對輸入字符的時候,會將它統一按照ASCII(計算機編碼系統)規則轉換為數值“0”和“1”(二進制數值),所以,在計算機里,數據存儲都是用“0”和“1”(即二進制數值)來實現。
-
還有一點值得注意,按照程序運行,那麼問題來了,程序是什麼?程序就是一組計算機能識別和執行的指令, 它以某些程序設計語言編寫,運行於某種目標結構體繫上 。舉個例子,程序就像是用英語(程序設計語言,例如c,c++)寫的文章,要讓一個懂的英語的人(編譯器,如C的編譯器gcc,這裏要注意編譯器和IDE的區別,通常IDE包含編譯器)同時也會閱讀這篇文章的人(結構體系)來閱讀、理解、標記這篇文章。
有學妹問過我,為什麼簡單的代碼,能實現豐富的效果。其實這取決於編譯器的強大能力。下面來簡單介紹一下,編輯器,編譯器,IDE(集成開發環境)的區別。
- 編輯器:編輯器就是用來編輯的軟件,比如windows自帶的記事本就是一個編輯器, 記事本沒有語法高亮,不显示行號,當一段可執行代碼寫完后無法通過內置環境執行,必須手動輸入命令執行編譯等等一些弊端,所以很少有程序員會用記事本去寫代碼 , 寫代碼比較好用的編輯器軟件有
vscode,vim,sublime,notepad++,emacs,atom等等 ,雖然編輯器原始功能不足,但是開發人員為了使編輯器更加友好,所以有很多內置插件可供使用,完全可以手動打造一個IDE。 - 編譯器:簡單來說,編譯器就是將“一種語言(一般為高級語言,如c,c++,java,python等,計算機不可直接識別和執行)”翻譯為“另一種語言(一般為低級語言,低級語言即機器語言,機器語言是用二進制代碼錶示的計算機能直接識別和執行的一種機器指令的集合)”的程序。舉個例子,用Dev-C++寫好一段可執行
"hello,world!"C語言代碼之後,我們要讓它在屏幕打印出來我們想要它輸出的"hello,world!",就需要通過gcc編譯器執行編譯后才能显示。其他語言同理。 - IDE:集成開發環境,用於程序開發環境的應用程序,一般包含代碼編輯器、編譯器、調試器、圖像用戶界面等工具。集成了代碼編寫、程序分析、程序編譯、程序調試等功能。如 jetbrains 的用於Java開發的 IntelliJ IDEA 、用於JavaScript開發的WebStorm、用於Python開發Pycharm,微軟的 Visual Studio系列 ,IBM的Eclipse。
二、我們該學什麼
很多初入計算機相關專業的萌新,總是很迷茫,不知道自己該學什麼,通常是他們知道如何去學好學校開設的每一門課程,就是不知道自己該向哪些方向學習,這些方向指的是專業技能和就業方向,諸如web開發、Android/IOS開發、數據分析、人工智能、網絡安全、遊戲開發、軟件測試等等。有這種疑惑很正常,迷茫也是正常的,但我們總要讓自己了解自己所需,然後腳踏實地,一步一步去充實自己的能力。而我想做的也很簡單,就是幫助大家解除心裏的疑惑。那麼,我們開始進入正題。
1. 我們該如何選擇適合自己的方向
對於這個問題,其實是很難回答清楚的,因為每個人的興趣都不相同,所以就很難去站在自己的角度去回答疑問者的問題。但是,原理都是想通的,我相信我的經驗會幫助到你們。
-
通常,學校每學期都會開設一門或多門語言(程序設計語言,下文同),那麼,喜歡一門語言,首先要愛上它的語言風格,諸如Java的嚴謹,Python的自由,總有一款適合你;其次,在學習語言的過程中,一定要了解它能幹什麼,市場環境如何,工作崗位多少等綜合因素,再決定要不要去深入這門語言,並且主攻自己感興趣的那個方向。
-
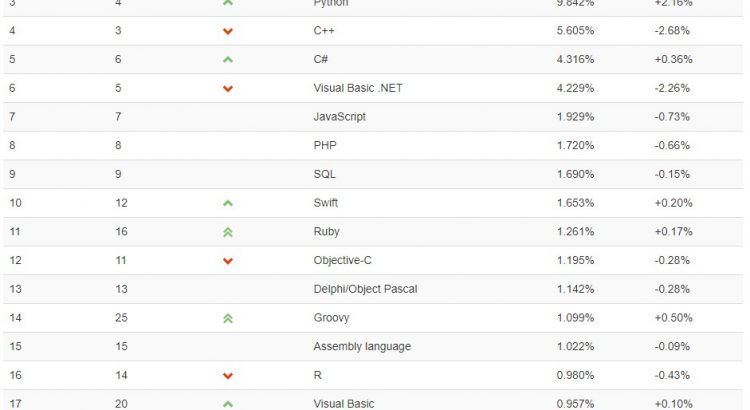
對於學校沒有開設,但是自己又想學習的語言而言,該如何去選擇。首先,學校開設的語言基本是市場比較流行的語言,也符合市場需求,所以,完全可以在學校開設的語言中去選擇自己想要了解並學習的語言。此外,我們可以藉助 TIOBE ( TIOBE 編程社區指數是編程語言流行度的指標,該榜單每月更新一次,指數基於全球技術工程師、課程和第三方供應商的數量。包括流行的搜索引擎,如谷歌、必應、雅虎、維基百科、亞馬遜、YouTube 和百度都用於指數計算。 )去了解語言的流行程度,流行程度決定市場需求,以此來參考自己想要了解並學習的語言,在此附上2019年11月語言排名。
2. 主流編程語言主要應用場景
-
Java
- 企業級應用開發: 大到全國聯網的系統,小到中小企業的應用解決方案,Java都佔有極為重要的地位 。
- web後端開發: JSP+Servlet+JavaBean 是一種比較流行的開發模式。
- 移動領域:手機遊戲。
- Android App開發: android 開發只用到了JAVA的語法和JAVA SE的一小部分API。
-
C
C語言是一門基礎語言,是其他一些語言的基礎,例如MATLAB,Object-C,Lua等.同時也是學習來比較難的語言,達到精通的程度沒有3-10年左右很難,C語言沒有比較完善的開發框架,是面向過程的一門語言,講究算法跟邏輯。
- 科研
- 服務器: 網絡核心設備,如路由器、交換機、防火牆。
- 操作系統:類unix系統(Linux/freebsd)
- 嵌入式開發: 在一個特定的硬件環境上開發與構建特定的可編程軟件系統的綜合技術。
- 自動化控制
-
Python
- 圖形處理
- 數學處理
- 文本處理
- 數據庫編程
- 網絡編程
- 多媒體應用
- pymo引擎: 運行於Symbian S60V3,Symbian S60V5,Symbian 3,Android,Windows,Linux,Mac Os,Maemo,MeeGo系統上的AVG遊戲引擎。
- 黑客編程
- 網絡安全
-
C++
- 遊戲開發
- 科學計算
- 網絡軟件
- 操作系統
- 設備驅動程序
- 移動設備
- 嵌入式開發
- 科研
- 編譯器
-
C#
- web後端開發
- 桌面軟件開發
- 人工智能
- 遊戲開發
- JavaScript
唯一能用於前後端開發的語言web前端開發- web前端開發
- node web後端開發
- 操作系統
- 後台
- 桌面軟件開發
- 混合App
- 小程序
-
PHP
- web後端開發
- 桌面軟件開發
- 命令行腳本
-
SQL
- 操作數據庫
-
Swift
- 蘋果生態系統應用開發
-
Ruby
- web開發
-
R
數據科學闖天下,左手Python右手R
- 機器學習
- 數據分析
- 科學計算
-
Go
- web後端開發
- 高性能服務器應用
3. 主流編程語言學習路徑(將持續更新,僅供參考)
- JavaScript
4. 主流編程語言入門學習書籍推薦
| 語言 | 書籍 |
|---|---|
| C | 《嗨翻C語言》 |
| C++ | 《C++權威教程》 |
| Java | 《Java輕鬆學》 |
| Python | 《Python編程從入門到實戰》 |
| JavaScript | 《JavaScript入門經典》 |
| PHP | 《PHP編程實戰》 |
| SQL | 《SQL基礎教程》 |
| Swift | 《Swift編程權威指南》 |
| Ruby | 《Ruby從入門到精通》 |
| R | 《R語言實戰》 |
| Go | 《Go語言聖經》 |
5. 編程學習網站推薦
| 網站 | 網址 |
|---|---|
| 菜鳥教程 | |
| W3School | |
| 實驗樓 | |
| 猿學 | |
| 慕課網 | |
| SegmentFault | |
| 博客園 | |
| GitHub | |
| 掘金 | |
| 學習數據科學 | |
| 易百教程 | |
| 看雲 |
三、總結
通篇寫完,感覺自己也重新學到了很多,學習就是一個反覆複習的過程,每次學習都能帶給自己不一樣的收穫。希望以上內容可以給初入計算機相關專業的萌新帶來一些幫助,後面我會不斷更新和優化本文,請大家持續關注。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※想知道網站建置、網站改版該如何進行嗎?將由專業工程師為您規劃客製化網頁設計及後台網頁設計
※不管是台北網頁設計公司、台中網頁設計公司,全省皆有專員為您服務
※Google地圖已可更新顯示潭子電動車充電站設置地點!!